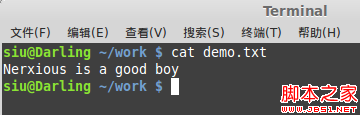
1,什麼是字符編碼?
字符(Character)是文字與符號的總稱,包括文字、圖形符號、數學符號等。一組抽象字符的集合就是字符集(Charset)。字符集的出現是為了信息進行傳播儲存提供方便。目前常用到字符集有:ASCII,ISO 8859-1,Unicode,GB2312
2,各種編碼集有哪些特點?
ASCII:
ASCII(American Standard Code for Information Interchange,美國信息交換標准代碼)是基於拉丁字母的一套電腦編碼系統。
包含內容:控制字符(回車,退格,換行鍵),可顯示式字符(英文大小寫,阿拉伯數字和西文符號)。
技術特征:7位(bits)表示一個字符,共128字符
不足之處:只能表示英語,想西歐,東亞和拉美地區的語言符號無法表示。
ISO 8859-1:
ISO 8859-1,正式編號為ISO/IEC 8859-1:1998,又稱Latin-1或“西歐語言”,是國際標准化組織內ISO/IEC 8859的第一個8位字符集。
它以ASCII為基礎,在空置的0xA0-0xFF的范圍內,加入96個字母及符號,藉以供使用附加符號的拉丁字母語言使用。曾推出過 ISO 8859-1:1987 版。
包含內容:ASCII編碼包含的,部分西歐使用的語言。
技術特征:8位表示一個字符。
Unicode:
Unicode字符集編碼是Universal Multiple-Octet Coded Character Set 通用多八位編碼字符集的簡稱,是由一個名為 Unicode 學術學會(Unicode Consortium)的機構制訂的字符編碼系統,支持現今世界各種不同語言的書面文本的交換、處理及顯示。該編碼於1990年開始研發,1994年正式公布,最新版本是2005年3月31日的Unicode 4.1.0。
技術特征:16位編碼,每個字符占用2個字節。一個字符的Unicode編碼是確定的。但是在實際傳輸過程中,由於不同系統平台的設計不一定一致,以及出於節省空間的目的,對Unicode編碼的實現方式有所不同。Unicode的實現方式稱為Unicode轉換格式(Unicode Transformation Format,簡稱為UTF)。如果一個7位的ASCII字符的Unicode文件,在傳輸過程中如果使用2個字節的原Unicode編碼傳輸會造成比較大的浪費。對於這種情況,可以使用UTF-8編碼,這是一種變長編碼,它將基本7位ASCII字符仍用7位編碼表示,占用一個字節(首位補0)。而遇到與其他Unicode字符混合的情況,將按一定算法轉換,每個字符使用1-3個字節編碼,並利用首位為0或1進行識別。
GB2312:
GB 2312 或 GB 2312-80 是中國國家標准簡體中文字符集,全稱《信息交換用漢字編碼字符集·基本集》,又稱GB0,由中國國家標准總局發布,1981年5月1日實施。GB2312編碼通行於中國大陸;新加坡等地也采用此編碼。中國大陸幾乎所有的中文系統和國際化的軟件都支持GB 2312。
包含內容:6763個漢字,其中一級漢字3755個,二級漢字3008個;同時收錄了包括拉丁字母、希臘字母、日文平假名及片假名字母、俄語西裡爾字母在內的682個字符。
技術特征:每個漢字及符號以兩個字節來表示。第一個字節稱為“高位字節”,第二個字節稱為“低位字節”。“高位字節”使用了0xA1-0xF7,“低位字節”使用了0xA1-0xFE0xA0)。 由於一級漢字從16區起始,漢字區的“高位字節”的范圍是0xB0-0xF7,“低位字節”的范圍是0xA1-0xFE,占用的碼位是72*94=6768。其中有5個空位是D7FA-D7FE。