摘 要 Java規則引擎是一種嵌入在Java程序中的組件,它的任務是把當前提交給引擎的Java數據對象與加載在引擎中的業務規則進行測試和比對,激活那些符合當前數據狀態下的業務規則,根據業務規則中聲明的執行邏輯,觸發應用程序中對應的操作。
引言
目前,Java社區推動並發展了一種引人注目的新技術——Java規則引擎(Rule Engine)。利用它就可以在應用系統中分離商業決策者的商業決策邏輯和應用開發者的技術決策,並把這些商業決策放在中心數據庫或其他統一的地方,讓它們能在運行時可以動態地治理和修改,從而為企業保持靈活性和競爭力提供有效的技術支持。
規則引擎的原理
1、基於規則的專家系統(RBES)簡介
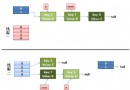
Java規則引擎起源於基於規則的專家系統,而基於規則的專家系統又是專家系統的其中一個分支。專家系統屬於人工智能的范疇,它模擬人類的推理方式,使用試探性的方法進行推理,並使用人類能理解的術語解釋和證實它的推理結論。為了更深入地了解Java規則引擎,下面簡要地介紹基於規則的專家系統。RBES包括三部分:Rule Base(knowledge base)、Working Memory(fact base)和Inference Engine。它們的結構如下系統所示:

圖1 基於規則的專家系統構成
如圖1所示,推理引擎包括三部分:模式匹配器(Pattern Matcher)、議程(Agenda)和執行引擎(Execution Engine)。推理引擎通過決定哪些規則滿足事實或目標,並授予規則優先級,滿足事實或目標的規則被加入議程。模式匹配器決定選擇執行哪個規則,何時執行規則;議程治理模式匹配器挑選出來的規則的執行次序;執行引擎負責執行規則和其他動作。
和人類的思維相對應,推理引擎存在兩者推理方式:演繹法(Forward-Chaining)和歸納法(Backward-Chaining)。演繹法從一個初始的事實出發,不斷地應用規則得出結論(或執行指定的動作)。而歸納法則是根據假設,不斷地尋找符合假設的事實。Rete算法是目前效率最高的一個Forward-Chaining推理算法,許多Java規則引擎都是基於Rete算法來進行推理計算的。
推理引擎的推理步驟如下:
(1)將初始數據(fact)輸入Working Memory。
(2)使用Pattern Matcher比較規則庫(rule base)中的規則(rule)和數據(fact)。
(3)假如執行規則存在沖突(conflict),即同時激活了多個規則,將沖突的規則放入沖突集合。
(4)解決沖突,將激活的規則按順序放入Agenda。
(5)使用執行引擎執行Agenda中的規則。重復步驟2至5,直到執行完畢所有Agenda中的規則。
上述即是規則引擎的原始架構,Java規則引擎就是從這一原始架構演變而來的。
2、規則引擎相關構件
規則引擎是一種根據規則中包含的指定過濾條件,判定其能否匹配運行時刻的實時條件來執行規則中所規定的動作的引擎。與規則引擎相關的有四個基本概念,為更好地理解規則引擎的工作原理,下面將對這些概念進行逐一介紹。
1)信息元(Information Unit)
信息元是規則引擎的基本建築塊,它是一個包含了特定事件的所有信息的對象。這些信息包括:消息、產生事件的應用程序標識、事件產生事件、信息元類型、相關規則集、通用方法、通用屬性以及一些系統相關信息等等。
2)信息服務(Information Services)
信息服務產生信息元對象。每個信息服務產生它自己類型相對應的信息元對象。即特定信息服務根據信息元所產生每個信息元對象有相同的格式,但可以有不同的屬性和規則集。需要注重的是,在一台機器上可以運行許多不同的信息服務,還可以運行同一信息服務的不同實例。但無論如何,每個信息服務只產生它自己類型相對應的信息元。
3)規則集(Rule Set)
顧名思義,規則集就是許多規則的集合。每條規則包含一個條件過濾器和多個動作。一個條件過濾器可以包含多個過濾條件。條件過濾器是多個布爾表達式的組合,其組合結果仍然是一個布爾類型的。在程序運行時,動作將會在條件過濾器值為真的情況下執行。除了一般的執行動作,還有三類比較非凡的動作,它們分別是:放棄動作(Discard Action)、包含動作(Include Action)和使信息元對象內容持久化的動作。前兩種動作類型的區別將在2.3規則引擎工作機制小節介紹。
4)隊列治理器(Queue Manager)
隊列治理器用來治理來自不同信息服務的信息元對象的隊列。
下面將研究規則引擎的這些相關構件是如何協同工作的。
如圖2所示,處理過程分為四個階段進行:信息服務接受事件並將其轉化為信息元,然後這些信息元被傳給隊列治理器,最後規則引擎接收這些信息元並應用它們自身攜帶的規則加以執行,直到隊列治理器中不再有信息元。