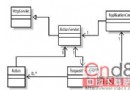
Java代碼如下:
代碼如下:
package com.gjob.common;
public class URLtoUTF8 {
//轉換為%E4%BD%A0形式
public static String toUtf8String(String s) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c >= 0 && c <= 255) {
sb.append(c);
} else {
byte[] b;
try {
b = String.valueOf(c).getBytes("utf-8");
} catch (Exception ex) {
System.out.println(ex);
b = new byte[0];
}
for (int j = 0; j < b.length; j++) {
int k = b[j];
if (k < 0)
k += 256;
sb.append("%" + Integer.toHexString(k).toUpperCase());
}
}
}
return sb.toString();
}
//將%E4%BD%A0轉換為漢字
public static String unescape(String s) {
StringBuffer sbuf = new StringBuffer();
int l = s.length();
int ch = -1;
int b, sumb = 0;
for (int i = 0, more = -1; i < l; i++) {
/* Get next byte b from URL segment s */
switch (ch = s.charAt(i)) {
case '%':
ch = s.charAt(++i);
int hb = (Character.isDigit((char) ch) ? ch - '0'
: 10 + Character.toLowerCase((char) ch) - 'a') & 0xF;
ch = s.charAt(++i);
int lb = (Character.isDigit((char) ch) ? ch - '0'
: 10 + Character.toLowerCase((char) ch) - 'a') & 0xF;
b = (hb << 4) | lb;
break;
case '+':
b = ' ';
break;
default:
b = ch;
}
/* Decode byte b as UTF-8, sumb collects incomplete chars */
if ((b & 0xc0) == 0x80) { // 10xxxxxx (continuation byte)
sumb = (sumb << 6) | (b & 0x3f); // Add 6 bits to sumb
if (--more == 0)
sbuf.append((char) sumb); // Add char to sbuf
} else if ((b & 0x80) == 0x00) { // 0xxxxxxx (yields 7 bits)
sbuf.append((char) b); // Store in sbuf
} else if ((b & 0xe0) == 0xc0) { // 110xxxxx (yields 5 bits)
sumb = b & 0x1f;
more = 1; // Expect 1 more byte
} else if ((b & 0xf0) == 0xe0) { // 1110xxxx (yields 4 bits)
sumb = b & 0x0f;
more = 2; // Expect 2 more bytes
} else if ((b & 0xf8) == 0xf0) { // 11110xxx (yields 3 bits)
sumb = b & 0x07;
more = 3; // Expect 3 more bytes
} else if ((b & 0xfc) == 0xf8) { // 111110xx (yields 2 bits)
sumb = b & 0x03;
more = 4; // Expect 4 more bytes
} else /*if ((b & 0xfe) == 0xfc)*/{ // 1111110x (yields 1 bit)
sumb = b & 0x01;
more = 5; // Expect 5 more bytes
}
/* We don't test if the UTF-8 encoding is well-formed */
}
return sbuf.toString();
}
public static void main(String[] args){
System.out.println(URLtoUTF8.toUtf8String("你"));
System.out.println(URLtoUTF8.unescape("%E4%BD%A0%20%E5%A5%BD"));
}
}
############
運行結果:
%E4%BD%A0
你 好