本文闡述如何利用 HTMLParser 項目對 Html 或者 WML 文檔中出現的一些特殊的或者是自定義的標簽進行處理。
HTMLParser 是一個用來解析 HTML 文檔的開放源碼項目,它具有小巧、快速、使用簡單的特點以及擁有強大的功能。對該項目還不了解的朋友可以參照 2004 年三月份我發表的文章--《從HTML中攫取你所需的信息》,這篇文章介紹如何通過 HTMLParser 來提取 Html 文檔中的文本數據以及提取出文檔中的所有鏈接或者是圖片等信息。
現在該項目的最新版本是 Integration Build 1.6,與之前版本的差別在於代碼結構的調整、當然也有一些功能的提升以及 BugFix,同時對字符集的處理也更加自動了。比較遺憾的該項目並沒有詳盡的使用文檔,你只能借助於它的 API 文檔、一兩個簡單例子以及源碼來熟悉它。
如果是 HTML 文檔,那麼用 HTMLParser 已經差不多可以滿足你至少 90% 的需求。一個 HTML 文檔中可能出現的標簽差不多在 HTMLParser 中都有對應的類,甚至包括一些動態的腳本標簽,例如 <%...%> 這種 JSP 和 ASP 用到的標簽都有相應的 JSPTag 對應。HTMLParser 的強大功能還體現在你可以修改每個標簽的屬性或者它所包含的文本內容並生成新的 HTML 文檔,比如你可以文檔中的鏈接地址偷偷的改成你自己的地址等等。關於 HtmlParser 的強大功能,其實上一篇文章已經介紹很多,這裡不再累贅,我們今天要講的是另外一個用途--處理自定義標簽。
首先我們先解釋一下什麼叫自定義標簽,我把所有不是 HTML 腳本語言中定義的標簽稱之為自定義標簽,比如可以是 <scriptlet>、<book> 等等,這是我們自己創造出來的標簽。你可能會很奇怪,因為這些標簽一旦用在 HTML 文檔中是沒有任何效果的,那麼我們換另外一個例子,假如你要解析的不是 HTML 文檔,而是一個 WML(Wireless Markup Lauguage)文檔呢?WML 文檔中的 card,anchor 等標簽 HTMLParser 是沒有現成的標簽類來處理的。還有就是你同樣可以用 HtmlParser 來處理 XML 文檔,而 XML 文檔中所有的標簽都是你自己定義的。
為了使我們的例子更具有代表意義,接下來我們將給出一段代碼用來解析出 WML 文檔中的所有鏈接,了解 WML 文檔的人都知道,WML 文檔中除了與 Html 文檔相同的鏈接寫法外,還多了一種標簽叫 <anchor>,例如在一個 WML 文檔我們可以用下面兩種方式來表示一個鏈接。
<a href="http://www.javayou.com?cat_id=1">Java自由人</a>
或者:
<anchor>
Java自由人
</go>
</anchor>
(更多的時候使用 anchor 的鏈接用來提交一個表單。) 如果我們還是使用 LinkTag 來遍歷整個 WML 文檔的話,那 Anchor 中的鏈接將會被我們所忽略掉。
下面我們先給出一個簡單的例子,然後再敘述其中的道理。這個例子包含兩個文件,一個是WML 的測試腳本文件 test.wml,另外一個是 Java 程序文件 HyperLinkTrace.Java,內容如下:
1. test.wml
<?XML version="1.0"?>
<!DOCTYPE wml PUBLIC "-//WAPFORUM//DTD WML 1.1//EN"
"http://www.wapforum.org/DTD/wml_1.1.XML">
<wml>
<card title="Java自由人登錄">
<p>
</p>
</card>
</wml>
test.wml 中的粗體部分是我們需要提取出來的鏈接。
2. HyperLinkTrace.Java
package demo.Htmlparser;
import Java.io.BufferedReader;
import Java.io.File;
import Java.io.FileReader;
import Java.Net.URL;
import org.Htmlparser.Node;
import org.Htmlparser.NodeFilter;
import org.Htmlparser.Parser;
import org.Htmlparser.PrototypicalNodeFactory;
import org.Htmlparser.tags.CompositeTag;
import org.Htmlparser.tags.LinkTag;
import org.Htmlparser.util.NodeList;
public class HyperLinkTrace {
}
上面這段代碼比較長,可以分成下面幾部分來看:
1. getWmlContent方法: 該方法用來獲取在同一個包中的test.wml腳本文件的內容並返回字符串。
2. 靜態屬性lnkFilter:這是一個NodeFilter的匿名類所構造的實例。該實例用來傳遞給HtmlParser告知需要提取哪些節點。在這個例子中我們僅需要提取鏈接標簽以及我們自定義的一個GO標簽。
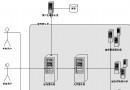
3. 嵌套類WmlGoTag:這也是最為重要的一部分,這個類用來告訴HTMLParser如何去解析<go>這樣一個節點。我們先看看下面這個HtmlParser的節點類層次圖:
如上圖所示,HTMLParser將一個文檔分成三種節點分別是:Remark(注釋);Text(文本);Tag(標簽)。而標簽又分成兩種分別是簡單標簽(Tag)和復合標簽(CompositeTag),像<img><br/>這種標簽稱為簡單標簽,因為標簽不會再包含其它內容。而像<a href="xxxx">Home</a>這種類型的標簽,因為標簽會嵌套文本或者其他標簽的稱為復合標簽,也就是對應著CompositeTag這個類。簡單標簽的實現類很簡單,只需要擴展Tag類並覆蓋getIds方法以返回標簽的識別文本,例如<img>標簽應該返回包含"img"字符串的數組,具體的代碼可以參考HtmlParser自帶的ImageTag標簽類的實現。
從上圖可清楚看出,復合標簽事實上是對簡單標簽的擴展,HTMLParser在處理一個復合標簽時需要知道該標簽的起始標識以及結束標識,也就是我們在前面給出的源碼中的兩個方法getIds和getEnders,一般來講,標簽出現都是成對的,因此這兩個方法一般返回相同的值。另外一個方法getEndTagEnders,這個方法用來返回父一級的標簽名稱,例如<tr>的父一級標簽應該是<table>。這個方法的必要性在於HTML對格式的要求很不嚴格,在很多的HTML文檔中的一些標簽經常是有開始標識,但是沒有結束標識,由於浏覽器的超強適應能力使這種情況出現的很頻繁,因此HtmlParser利用這個方法來輔助判斷一個標簽是否已經結束。由於WML文檔的格式要求非常嚴格,因此上例源碼中的getEndTagEnders方法事實上可有可無。
4. 入口方法main:該方法初始化HtmlParser並注冊新的節點解析器,解析文檔並打印運行結果。
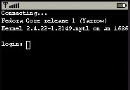
最後我們編譯並運行這個例子,便可以得到下面的運行結果:
GO:
LINK:
HTMLParser本身就是一個開放源碼的項目,它對於Html文檔中出現的標簽定義已經應有盡有,我們盡可以參考這些標簽解析類的源碼來學習如何實現一個標簽的解析類,從而擴展出更豐富多彩的應用程序。