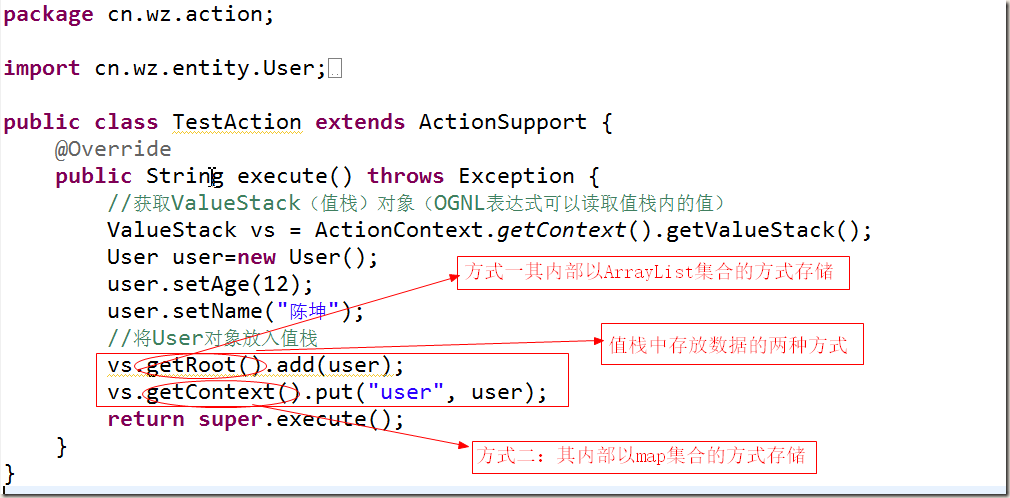
集合技術
/*
* 猜數字游戲
*/
public class HomeWork1 {
public static void main(String[] args) {
// 獲取被猜的那個數字,需要使用隨機數類產生
Random r = new Random();
// 獲取到1~100之間的一個數字
int number = r.nextInt(100) + 1;
// 創建專門負責鍵盤錄入的那個對象
Scanner sc = new Scanner( System.in );
// 使用死循環,完成數字的判斷和重復輸入功能
while( true ){
// 獲取鍵盤錄入的數字
System.out.println("請輸入您猜的數字(范圍1~100):");
int x = sc.nextInt();
// 判斷當前輸入的數字和被猜的那個數字關系
if( x == number ){
System.out.println("恭喜您,猜中啦!!!");
break;
}else if( x < number ){
System.out.println("您猜小了,請繼續");
}else{
System.out.println("您猜大了,請繼續");
}
}
}
}
集合:Collection接口,它是集合的頂層接口。其中定義了集合共性的操作方法。
增:add、addAll
刪除:clear、remove、removeAll、RetainAll
查詢:size
遍歷:iterator,得到一個迭代器對象
判斷:contains、containsAll、isEmpty
迭代器對象:Iterator,它是所有集合共有的迭代對象
細節:
List接口:
Set接口:
List接口它是Collection接口的子接口。List接口下的所有集合容器:
由於List接口下的集合擁有下標,因此List接口擁有自己特有的方法:這些方法都是圍繞下標設計的。
add(int index , Object element )
remove( int index )
get( int index )
set( int index , Object element )
List接口自己的迭代器:
ListIterator:它可以正向或逆向遍歷List集合。同時可以對集合進行增,刪、改、查操作。
ArrayList:它的底層是可變數組,查詢快,增刪慢,不安全!
LinkedList集合,它也List接口的實現類。和ArrayList相同。都可以去使用List接口中的所有方法。
sun公司給List接口提供多個實現類的目的:
原因是實際開發中,我們需要不同的容器來存儲不同對象。
不同的容器:每個容器都有自己對數據的存儲方式(數據結構)。不同方式結構存儲的數據,它們在性能上差異很大。

LinkedList集合:它的底層是鏈接列表結構(鏈表)。
鏈表:它主要也是用來存儲數據。存儲數據的每個空間被稱為節點。
節點一般分成2個小空間:一個存儲的節點的地址,一個存儲的真正存放的數據。
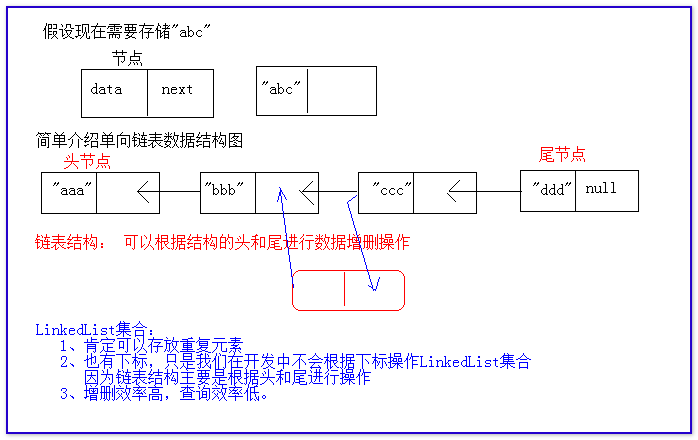
由於LinkedList集合底層是鏈表結構。因此LinkedList集合在List接口之上,有增加了圍繞頭和尾而設計的增、刪、改、查操作。
xxxxFirst 和 xxxxxLast方法
// 刪除方法
public static void demo2() {
/// 創建集合對象
LinkedList list = new LinkedList();
// 添加元素
list.addFirst("aaa");
list.addFirst("bbb");
list.addLast("ccc");
// 刪除方法
Object obj = list.removeFirst();
System.out.println(obj);
System.out.println(list);
}
// 添加方法
public static void demo1() {
/// 創建集合對象
LinkedList list = new LinkedList();
// 添加元素
list.addFirst("aaa");
list.addFirst("bbb");
list.addLast("ccc");
// 遍歷
for( Iterator it = list.iterator() ; it.hasNext() ; ){
System.out.println(it.next());
}
}
/*
* 由於LinkedList集合它有頭和尾,因此經常使用這個集合模擬其他的數據結構
* 隊列結構:這種結構存儲的數據在容器,最先進入容器的元素,先先出去。
* 簡單介紹:先進先出,後進後出
* 例如:排隊買票。火車過山洞。
*
* 堆棧結構:這種結構存儲的數據在容器,最先進入的最後出去
* 簡單介紹:先進後出,後進先出。
* 例如:彈夾。Java中的棧內存。
*/
public static void demo3() {
/// 創建集合對象
LinkedList list = new LinkedList();
// 添加元素
list.addLast("aaa");
list.addLast("bbb");
list.addLast("ccc");
list.addLast("ddd");
list.addLast("eee");
// 模擬隊列結構
System.out.println(list.removeFirst());
System.out.println(list.removeFirst());
System.out.println(list.removeFirst());
System.out.println(list.removeFirst());
System.out.println(list.removeFirst());
/*
* 結論:使用LinkedList模擬隊列結構的時候:
* 添加和刪除的方法調用正好相反。
* 添加使用addLast ,刪除就使用removeFirst
* 添加使用addFirst,刪除就使用removeLast
*
* 模擬堆棧結構:
* 添加使用addLast ,刪除就使用removeLast
* 添加使用addFirst ,刪除就使用removeFirst
*/
}

Vector集合它是JDK1.0時期存在的集合。其功能和ArrayList集合相同。
Vector的底層使用的也是可變數組。Vector集合它增刪、查詢都慢。它的底層是安全的。後期看到Vector集合,就當作ArrayList集合使用。
// 使用Iterator遍歷
public static void demo1() {
// 創建集合對象
Vector v = new Vector();
// 添加方法
v.addElement("aaa");
v.add("bbb");
v.add("bbb");
v.add("ccc");
// 使用Iterator遍歷
for( Iterator it = v.iterator() ; it.hasNext() ; ){
System.out.println(it.next());
}
}

// 使用古老的枚舉迭代器遍歷
public static void demo2() {
// 創建集合對象
Vector v = new Vector();
// 添加方法
v.addElement("aaa");
v.add("bbb");
v.add("bbb");
v.add("ccc");
/*
* 使用Vector中的 elements 方法可以得到一個枚舉迭代器(早期迭代器)
* Enumeration : 它是一個接口,主要用來遍歷集合(Vector)
* Enumeration這個接口被Iterator代替,並且Iterator中有remove方法,
* Iterator中的方法名稱較短。
*/
Enumeration en = v.elements();
while( en.hasMoreElements() ){
System.out.println(en.nextElement());
}
}
List接口:它限定它下面的所有集合容器擁有下標、可以存放重復元素、有序。其中定義了圍繞下標而操作的方法。
ArrayList:
底層是可變數組。增刪慢、查詢快。不安全。可以使用null作為元素。
LinkedList:
底層是鏈表結構。增刪快、查詢慢,不安全。可以使用null作為元素。其中定義了圍繞頭和尾的方法,可以模擬 隊列或堆棧數據結構。
Vector:
底層是可變數組,被ArrayList代替。什麼都慢。但安全。可以使用null作為元素
Enumeration:它是古老的迭代器。被Iterator代替。
前面學習Collection接口的時候,下面有2個子接口:
List接口:可以保存重復元素,有下標,有序。
Set接口:可以保存不重復元素。
注意:Set接口沒有自己特有的方法,所有方法全部來自於Collection接口。
Set接口下的所有集合容器中保存的元素都不會重復。
Set接口下有2個重要的集合:
HashSet:
TreeSet:

HashSet:它的底層是哈希表結構支持。它不保證迭代順序(存取),同時它不安全。
/*
* 演示 HashSet集合
*/
public class HashSetDemo {
public static void main(String[] args) {
// 創建集合對象
HashSet set = new HashSet();
// 添加元素
set.add("aaa");
set.add("aaa");
set.add("bbb");
set.add("ccc");
set.add("ccc");
set.add("ddd");
// 使用Iterator遍歷
for( Iterator it = set.iterator() ; it.hasNext() ; ){
System.out.println( it.next() );
}
}
}
哈希表:它也是一種存儲數據的方式。它的底層使用的依然是數組,只是在存儲元素的時候不按照數組下標從小到大的順序存放。
如果有元素需要給哈希表結構中保存的時候,這時不會直接將元素給表中保存,而是根據當前這個元素自身的一些特點(成員變量等)計算這個元素應該在表中的那個空間中保存。
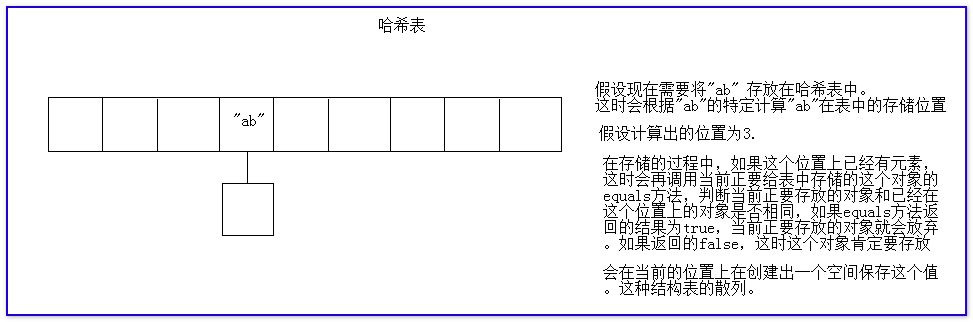
哈希表存放對象的時候,需要根據當前對象的特定計算對象在表中的存儲位置。任何對象都可以給集合中保存,那麼任何對象肯定可以給HashSet集合中保存。
任何對象在保存的時候,都需要計算存儲位置。任何對都應該具體計算存儲位置的功能,這個功能(方法)定義在Object類中。

我們給任何哈希表中存儲的對象,都會依賴這個對象的hashCode方法計算哈希值,通過哈希值確定對象在表中的存儲位置。
哈希沖突:如果兩個對象調用hahsCode方法之後得到的哈希值相同,稱為哈希沖突。
在給哈希中存放對象的時候,如果存儲哈希沖突,這時就會調用2個對象equals方法計算它們是否相同。如果相同,就丟棄當前正要存放的這個對象,如果不同就會繼續保存。
自定義對象:不使用JDK中提供的類創建的對象,自己書寫一個,然後創建這個類的對象,最後將其保存在HashSet集合中。
/*
* 演示給HashSet中存放自定義對象
*/
public class HashSetDemo2 {
public static void main(String[] args) {
// 創建集合對象
HashSet set = new HashSet();
// 添加Person對象到集合中
Person p = new Person("zhangsan",12);
set.add(p);
set.add(new Person("lisi",22));
set.add(new Person("lisi",22));
set.add(new Person("wangwu",29));
set.add(new Person("zhaoliu",32));
set.add(new Person("zhaoliu",32));
set.add(new Person("tianqi",35));
// 遍歷
for( Iterator it = set.iterator(); it.hasNext() ; ){
System.out.println(it.next());
}
}
}
/*
* 自定義類
*/
public class Person {
private String name;
private int age;
// alt + shift + S
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
}
運行上面的程序,給HashSet中保存Person對象:
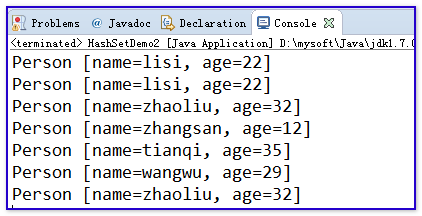
發現運行的結果出現了重復的數據。
解釋存儲的Person對象重復的原因:
我們知道HashSet的底層使用的哈希表,哈希表在存儲對象的時候需要調用對象自身的hashCode方法計算在表中存儲的位置。
而在我們自己的程序中,我們創建了多個Person對象,每個Person對象都在堆中有自己的內存地址。雖然有些Person對象表示的name和age相同的,但是他們所在的對象的內存地址是不同的。而我們在書寫的Person類又繼承了Object類,這樣就相當於Person類擁有了hashCode方法,而這個hashCode方法完全使用的是Object類中的。而Object類中的hashCode方法是根據當前對象的內存地址計算哈希值,每個Person對象都擁有自己的內存地址,即使他們的name和age相同,但是他們的內存地址不同,計算出來的哈希值肯定也不同,那麼每個Person對象都可以保存到哈希表中。
解決方案:
根據每個Person對象自己的name和age計算它們的哈希值。相當於Person類繼承到Object類中的hashCode方法不適合當前Person類,Person類需要復寫hashCode方法。
復寫完hashCode方法之後,還要復寫Object類中的equals方法。因為如果hashCode計算的結果相同,這時還要調用equals方法來判斷2個對象是否相同。
而Object類中的equals方法在使用2個對象的地址比較。而我們創建的每個Person地址都不相同,那麼直接使用Object類中的equals方法,比較的結果肯定是false。我們希望通過2個對象的name和age比較2個對象是否相同。
HashSet集合保證對象唯一:
結論:以後只要是給HashSet集合中保存的對象,這個對象所屬的類一定要復寫Object類中的hashCode和equals方法。
1、HashSet集合是Set接口的實現類。它保證元素不重復。
2、HashSet底層使用的哈希表,不保證存取的順序(迭代順序)。
3、保證對象不重復需要復寫hashCode和equals方法。
4、HashSet集合只能使用Iterator和foreach遍歷,不能使用List接口的特有方法遍歷。
5、HashSet不安全。

LinkedHashSet集合:它是HashSet的子類。它的底層接口是鏈表+哈希表結構。
它的特點:
LinkedHashSet集合沒有自己特有方法,所有方法全部繼承與HashSet集合。
/*
* 演示LinkedHashSet集合
*/
public class LinkedHashSetDemo {
public static void main(String[] args) {
// 創建集合對象
LinkedHashSet set = new LinkedHashSet();
// 添加元素
set.add("ccc");
set.add("bbb");
set.add("bbb");
set.add("ddd");
set.add("ddd");
set.add("aaa");
set.add("aaa");
// 使用Iterator遍歷
for (Iterator it = set.iterator(); it.hasNext();) {
System.out.println(it.next());
}
}
}
ArrayList:底層可變數組,可以保存重復元素,有下標。
LinkedList:底層鏈表結構,有頭和尾,可以保存重復元素。
HashSet:底層哈希表,不重復,不保證存儲順序。
LinkedHashSet:底層哈希表+鏈表,不重復,保證存取順序。
上面的這些集合容器可以存儲對象,但是他們都不能對其中保存的對象進行排序操作。
TreeSet:它依然是Set接口的實現類,肯定可以使用Set接口中的所有方法。同時也會保證對象的唯一。TreeSet集合容器中保存對象的時候,只要將對象放到這個集合中,集合底層會自動的對其中的所有元素進行排序。當我們在取出的時候,元素全部排序完成。

TreeSet集合:它的底層使用二叉樹(紅黑樹)結構。這種結構可以對其中的元素進行自然排序。

/*
* 演示TreeSet集合
*/
public class TreeSetDemo {
public static void main(String[] args) {
// 創建集合對象
TreeSet set = new TreeSet();
// 給集合中添加方法
set.add("aaa");
set.add("aaa");
set.add("aaa");
set.add("bbb");
set.add("bbb");
set.add("AAA");
set.add("ABC");
set.add("Abc");
set.add("123");
// 遍歷
for( Iterator it = set.iterator() ; it.hasNext() ; ){
System.out.println(it.next());
}
}
}
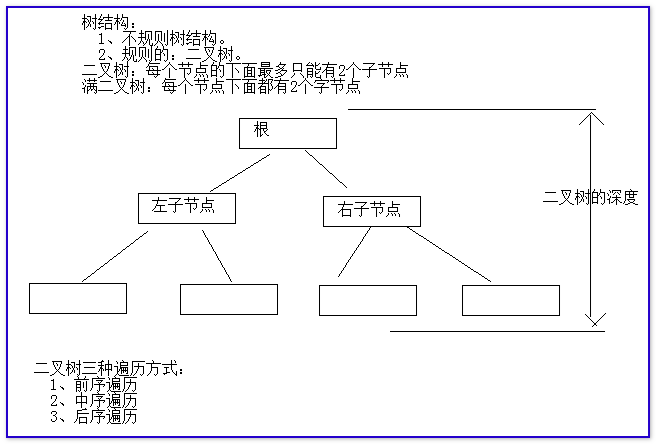
樹:它也是一種數據結構。這種結構它默認可以對其中的數據進行排序。
我們如果給樹結構中存儲元素的時候,每個存儲元素的空間被節點。處於樹根的位置節點稱為根節點。其他節點稱為子節點(葉子節點)。
TreeSet底層存儲數據時的方式:
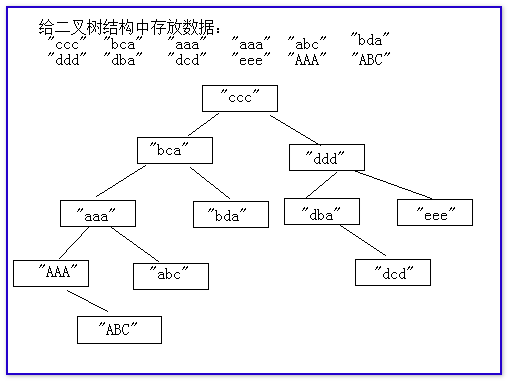
當我們給TreeSet集合中保存對象的時候,需要拿當前這個對象和已經在樹上的元素進行比較大小,如果存儲的元素小,就會當前這個節點的左側保存,如果比當前這個節點的值大,就給當前這個節點的右側保存。如果和當前 這個節點相同,丟棄不保存。
需要拿當前這個對象和當前節點上的值進行大小的比較。這時要求能夠TreeSet集合中保存的對象,一定可以進行大小的比較。
注意:給TreeSet中保存的對象,一定要保證這些對象類型相同,或者他們之間有繼承關系。


上面代碼在運行的時候發生異常:

發生異常的原因:
在TreeSet的底層,需要將添加到TreeSet集合中的對象強制轉成Comparable類型。如果添加的對象不屬於Comparable類型,那麼在添加的時候就會發生類型轉換異常。
底層將傳遞的對象強轉成Comparable接口的原因:因為Comparable接口是Java中規定的比較大小的接口。只要哪個類需要比較大小,就應該主動去實現Comparable接口。
異常的解決方案:讓Person類實現Comparable接口。
/*
* 自定義類
*/
public class Person implements Comparable{
private String name;
private int age;
// alt + shift + S
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
/*
* 當一個類實現Comparable接口之後,這個類中肯定會compareTo方法
* 而這個方法才是真比較對象大小的方法,
* 這個方法的返回值有三種情況:
* 零:表示兩個對象相同
* 正數:調用這個方法的那個對象,比傳遞進來的這個對象大
* 負數:調用這個方法的那個對象,比傳遞進來的這個對象小
* 因此一般要求在實現Comparable接口之後在compareTo方法中
* 根據當前對象的自身屬性的特定比較大小
*/
public int compareTo(Object o) {
// 由於傳遞進來的對象被提升成Object類型,因此需要向下轉型
if( !(o instanceof Person ) ){
// 如果判斷成立,說明傳遞進來的不是Person
throw new ClassCastException("請傳遞一個Person進來,否則不給你比較");
}
// 向下轉型
Person p = (Person) o;
// 因為age都是int值,如果相等,它們的差值恰好是零
int temp = this.age - p.age;
return temp == 0 ? this.name.compareTo(p.name) : temp;
}
}
學生管理系統程序。