由於Java編程中的中文問題是一個老生常談的問題,在閱讀了許多關於Java中文問題解決方法之後,結合作者的編程實踐,我發現過去談的許多方法都不能清晰地說明問題及解決問題,尤其是跨平台時的中文問題。於是我給出此篇文章,內容包括對控制台運行的class、Servelets、JSP及EJB類中的中文問題我剖析和建議解決辦法。希望大家指教。
Abstract:本文深入分析了Java程序設計中Java編譯器對java源文件和JVM對class類文件的編碼/解碼過程,通過此過程的解析透視出了Java編程中中文問題產生的根本原因,最後給出了建議的最優化的解決Java中文問題的方法。
1、中文問題的來源
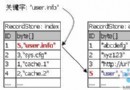
計算機最初的操作系統支持的編碼是單字節的字符編碼,於是,在計算機中一切處理程序最初都是以單字節編碼的英文為准進行處理。隨著計算機的發展,為了適應世界其它民族的語言(當然包括我們的漢字),人們提出了UNICODE編碼,它采用雙字節編碼,兼容英文字符和其它民族的雙字節字符編碼,所以,目前,大多數國際性的軟件內部均采用UNICODE編碼,在軟件運行時,它獲得本地支持系統(多數時間是操作系統)默認支持的編碼格式,然後再將軟件內部的UNICODE轉化為本地系統默認支持的格式顯示出來。Java的JDK和JVM即是如此,我這裡說的JDK是指國際版的JDK,我們大多數程序員使用的是國際化的JDK版本,以下所有的JDK均指國際化的JDK版本。我們的漢字是雙字節編碼語言,為了能讓計算機處理中文,我們自己制定的gb2312、GBK、GBK2K等標准以適應計算機處理的需求。所以,大部分的操作系統為了適應我們處理中文的需求,均定制有中文操作系統,它們采用的是GBK,GB2312編碼格式以正確顯示我們的漢字。如:中文Win2K默認采用的是GBK編碼顯示,在中文WIN2k中保存文件時默認采用的保存文件的編碼格式也是GBK的,即,所有在中文WIN2K中保存的文件它的內部編碼默認均采用GBK編碼,注意:GBK是在GB2312基礎上擴充來的。
由於Java語言內部采用UNICODE編碼,所以在JAVA程序運行時,就存在著一個從UNICODE編碼和對應的操作系統及浏覽器支持的編碼格式轉換輸入、輸出的問題,這個轉換過程有著一系列的步驟,如果其中任何一步出錯,則顯示出來的漢字就會出是亂碼,這就是我們常見的JAVA中文問題。
同時,Java是一個跨平台的編程語言,也即我們編寫的程序不僅能在中文windows上運行,也能在中文Linux等系統上運行,同時也要求能在英文等系統上運行(我們經常看到有人把在中文win2k上編寫的JAVA程序,移植到英文Linux上運行)。這種移植操作也會帶來中文問題。
還有,有人使用英文的操作系統和英文的IE等浏覽器,來運行帶中文字符的程序和浏覽中文網頁,它們本身就不支持中文,也會帶來中文問題。
幾乎所有的浏覽器默認在傳遞參數時都是以UTF-8編碼格式來傳遞,而不是按中文編碼傳遞,所以,傳遞中文參數時也會有問題,從而帶來亂碼現象。
總之,以上幾個方面是JAVA中的中文問題的主要來源,我們把以上原因造成的程序不能正確運行而產生的問題稱作:JAVA中文問題。
2、JAVA編碼轉換的詳細過程
我們常見的JAVA程序包括以下類別:
*直接在console上運行的類(包括可視化界面的類)
*JSP代碼類(注:JSP是Servlets類的變型)
*Servelets類
*EJB類
*其它不可以直接運行的支持類
這些類文件中,都有可能含有中文字符串,並且我們常用前三類JAVA程序和用戶直接交互,用於輸出和輸入字符,如:我們在JSP和Servlet中得到客戶端送來的字符,這些字符也包括中文字符。無論這些JAVA類的作用如何,這些JAVA程序的生命周期都是這樣的:
*編程人員在一定的操作系統上選擇一個合適的編輯軟件來實現源程序代碼並以.java擴展名保存在操作系統中,例如我們在中文win2k中用記事本編輯一個java源程序;
*編程人員用JDK中的javac.exe來編譯這些源代碼,形成.class類(JSP文件是由容器調用JDK來編譯的);
*直接運行這些類或將這些類布署到WEB容器中去運行,並輸出結果。
那麼,在這些過程中,JDK和JVM是如何將這些文件如何編碼和解碼並運行的呢?