Java中的集合主要集中在2部分,一部分是java.util包中,一部分是java.util.concurrent中,後者是在前者的基礎上,定義了一些實現了同步功能的集合。
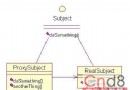
這篇文章主要關注java.util下的各種集合對象。Java中的集合對象可以粗略的分為3類:List、Set和Map。對應的UML圖如下(包括了java.util下大部分的集合對象):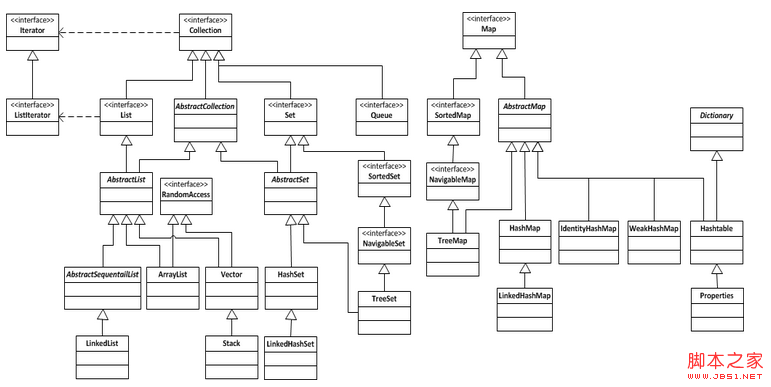
Collection概述
Java集合中的List和Set都從Collection出來,它是一個學習集合很不錯的入口,它包含了集合中通常需要有的操作:
添加元素:add/addAll
清空集合:clear
刪除元素:remove/removeAll
判斷集合中是否包含某元素:contains/containsAll
判斷集合是否為空:isEmpty
計算集合中元素的個數:size
將集合轉換為數組:toArray
獲取迭代器:iterator
我們來看一個簡單的例子,下面的代碼會返回一個集合,集合中的元素是隨機生成的整數:
代碼如下:
private static Collection initCollection()
{
Collection<Integer> collection = new ArrayList<Integer>();
Random r = new Random();
for (int i = 0 ; i < 5; i++)
{
collection.add(new Integer(r.nextInt(100)));
}
return collection;
}
在對集合進行操作的過程中,遍歷是一個經常使用的操作,我們可以使用兩種方式對集合進行遍歷:
1) 使用迭代器對集合進行遍歷。正如上面描述Collection接口時所說,所有集合都會有一個迭代器,我們可以用它來遍歷集合。
代碼如下:
private static void accessCollectionByIterator(Collection<Integer> collection)
{
Iterator<Integer> iterator = collection.iterator();
System.out.println("The value in the list:");
while(iterator.hasNext())
{
System.out.println(iterator.next());
}
}
2)使用foreach遍歷集合。
代碼如下:
private static void accessCollectionByFor(Collection<Integer> collection)
{
System.out.println("The value in the list:");
for(Integer value : collection)
{
System.out.println(value);
}
}
List
Java中的List是對數組的有效擴展,它是這樣一種結構,如果不使用泛型,它可以容納任何類型的元素,如果使用泛型,那麼它只能容納泛型指定的類型的元素。和數組相比,List的容量是可以動態擴展的。
List中的元素是可以重復的,裡面的元素是“有序”的,這裡的“有序”,並不是排序的意思,而是說我們可以對某個元素在集合中的位置進行指定。
List中常用的集合對象包括:ArrayList、Vector和LinkedList,其中前兩者是基於數組來進行存儲,後者是基於鏈表進行存儲。其中Vector是線程安全的,其余兩個不是線程安全的。
List中是可以包括null的,即使是使用了泛型。
ArrayList可能是我們平時用到的最多的集合對象了,在上述的示例代碼中,我們也是使用它來實例化一個Collection對象,在此不再贅述。
Vector
Vector的示例如下,首先我們看如何生成和輸出Vector:
代碼如下:
private static void vectorTest1()
{
List<Integer> list = new Vector<Integer>();
for (int i = 0 ; i < 5; i++)
{
list.add(new Integer(100));
}
list.add(null);
System.out.println("size of vector is " + list.size());
System.out.println(list);
}
它的元素中,既包括了重復元素,也包括了null,輸出結果如下:
代碼如下:
size of vector is 6
[100, 100, 100, 100, 100, null]
下面的示例,演示了Vector中的一些常用方法:
代碼如下:
private static void vectorTest2()
{
Vector<Integer> list = new Vector<Integer>();
Random r = new Random();
for (int i = 0 ; i < 10; i++)
{
list.add(new Integer(r.nextInt(100)));
}
System.out.println("size of vector is " + list.size());
System.out.println(list);
System.out.println(list.firstElement());
System.out.println(list.lastElement());
System.out.println(list.subList(3, 8));
List<Integer> temp = new ArrayList<Integer>();
for(int i = 4; i < 7; i++)
{
temp.add(list.get(i));
}
list.retainAll(temp);
System.out.println("size of vector is " + list.size());
System.out.println(list);
}
它的輸出結果如下:
代碼如下:
size of vector is 10
[39, 41, 20, 9, 29, 32, 54, 12, 94, 82]
[9, 29, 32, 54, 12]
size of vector is 3
[29, 32, 54]
LinkedList
LinkedList使用鏈表來存儲數據,它的示例代碼如下:
代碼如下:
LinkedList示例
private static void linkedListTest1()
{
LinkedList<Integer> list = new LinkedList<Integer>();
Random r = new Random();
for (int i = 0 ; i < 10; i++)
{
list.add(new Integer(r.nextInt(100)));
}
list.add(null);
System.out.println("size of linked list is " + list.size());
System.out.println(list);
System.out.println(list.element());
System.out.println(list.getFirst());
System.out.println(list.getLast());
System.out.println(list.peek());
System.out.println(list.peekFirst());
System.out.println(list.peekLast());
System.out.println(list.poll());
System.out.println(list.pollFirst());
System.out.println(list.pollLast());
System.out.println(list.pop());
list.push(new Integer(100));
System.out.println("size of linked list is " + list.size());
System.out.println(list);
}
這裡列出了LinkedList常用的各個方法,從方法名可以看出,LinkedList也可以用來實現棧和隊列。
輸出結果如下:
代碼如下:
size of linked list is 11
[17, 21, 5, 84, 19, 57, 68, 26, 27, 47, null]
null
null
null
size of linked list is 8
[100, 84, 19, 57, 68, 26, 27, 47]
Set
Set 和List類似,都是用來存儲單個元素,單個元素的數量不確定。但Set不能包含重復元素,如果向Set中插入兩個相同元素,那麼後一個元素不會被插入。
Set可以大致分為兩類:不排序Set和排序Set,不排序Set包括HashSet和LinkedHashSet,排序Set主要指TreeSet。其中HashSet和LinkedHashSet可以包含null。
HashSet
HashSet是由Hash表支持的一種集合,它不是線程安全的。
我們來看下面的示例,它和Vector的第一個示例基本上是相同的:
代碼如下:
private static void hashSetTest1()
{
Set<Integer> set = new HashSet<Integer>();
for (int i = 0; i < 3; i++)
{
set.add(new Integer(100));
}
set.add(null);
System.out.println("size of set is " + set.size());
System.out.println(set);
}
這裡,HashSet中既包含了重復元素,又包含了null,和Vector不同,這裡的輸出結果如下:
代碼如下:
size of set is 2
[null, 100]
對於HashSet是如何判斷兩個元素是否是重復的,我們可以深入考察一下。Object中也定義了equals方法,對於HashSet中的元素,它是根據equals方法來判斷元素是否相等的,為了證明這一點,我們可以定義個“不正常”的類型:
代碼如下:
定義MyInteger對象
class MyInteger
{
private Integer value;
public MyInteger(Integer value)
{
this.value = value;
}
public String toString()
{
return String.valueOf(value);
}
public int hashCode()
{
return 1;
}
public boolean equals(Object obj)
{
return true;
}
}
可以看到,對於MyInteger來說,對於任意兩個實例,我們都認為它是不相等的。
下面是對應的測試方法:
代碼如下:
private static void hashSetTest2()
{
Set<MyInteger> set = new HashSet<MyInteger>();
for (int i = 0; i < 3; i++)
{
set.add(new MyInteger(100));
}
System.out.println("size of set is " + set.size());
System.out.println(set);
}
它的輸出結果如下:
代碼如下:
size of set is 3
[100, 100, 100]
可以看到,現在HashSet裡有“重復”元素了,但對於MyInteger來說,它們不是“相同”的。
TreeSet
TreeSet是支持排序的一種Set,它的父接口是SortedSet。
我們首先來看一下TreeSet都有哪些基本操作:
代碼如下:
private static void treeSetTest1()
{
TreeSet<Integer> set = new TreeSet<Integer>();
Random r = new Random();
for (int i = 0 ; i < 5; i++)
{
set.add(new Integer(r.nextInt(100)));
}
System.out.println(set);
System.out.println(set.first());
System.out.println(set.last());
System.out.println(set.descendingSet());
System.out.println(set.headSet(new Integer(50)));
System.out.println(set.tailSet(new Integer(50)));
System.out.println(set.subSet(30, 60));
System.out.println(set.floor(50));
System.out.println(set.ceiling(50));
}
它的輸出結果如下:
代碼如下:
[8, 42, 48, 49, 53]
[53, 49, 48, 42, 8]
[8, 42, 48, 49]
[53]
[42, 48, 49, 53]
TreeSet中的元素,一般都實現了Comparable接口,默認情況下,對於Integer來說,SortedList是采用升序來存儲的,我們也可以自定義Compare方式,例如以降序的方式來存儲。
下面,我們首先重新定義Integer:
代碼如下:
定義MyInteger2對象
class MyInteger2 implements Comparable
{
public int value;
public MyInteger2(int value)
{
this.value = value;
}
public int compareTo(Object arg0)
{
MyInteger2 temp = (MyInteger2)arg0;
if (temp == null) return -1;
if (temp.value > this.value)
{
return 1;
}
else if (temp.value < this.value)
{
return -1;
}
return 0;
}
public boolean equals(Object obj)
{
return compareTo(obj) == 0;
}
public String toString()
{
return String.valueOf(value);
}
}
下面是測試代碼:
代碼如下:
private static void treeSetTest2()
{
TreeSet<Integer> set1 = new TreeSet<Integer>();
TreeSet<MyInteger2> set2 = new TreeSet<MyInteger2>();
Random r = new Random();
for (int i = 0 ; i < 5; i++)
{
int value = r.nextInt(100);
set1.add(new Integer(value));
set2.add(new MyInteger2(value));
}
System.out.println("Set1 as below:");
System.out.println(set1);
System.out.println("Set2 as below:");
System.out.println(set2);
}
代碼的運行結果如我們所預期的那樣,如下所示:
代碼如下:
Set1 as below:
[13, 41, 42, 45, 61]
Set2 as below:
[61, 45, 42, 41, 13]
Map
Map中存儲的是“鍵值對”,和Set類似,Java中的Map也有兩種:排序的和不排序的,不排序的包括HashMap、Hashtable和LinkedHashMap,排序的包括TreeMap。
非排序Map
HashMap和Hashtable都是采取Hash表的方式進行存儲,HashMap不是線程安全的,Hashtable是線程安全的,我們可以把HashMap看做是“簡化”版的Hashtable。
HashMap是可以存儲null的,無論是對Key還是對Value。Hashtable是不可以存儲null的。
無論HashMap還是Hashtable,我們觀察它的構造函數,就會發現它可以有兩個參數:initialCapacity和loadFactor,默認情況下,initialCapacity等於16,loadFactor等於0.75。這和Hash表中可以存放的元素數目有關系,當元素數目超過initialCapacity*loadFactor時,會觸發rehash方法,對hash表進行擴容。如果我們需要向其中插入過多元素,需要適當調整這兩個參數。
我們首先來看HashMap的示例:
代碼如下:
private static void hashMapTest1()
{
Map<Integer,String> map = new HashMap<Integer, String>();
map.put(new Integer(1), "a");
map.put(new Integer(2), "b");
map.put(new Integer(3), "c");
System.out.println(map);
System.out.println(map.entrySet());
System.out.println(map.keySet());
System.out.println(map.values());
}
這會輸出HashMap裡的元素信息,如下所示。
代碼如下:
{1=a, 2=b, 3=c}
[1=a, 2=b, 3=c]
[1, 2, 3]
[a, b, c]
下面的示例是對null的演示:
代碼如下:
private static void hashMapTest2()
{
Map<Integer,String> map = new HashMap<Integer, String>();
map.put(null, null);
map.put(null, null);
map.put(new Integer(4), null);
map.put(new Integer(5), null);
System.out.println(map);
System.out.println(map.entrySet());
System.out.println(map.keySet());
System.out.println(map.values());
}
執行結果如下:
代碼如下:
{null=null, 4=null, 5=null}
[null=null, 4=null, 5=null]
[null, 4, 5]
[null, null, null]
接下來我們演示Hashtable,和上述兩個示例基本上完全一樣(代碼不再展開):
代碼如下:
Hashtable示例
private static void hashTableTest1()
{
Map<Integer,String> table = new Hashtable<Integer, String>();
table.put(new Integer(1), "a");
table.put(new Integer(2), "b");
table.put(new Integer(3), "c");
System.out.println(table);
System.out.println(table.entrySet());
System.out.println(table.keySet());
System.out.println(table.values());
}
private static void hashTableTest2()
{
Map<Integer,String> table = new Hashtable<Integer, String>();
table.put(null, null);
table.put(null, null);
table.put(new Integer(4), null);
table.put(new Integer(5), null);
System.out.println(table);
System.out.println(table.entrySet());
System.out.println(table.keySet());
System.out.println(table.values());
}
執行結果如下:
代碼如下:
{3=c, 2=b, 1=a}
[3=c, 2=b, 1=a]
[3, 2, 1]
[c, b, a]
Exception in thread "main" java.lang.NullPointerException
at java.util.Hashtable.put(Unknown Source)
at sample.collections.MapSample.hashTableTest2(MapSample.java:61)
at sample.collections.MapSample.main(MapSample.java:11)
可以很清楚的看到,當我們試圖將null插入到hashtable中時,報出了空指針異常。
排序Map
排序Map主要是指TreeMap,它對元素增、刪、查操作時的時間復雜度都是O(log(n))。它不是線程安全的。
它的特點和TreeSet非常像,這裡不再贅述。