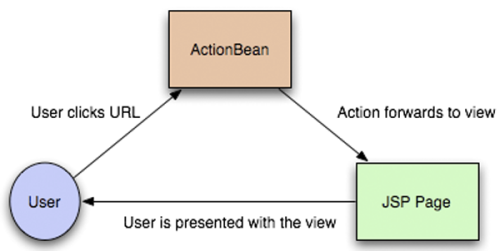
J2ME中的數據結構大多都用輕量級的Hashtable和Vector,這裡和大家分享一下它們的具體用法,當需要往Hashtable中裝入很多實體時,創建一個合適大容量的Hashtable實例比讓實例去自動增加來容量來適應要在性能上高的多。
J2ME中的Hashtable和Vector
J2ME中的數據結構大多都用輕量級的Hashtable和Vector.
1.Hashtable
ME版本的Hashtable和SE版本的最大的區別是泛型的支持,前者本身不支持泛型。但是也有些細微的差別。
Hashtable(以下都是指ME版本的Hashtable)將鍵(key)映射到值(value)上。任何非空(non-null)的對象都可以被用作一個key或者作為一個值。
Hashtable實例有兩個參數影響其效率:容量和裝載因子。裝載因子在CLDC實現中始終是75%(而在其它版本中這個值是可以指定的)。當Hashtable中包含的實體數超過裝載因子和當前容量的一個結合值(這可能通過相應的算法得出)時,就通過調用rehash方法來增加容量。
當需要往Hashtable中裝入很多實體時,創建一個合適大容量的Hashtable實例比讓實例去自動增加來容量來適應要在性能上高的多。
2.Vector
Vector類實現了一個可增的對象數組。像數組一樣,它包含的組件可以用整數索引(下表)來訪問。因此,當Vector創建之後,一個Vector的大小可以隨著增加或者移除元素操作而增大或者減小。
每個Vector試著通過維持一個容量(capacity)和一個容量增量(capacityIncrement)來優化存儲管理。容量總是至少跟Vector的大小(size)一樣大;它通常都會大一些,因為組件會被加進到Vector中,Vector的存儲大小會以capacityIncrement塊大小來增加。應用程序可以在插入大量組件之前對Vector容量進行增加;這樣做可以降低增加性重新分配的數量。
數據結構中我們學習過鏈表、數組、樹等諸多數據結構。Hashtable就是一種底層由鏈表實現的數據結構,所以它擁有鏈表數據結構的優缺點。而Vector由數據結構比較特殊的數組來實現,同樣擁有了數組的優缺點,不同的時,由於在數組基礎之上增加的可變的操作,這樣一定程度上降低了它的效率。不過Vector的效率據說還是相當高的。