DOM初步
DOM是Document Object Model的縮寫,即文檔對象模型。前面說過,XML將數據組織為一顆樹,所以DOM就是對這顆樹的一個對象描敘。通俗的說,就是通過解析XML文檔,為XML文檔在邏輯上建立一個樹模型,樹的節點是一個個對象。我們通過存取這些對象就能夠存取XML文檔的內容。
下面我們來看一個簡單的例子,看看在DOM中,我們是如何來操作一個XML文檔的。
這是一個XML文檔,也是我們要操作的對象:
<?xml version="1.0" encoding="UTF-8"?><messages><message>Good-bye serialization, hello Java!</message></messages>
下面,我們需要把這個文檔的內容解析到一個個的Java對象中去供程序使用,利用JAXP,我們只需幾行代碼就能做到這一點。首先,我們需要建立一個解析器工廠,以利用這個工廠來獲得一個具體的解析器對象:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
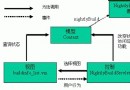
我們在這裡使用DocumentBuilderFacotry的目的是為了創建與具體解析器無關的程序,當DocumentBuilderFactory類的靜態方法newInstance()被調用時,它根據一個系統變量來決定具體使用哪一個解析器。又因為所有的解析器都服從於JAXP所定義的接口,所以無論具體使用哪一個解析器,代碼都是一樣的。所以當在不同的解析器之間進行切換時,只需要更改系統變量的值,而不用更改任何代碼。這就是工廠所帶來的好處。這個工廠模式的具體實現,可以參看下面的類圖。
DocumentBuilder db = dbf.newDocumentBuilder();
當獲得一個工廠對象後,使用它的靜態方法newDocumentBuilder()方法可以獲得一個DocumentBuilder對象,這個對象代表了具體的DOM解析器。但具體是哪一種解析器,微軟的或者IBM的,對於程序而言並不重要。
然後,我們就可以利用這個解析器來對XML文檔進行解析了:
Document doc = db.parse("c:/xml/message.xml");
DocumentBuilder的parse()方法接受一個XML文檔名作為輸入參數,返回一個Document對象,這個Document對象就代表了一個XML文檔的樹模型。以後所有的對XML文檔的操作,都與解析器無關,直接在這個Document對象上進行操作就可以了。而具體對Document操作的方法,就是由DOM所定義的了。
Jaxp支持W3C所推薦的DOM 2。如果你對DOM很熟悉,那麼下面的內容就很簡單了:只需要按照DOM的規范來進行方法調用就可以。當然,如果你對DOM不清楚,也不用著急,後面我們會有詳細的介紹。在這兒,你所要知道並牢記的是:DOM是用來描敘XML文檔中的數據的模型,引入DOM的全部原因就是為了用這個模型來操作XML文檔的中的數據。DOM規范中定義有節點(即對象)、屬性和方法,我們通過這些節點的存取來存取XML的數據。
從上面得到的Document對象開始,我們就可以開始我們的DOM之旅了。使用Document對象的getElementsByTagName()方法,我們可以得到一個NodeList對象,一個Node對象代表了一個XML文檔中的一個標簽元素,而NodeList對象,觀其名而知其意,所代表的是一個Node對象的列表:
NodeList nl = doc.getElementsByTagName("message");
我們通過這樣一條語句所得到的是XML文檔中所有<message>標簽對應的Node對象的一個列表。然後,我們可以使用NodeList對象的item()方法來得到列表中的每一個Node對象:
Node my_node = nl.item(0);
當一個Node對象被建立之後,保存在XML文檔中的數據就被提取出來並封裝在這個Node中了。在這個例子中,要提取Message標簽內的內容,我們通常會使用Node對象的getNodeValue()方法:
String message = my_node.getFirstChild().getNodeValue();
請注意,這裡還使用了一個getFirstChild()方法來獲得message下面的第一個子Node對象。雖然在message標簽下面除了文本外並沒有其它子標簽或者屬性,但是我們堅持在這裡使用getFirseChild()方法,這主要和W3C對DOM的定義有關。W3C把標簽內的文本部分也定義成一個Node,所以先要得到代表文本的那個Node,我們才能夠使用getNodeValue()來獲取文本的內容。
現在,既然我們已經能夠從XML文件中提取出數據了,我們就可以把這些數據用在合適的地方,來構築應用程序。
下面的內容,我們將更多的關注DOM,為DOM作一個較為詳細的解析,使我們使用起來更為得心應手。
DOM詳解
1.基本的DOM對象
DOM的基本對象有5個:Document,Node,NodeList,Element和Attr。下面就這些對象的功能和實現的方法作一個大致的介紹。
Document對象代表了整個XML的文檔,所有其它的Node,都以一定的順序包含在Document對象之內,排列成一個樹形的結構,程序員可以通過遍歷這顆樹來得到XML文檔的所有的內容,這也是對XML文檔操作的起點。我們總是先通過解析XML源文件而得到一個Document對象,然後再來執行後續的操作。此外,Document還包含了創建其它節點的方法,比如createAttribut()用來創建一個Attr對象。它所包含的主要的方法有:
createAttribute(String):用給定的屬性名創建一個Attr對象,並可在其後使用setAttributeNode方法來放置在某一個Element對象上面。
createElement(String):用給定的標簽名創建一個Element對象,代表XML文檔中的一個標簽,然後就可以在這個Element對象上添加屬性或進行其它的操作。
createTextNode(String):用給定的字符串創建一個Text對象,Text對象代表了標簽或者屬性中所包含的純文本字符串。如果在一個標簽內沒有其它的標簽,那麼標簽內的文本所代表的Text對象是這個Element對象的唯一子對象。
getElementsByTagName(String):返回一個NodeList對象,它包含了所有給定標簽名字的標簽。
getDocumentElement():返回一個代表這個DOM樹的根節點的Element對象,也就是代表XML文檔根元素的那個對象。
Node對象是DOM結構中最為基本的對象,代表了文檔樹中的一個抽象的節點。在實際使用的時候,很少會真正的用到Node這個對象,而是用到諸如Element、Attr、Text等Node對象的子對象來操作文檔。Node對象為這些對象提供了一個抽象的、公共的根。雖然在Node對象中定義了對其子節點進行存取的方法,但是有一些Node子對象,比如Text對象,它並不存在子節點,這一點是要注意的。Node對象所包含的主要的方法有: