摘要 J2EE應用程序中的業務組件通常使用JDBC API訪問和更改關系數據庫中的持久數據。這經常導致持久性代碼與業務邏輯發生混合,這是一種不好的習慣。數據訪問對象(DAO)設計模式通過把持久性邏輯分成若干數據訪問類來解決這一問題。
本文是一篇關於DAO設計模式的入門文章,突出講述了它的優點和不足之處。另外,本文還介紹了Spring 2.0 JDBC/DAO框架並示范了它如何妥善地解決傳統DAO設計中的缺陷。
傳統的DAO設計
數據訪問對象(DAO)是一個集成層設計模式,如Core J2EE Design Pattern 圖書所歸納。它將持久性存儲訪問和操作代碼封裝到一個單獨的層中。本文的上下文中所提到的持久存儲器是一個RDBMS.
這一模式在業務邏輯層和持久存儲層之間引入了一個抽象層,如圖1所示。業務對象通過數據訪問對象來訪問RDBMS(數據源)。抽象層改善了應用程序代碼並引入了靈活性。理論上,當數據源改變時,比如更換數據庫供給商或是數據庫的類型時,僅需改變數據訪問對象,從而把對業務對象的影響降到最低。
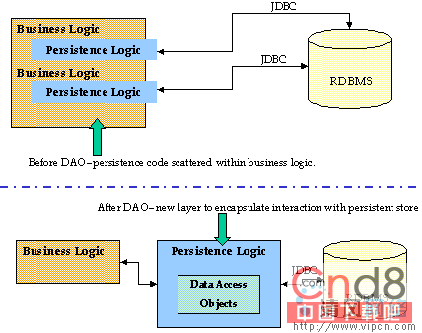
圖1. 應用程序結構,包括DAO之前和之後的部分
講解了DAO設計模式的基礎知識,下面將編寫一些代碼。下面的例子來自於一個公司域模型。簡而言之,這家公司有幾位員工工作在不同的部門,如銷售部、市場部以及人力資源部。為了簡單起見,我們將集中討論一個稱作“雇員”的實體。
針對接口編程
DAO設計模式帶來的靈活性首先要歸功於一個對象設計的最佳實踐:針對接口編程(P2I)。這一原則規定實體必須實現一個供調用程序而不是實體自身使用的接口。因此,可以輕松替換成不同的實現而對客戶端代碼只產生很小的影響。
我們將據此使用findBySalaryRange()行為定義Employee DAO接口,IEmployeeDAO.業務組件將通過這個接口與DAO交互:
import Java.util.Map;
public interface IEmployeeDAO {
//SQL String that will be executed
public String FIND_BY_SAL_RNG = "SELECT EMP_NO, EMP_NAME, "
+ "SALARY FROM EMP WHERE SALARY >= ? AND SALARY <= ?";
//Returns the list of employees who fall into the given salary
//range. The input parameter is the immutable map object
//oBTained from the HttpServletRequest. This is an early
//refactoring based on "IntrodUCe Parameter Object"
public List findBySalaryRange(Map salaryMap);
}
提供DAO實現類
接口已經定義,現在必須提供Employee DAO的具體實現,EmployeeDAOImpl:
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.List;
import java.util.ArrayList;
import java.util.Map;
import com.bea.dev2dev.to.EmployeeTO;
public class EmployeeDAOImpl implements IEmployeeDAO{
public List findBySalaryRange(Map salaryMap)
{
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
List empList = new ArrayList();
//Transfer Object for inter-tier data transfer
EmployeeTO tempEmpTO = null;
try{
//DBUtil - helper classes that retrieve connection from pool
conn = DBUtil.getConnection();
pstmt = conn.prepareStatement(FIND_BY_SAL_RNG);
pstmt.setDouble(1, Double.valueOf( (String)
salaryMap.get("MIN_SALARY") );
pstmt.setDouble(2, Double.valueOf( (String)
salaryMap.get("MIN_SALARY") );
rs = pstmt.executeQuery();
int tmpEmpNo = 0;
String tmpEmpName = "";
double tmpSalary = 0.0D;
while (rs.next()){
tmpEmpNo = rs.getInt("EMP_NO");
tmpEmpName = rs.getString("EMP_NAME");
tmpSalary = rs.getDouble("SALARY");
tempEmpTO = new EmployeeTO(tmpEmpNo,
tmpEmpName,
tmpSalary);
empList.add(tempEmpTO);
}//end while
}//end try
catch (SQLException sqle){
throw new DBException(sqle);
}//end catch
finally{
try{
if (rs != null){
rs.close();
}
}
catch (SQLException sqle){
throw new DBException(sqle);
}
try{
if (pstmt != null){
pstmt.close();
}
}
catch (SQLException sqle){
throw new DBException(sqle);
}
try{
if (conn != null){
conn.close();
}
}
catch (SQLException sqle){
throw new DBException(sqle);
}
}//end of finally block
return empList;
}//end method findBySalaryRange
}
上面的清單說明了DAO方法的一些要點:
它們封裝了所有與JDBC API的交互。假如使用像Kodo或者Hibernate的O/R映射方案,則DAO類可以將這些產品的私有API打包。
它們將檢索到的數據打包到一個與JDBC API無關的傳輸對象中,然後將其返回給業務層作進一步處理。
它們實質上是無狀態的。唯一的目的是訪問並更改業務對象的持久數據。
在這個過程中,它們像SQLException一樣捕捉任何底層JDBC API或數據庫報告的錯誤(例如,數據庫不可用、錯誤的SQL句法)。DAO對象再次使用一個與JDBC無關的自定義運行時異常類DBException,通知業務對象這些錯誤。
它們像Connection和PreparedStatement對象那樣,將數據庫資源釋放回池中,並在使用完ResultSet游標之後,將其所占用的內存釋放。
因此,DAO層將底層的數據訪問API抽象化,為業務層提供了一致的數據訪問API.
構建DAO工廠
DAO工廠是典型的工廠設計模式實現,用於為業務對象創建和提供具體的DAO實現。業務對象使用DAO接口,而不用了解實現類的具體情況。DAO工廠帶來的依靠反轉(dependency inversion)提供了極大的靈活性。只要DAO接口建立的約定未改變,那麼很輕易改變DAO實現(例如,從straight JDBC實現到基於Kodo的O/R映射),同時又不影響客戶的業務對象:
public class DAOFactory {
private static DAOFactory daoFac;
static{
daoFac = new DAOFactory();
}
private DAOFactory(){}
public DAOFactory getInstance(){
return daoFac;
}
public IEmployeeDAO getEmployeeDAO(){
return new EmployeeDAOImpl();
}
}
與業務組件的協作
現在該了解DAO怎樣適應更復雜的情形。如前幾節所述,DAO與業務層組件協作獲取和更改持久業務數據。下面的清單展示了業務服務組件及其與DAO層的交互:
public class EmployeeBusinessServiceImpl implements
IEmployeeBusinessService {
public List getEmployeesWithinSalaryRange(Map salaryMap){
IEmployeeDAO empDAO = DAOFactory.getInstance()
.getEmployeeDAO();
List empList = empDAO.findBySalaryRange(salaryMap);
return empList;
}
}
交互過程十分簡潔,完全不依靠於任何持久性接口(包括JDBC)。
問題
DAO設計模式也有缺點:
代碼重復:從EmployeeDAOImpl清單可以清楚地看到,對於基於JDBC的傳統數據庫訪問,代碼重復(如上面的粗體字所示)是一個主要的問題。一遍又一遍地寫著同樣的代碼,明顯違反了基本的面向對象設計的代碼重用原則。它將對項目成本、時間安排和工作產生明顯的副面影響。
耦合:DAO代碼與JDBC接口和核心collection耦合得非常緊密。從每個DAO類的導入聲明的數量可以明顯地看出這種耦合。
資源耗損:依據EmployeeDAOImpl類的設計,所有DAO方法必須釋放對所獲得的連接、聲明、結果集等數據庫資源的控制。這是危險的主張,因為一個編程新手可能很輕易漏掉那些約束。結果造成資源耗盡,導致系統停機。
錯誤處理:JDBC驅動程序通過拋出SQLException來報告所有的錯誤情況。SQLException是檢查到的異常,所以開發人員被迫去處理它,即使不可能從這類導致代碼混亂的大多數異常中恢復過來。而且,從SQLException對象獲得的錯誤代碼和消息特定於數據庫廠商,所以不可能寫出可移植的DAO錯誤發送代碼。
脆弱的代碼:在基於JDBC的DAO中,兩個常用的任務是設置聲明對象的綁定變量和使用結果集檢索數據。假如SQL where子句中的列數目或者位置更改了,就不得不對代碼執行更改、測試、重新部署這個嚴格的循環過程。
讓我們看看如何能夠減少這些問題並保留DAO的大多數優點。
進入Spring DAO
先識別代碼中發生變化的部分,然後將這一部分代碼分離出來或者封裝起來,就能解決以上所列出的問題。Spring的設計者們已經完全做到了這一點,他們發布了一個超級簡潔、健壯的、高度可伸縮的JDBC框架。固定部分(像檢索連接、預備聲明對象、執行查詢和釋放數據庫資源)已經被一次性地寫好,所以該框架的一部分內容有助於消除在傳統的基於JDBC的DAO中出現的缺點。
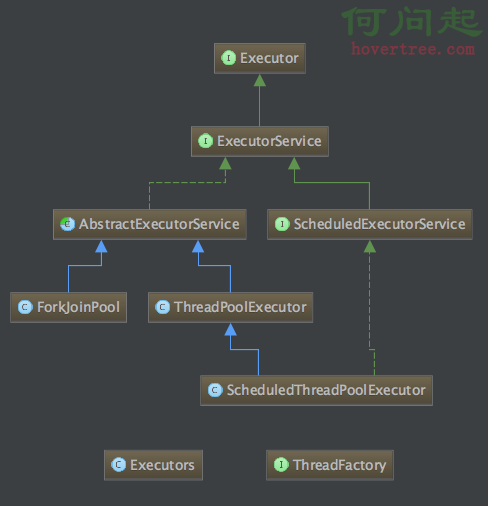
圖2顯示的是Spring JDBC框架的主要組成部分。業務服務對象通過適當的接口繼續使用DAO實現類。JdbcDaoSupport是JDBC數據訪問對象的超類。它與特定的數據源相關聯。Spring Inversion of Control (IOC)容器或BeanFactory負責獲得相應數據源的配置具體信息,並將其與JdbcDaoSupport相關聯。這個類最重要的功能就是使子類可以使用JdbcTemplate對象。
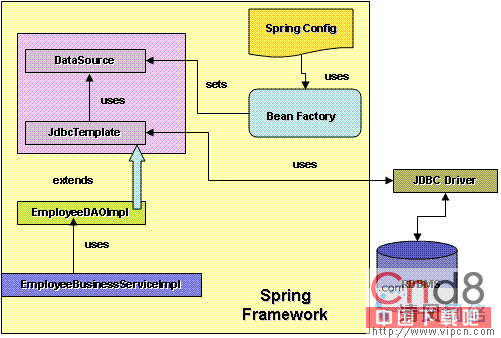
圖2. Spring JDBC框架的主要組件
JdbcTemplate是Spring JDBC框架中最重要的類。引用文獻中的話:“它簡化了JDBC的使用,有助於避免常見的錯誤。它執行核心JDBC工作流,保留應用代碼以提供SQL和提取結果。”這個類通過執行下面的樣板任務來幫助分離JDBC DAO代碼的靜態部分:
從數據源檢索連接。
預備合適的聲明對象。
執行SQL CRUD操作。
遍歷結果集,然後將結果填入標准的collection對象。
處理SQLException異常並將其轉換成更加特定於錯誤的異常層次結構。
利用Spring DAO重新編寫
既然已基本理解了Spring JDBC框架,現在要重新編寫已有的代碼。下面將逐步講述如何解決前幾節中提到的問題。
第一步:修改DAO實現類- 現在從JdbcDaoSupport擴展出EmployeeDAOImpl以獲得JdbcTemplate.
import org.springframework.jdbc.core.support.JdbcDaoSupport;
import org.springframework.jdbc.core.JdbcTemplate;
public class EmployeeDAOImpl extends JdbcDaoSupport
implements IEmployeeDAO{
public List findBySalaryRange(Map salaryMap){
Double dblParams [] = {Double.valueOf((String)
salaryMap.get("MIN_SALARY"))
,Double.valueOf((String)
salaryMap.get("MAX_SALARY"))
};
//The getJdbcTemplate method of JdbcDaoSupport returns an
//instance of JdbcTemplate initialized with a datasource by the
//Spring Bean Factory
JdbcTemplate daoTmplt = this.getJdbcTemplate();
return daoTmplt.queryForList(FIND_BY_SAL_RNG,dblParams);
}
}
在上面的清單中,傳入參數映射中的值存儲在雙字節數組中,順序與SQL字符串中的位置參數相同。queryForList()方法以包含Map(用列名作為鍵,一項對應一列)的List(一項對應一行)的方式返回查詢結果。稍後我會說明如何返回傳輸對象列表。
從簡化的代碼可以明顯看出,JdbcTemplate鼓勵重用,這大大削減了DAO實現中的代碼。JDBC和collection包之間的緊密耦合已經消除。由於JdbcTemplate方法可確保在使用數據庫資源後將其按正確的次序釋放,所以JDBC的資源耗損不再是一個問題。
另外,使用Spring DAO時,不必處理異常。JdbcTemplate類會處理SQLException,並根據SQL錯誤代碼或錯誤狀態將其轉換成特定於Spring異常的層次結構。例如,試圖向主鍵列插入重復值時,將引發DataIntegrityViolationException.然而,假如無法從這一錯誤中恢復,就無需處理該異常。因為Spring DAO的根異常類DataAccessException是運行時異常類,所以可以這樣做。值得注重的是Spring DAO異常獨立於數據訪問實現。假如實現是由O/R映射解決方案提供,就會拋出同樣的異常。
第二步:修改業務服務- 現在業務服務實現了一個新方法setDao(),Spring容器使用該方法傳遞DAO實現類的引用。該過程稱為“設置方法注入(setter injection)”,通過第三步中的配置文件告知Spring容器該過程。注重,不再需要使用DAOFactory,因為Spring BeanFactory提供了這項功能:
public class EmployeeBusinessServiceImpl
implements IEmployeeBusinessService {
IEmployeeDAO empDAO;
public List getEmployeesWithinSalaryRange(Map salaryMap){
List empList = empDAO.findBySalaryRange(salaryMap);
return empList;
}
public void setDao(IEmployeeDAO empDAO){
this.empDAO = empDAO;
}
}
請注重P2I的靈活性;即使極大地改動DAO實現,業務服務實現也只需少量更改。這是由於業務服務現在由Spring容器進行治理。
第三步:配置Bean Factory- Spring bean factory需要一個配置文件進行初始化並啟動Spring框架。這個配置文件包含所有業務服務和帶Spring bean容器的DAO實現類。除此之外,它還包含用於初始化數據源和JdbcDaoSupport的信息:
<?XML version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<!-- Configure Datasource -->
<bean id="FIREBIRD_DATASOURCE"
class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiEnvironment">
<props>
<prop key="java.naming.factory.initial">
weblogic.jndi.WLInitialContextFactory
</prop>
<prop key="java.naming.provider.url">
t3://localhost:7001
</prop>
</props>
</property>
<property name="jndiName">
<value>
jdbc/DBPool
</value>
</property>
</bean>
<!-- Configure DAO -->
<bean id="EMP_DAO" class="com.bea.dev2dev.dao.EmployeeDAOImpl">
<property name="dataSource">
<ref bean="FIREBIRD_DATASOURCE"></ref>
</property>
</bean>
<!-- Configure Business Service -->
<bean id="EMP_BUSINESS"
class="com.bea.dev2dev.sampleapp.business.EmployeeBusinessServiceImpl">
<property name="dao">
<ref bean="EMP_DAO"></ref>
</property>
</bean>
</beans>
這個Spring bean容器通過調用JdbcDaoSupport提供的setDataSource()方法,設置包含DAO實現的數據源對象。
第四步:測試- 最後是編寫JUnit測試類。依照Spring的方式,需要在容器外部進行測試。然而,從第三步中的配置文件可以清楚地看到,我們一直在使用WebLogic Server連接池。
package com.bea.dev2dev.business;
import java.util.*;
import junit.framework.*;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.FileSystemXmlApplicationContext;
public class EmployeeBusinessServiceImplTest extends TestCase {
private IEmployeeBusinessService empBusiness;
private Map salaryMap;
List eXPResult;
protected void setUp() throws Exception {
initSpringFramework();
initSalaryMap();
initExpectedResult();
}
private void initExpectedResult() {
expResult = new ArrayList();
Map tempMap = new HashMap();
tempMap.put("EMP_NO",new Integer(1));
tempMap.put("EMP_NAME","John");
tempMap.put("SALARY",new Double(46.11));
expResult.add(tempMap);
}
private void initSalaryMap() {
salaryMap = new HashMap();
salaryMap.put("MIN_SALARY","1");
salaryMap.put("MAX_SALARY","50");
}
private void initSpringFramework() {
ApplicationContext ac = new FileSystemXmlApplicationContext
("C:/SpringConfig/Spring-Config.xml");
empBusiness =
(IEmployeeBusinessService)ac.getBean("EMP_BUSINESS");
}
protected void tearDown() throws Exception {
}
/**
* Test of getEmployeesWithinSalaryRange method,
* of class
* com.bea.dev2dev.business.EmployeeBusinessServiceImpl.
*/
public void testGetEmployeesWithinSalaryRange() {
List result = empBusiness.getEmployeesWithinSalaryRange
(salaryMap);
assertEquals(expResult, result);
}
}
使用綁定變量
到目前為止,我們搜索了工資介於最低值和最高值之間的雇員。假設在某種情形下,業務用戶想要顛倒這一范圍。DAO代碼很脆弱,將不得不通過更改來滿足要求的變化。這個問題在於使用了靜態的位置綁定變量(用“?”表示)。Spring DAO通過支持命名的綁定變量來拯救這個情況。修改的IEmployeeDAO清單引入了命名的綁定變量(用“:<some name>”表示)。注重查詢中的變化,如下所示:
import java.util.Map;
public interface IEmployeeDAO {
//SQL String that will be executed
public String FIND_BY_SAL_RNG = "SELECT EMP_NO, EMP_NAME, "
+ "SALARY FROM EMP WHERE SALARY >= :max AND SALARY <= :min";
//Returns the list of employees falling into the given salary range
//The input parameter is the immutable map object obtained from
//the HttpServletRequest. This is an early refactoring based on
//- "Introduce Parameter Object"
public List findBySalaryRange(Map salaryMap);
}
多數JDBC驅動程序僅支持位置綁定變量。所以,Spring DAO在運行時將這個查詢轉換成位置綁定、基於變量的查詢,並且設置正確的綁定變量。現在,為了完成這些任務,需要使用NamedParameterJdbcDaoSupport類和NamedParameterJdbcTemplate類,以代替JdbcDaoSupport和JdbcTemplate.下面就是修改後的DAO實現類:
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcDaoSupport;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
public class EmployeeDAOImpl extends NamedParameterJdbcDaoSupport
implements IEmployeeDAO{
public List findBySalaryRange(Map salaryMap){
NamedParameterJdbcTemplate tmplt =
this.getNamedParameterJdbcTemplate();
return tmplt.queryForList(IEmployeeDAO.FIND_BY_SAL_RNG
,salaryMap);
}
}
NamedParameterJdbcDaoSupport的getNamedParameterJdbcTemplate()方法返回一個NamedParameterJdbcTemplate實例,該實例由數據源句柄進行了預初始化。Spring Beanfactory執行初始化任務,從配置文件獲得所有的具體信息。在執行時,一旦將命名的參數替換成位置占位符,NamedParameterJdbcTemplate就將操作委托給JdbcTemplate.可見,使用命名的參數使得DAO方法不受底層SQL聲明任何更改的影響。
最後,假如數據庫不支持自動類型轉換,需要如下所示,對JUnit測試類中的initSalaryMap()方法稍做修改。
private void initSalaryMap() {
salaryMap = new HashMap();
salaryMap.put("MIN_SALARY",new Double(1));
salaryMap.put("MAX_SALARY",new Double(50));
}
Spring DAO回調函數
至此,已經說明為了解決傳統DAO設計中存在的問題,如何封裝和概括JdbcTemplate類中JDBC代碼的靜態部分。現在了解一下有關變量的問題,如設置綁定變量、結果集遍歷等。雖然Spring DAO已經擁有這些問題的一般化解決方案,但在某些基於SQL的情況下,可能仍需要設置綁定變量。
在嘗試向Spring DAO轉換的過程中,介紹了由於業務服務及其客戶機之間的約定遭到破壞而導致的隱蔽運行時錯誤。這個錯誤的來源可以追溯到原始的DAO.dbcTemplate.queryForList()方法不再返回EmployeeTO實例列表。而是返回一個map表(每個map是結果集的一行)。
如您目前所知,JdbcTemplate基於模板方法設計模式,該模式利用JDBC API定義SQL執行工作流。必須改變這個工作流以修復被破壞的約定。第一個選擇是在子類中更改或擴展工作流。您可以遍歷JdbcTemplate.queryForList()返回的列表,用EmployeeTO實例替換map對象。然而,這會導致我們一直竭力避免的靜態代碼與動態代碼的混合。第二個選擇是將代碼插入JdbcTemplate提供的各種工作流修改鉤子(hook)。明智的做法是在一個不同的類中封裝傳輸對象填充代碼,然後通過鉤子鏈接它。填充邏輯的任何修改將不會改變DAO.
編寫一個類,使其實現在Spring框架特定的接口中定義的方法,就可以實現第二個選擇。這些方法稱為回調函數,通過JdbcTemplate向框架注冊。當發生相應的事件(例如,遍歷結果集並填充獨立於框架的傳輸對象)時,框架將調用這些方法。
第一步:傳輸對象
下面是您可能感愛好的傳輸對象。注重,以下所示的傳輸對象是固定的:
package com.bea.dev2dev.to;
public final class EmployeeTO implements Serializable{
private int empNo;
private String empName;
private double salary;
/** Creates a new instance of EmployeeTO */
public EmployeeTO(int empNo,String empName,double salary) {
this.empNo = empNo;
this.empName = empName;
this.salary = salary;
}
public String getEmpName() {
return this.empName;
}
public int getEmpNo() {
return this.empNo;
}
public double getSalary() {
return this.salary;
}
public boolean equals(EmployeeTO empTO){
return empTO.empNo == this.empNo;
}
}
第二步:實現回調接口
實現RowMapper接口,填充來自結果集的傳輸對象。下面是一個例子:
package com.bea.dev2dev.dao.mapper;
import com.bea.dev2dev.to.EmployeeTO;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.springframework.jdbc.core.RowMapper;
public class EmployeeTOMapper implements RowMapper{
public Object mapRow(ResultSet rs, int rowNum)
throws SQLException{
int empNo = rs.getInt(1);
String empName = rs.getString(2);
double salary = rs.getDouble(3);
EmployeeTO empTo = new EmployeeTO(empNo,empName,salary);
return empTo;
}
}
注重實現類不應該對提供的ResultSet對象調用next()方法。這由框架負責,該類只要從結果集的當前行提取值就行。回調實現拋出的任何SQLException也由Spring框架處理。
第三步:插入回調接口
執行SQL查詢時,JdbcTemplate利用默認的RowMapper實現產生map列表。現在需要注冊自定義回調實現來修改JdbcTemplate的這一行為。注重現在用的是NamedParameterJdbcTemplate的query()方法,而不是queryForList()方法:
public class EmployeeDAOImpl extends NamedParameterJdbcDaoSupport
implements IEmployeeDAO{
public List findBySalaryRange(Map salaryMap){
NamedParameterJdbcTemplate daoTmplt =
getNamedParameterJdbcTemplate();
return daoTmplt.query(IEmployeeDAO.FIND_BY_SAL_RNG, salaryMap,
new EmployeeTOMapper());
}
}
Spring DAO框架對執行查詢後返回的結果進行遍歷。它在遍歷的每一步調用EmployeeTOMapper類實現的mapRow()方法,使用EmployeeTO傳輸對象填充最終結果的每一行。
第四步:修改後的JUnit類
現在要根據返回的傳輸對象測試這些結果。為此要對測試方法進行修改。
public class EmployeeBusinessServiceImplTest extends TestCase {
private IEmployeeBusinessService empBusiness;
private Map salaryMap;
List expResult;
// all methods not shown in the listing remain the
// same as in the previous example
private void initExpectedResult() {
expResult = new ArrayList();
EmployeeTO to = new EmployeeTO(2,"John",46.11);
expResult.add(to);
}
/**
* Test of getEmployeesWithinSalaryRange method, of
* class com.bea.dev2dev.business.
* EmployeeBusinessServiceImpl
*/
public void testGetEmployeesWithinSalaryRange() {
List result = empBusiness.
getEmployeesWithinSalaryRange(salaryMap);
assertEquals(expResult, result);
}
public void assertEquals(List expResult, List result){
EmployeeTO expTO = (EmployeeTO) expResult.get(0);
EmployeeTO actualTO = (EmployeeTO) result.get(0);
if(!expTO.equals(actualTO)){
throw new RuntimeException("** Test Failed **");
}
}
}
優勢
Spring JDBC框架的優點很清楚。我們獲益很多,並將DAO方法簡化到只有幾行代碼。代碼不再脆弱,這要感謝該框架對命名的參數綁定變量的“開箱即用”支持,以及在映射程序中將傳輸對象填充邏輯分離。
Spring JDBC的優點應該促使您向這一框架移植現有的代碼。希望本文在這一方面能有所幫助。它會幫助您獲得一些重構工具和知識。例如,假如您沒有采用P2I Extract Interface,那麼可以使用重構,從現有的DAO實現類創建接口。除此之外,查看本文的參考資料可以得到更多指導。
源代碼下載