正則表達式,一個十分古老而又強大的文本處理工具,僅僅用一段非常簡短的表達式語句,便能夠快速實現一個非常復雜的業務邏輯。熟練地掌握正則表達式的話,能夠使你的開發效率得到極大的提升。
正則表達式經常被用於字段或任意字符串的校驗,如下面這段校驗基本日期格式的JavaScript代碼:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');下面是技匠整理的,在前端開發中經常使用到的20個正則表達式。
密碼的強度必須是包含大小寫字母和數字的組合,不能使用特殊字符,長度在8-10之間。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$字符串僅能是中文。
^[\\u4e00-\\u9fa5]{0,}$^\\w+$同密碼一樣,下面是E-mail地址合規性的正則檢查語句。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?下面是身份證號碼的正則校驗。15 或 18位。
15位:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$18位:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$“yyyy-mm-dd“ 格式的日期校驗,已考慮平閏年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$金額校驗,精確到2位小數。
^[0-9]+(.[0-9]{2})?$下面是國內 13、15、18開頭的手機號正則表達式。(可根據目前國內收集號擴展前兩位開頭號碼)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$IE目前還沒被完全取代,很多頁面還是需要做版本兼容,下面是IE版本檢查的表達式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$IP4 正則語句。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\bIP6 正則語句。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))應用開發中很多時候需要區分請求是HTTPS還是HTTP,通過下面的表達式可以取出一個url的前綴然後再邏輯判斷。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}下面的這個表達式可以篩選出一段文本中的URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?驗證windows下文件路徑和擴展名(下面的例子中為.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"<>|]+\\.txt(l)?$有時需要抽取網頁中的顏色代碼,可以使用下面的表達式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$假若你想提取網頁中所有圖片信息,可以利用下面的表達式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)提取html中的超鏈接。
(<a\\s*(?!.*\\brel=)[^>]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>通過下面的表達式,可以搜索到相匹配的CSS屬性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}如果你需要移除HMTL中的注釋,可以使用如下的表達式。
<!--(.*?)-->通過下面的表達式可以匹配出HTML中的標簽屬性。
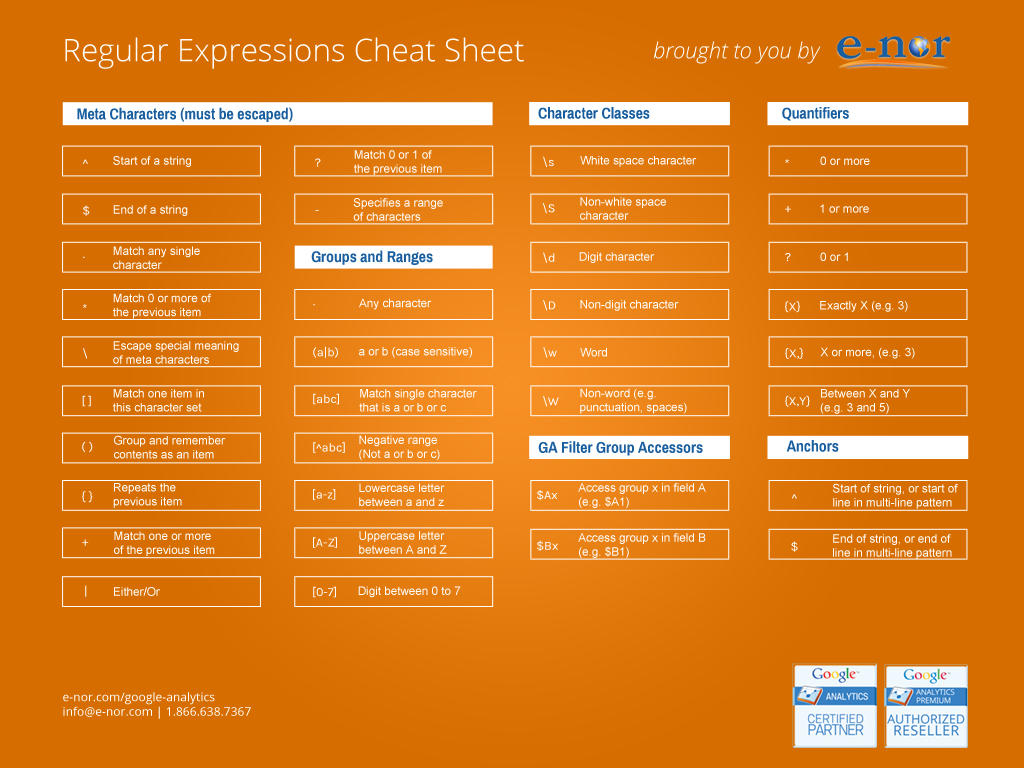
<\\/?\\w+((\\s+\\w+(\\s*=\\s*(?:".*?"|'.*?'|[\\^'">\\s]+))?)+\\s*|\\s*)\\/?>下面是我找到的一張非常不錯的正則表達式 Cheat Sheet,可以用來快速查找相關語法。
我在網上看到了一篇相當不錯的正則表達式快速學習指南,有興趣繼續深入學習的同學可以參考。
regex101是一個非常不錯的正則表達式在線測試工具,你可以直接在線測試你的正則表達式哦。
另外,我也網上找到幾本不錯的正則表達式方面的教程和書籍,並將它們分享到了技匠社jijiangshe.com,如果你有興趣學習歡迎訪問獲取。^_^
原文鏈接:知道這20個正則表達式,能讓你少寫1000行代碼