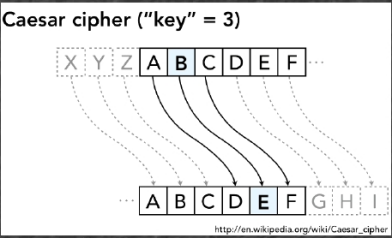
IO模型,io
前言
說到IO模型,都會牽扯到同步、異步、阻塞、非阻塞這幾個詞。從詞的表面上看,很多人都覺得很容易理解。但是細細一想,卻總會發現有點摸不著頭腦。自己也曾被這幾個詞弄的迷迷糊糊的,每次看相關資料弄明白了,然後很快又給搞混了。經歷過這麼幾次之後,發現這東西必須得有所總結提煉才不至於再次混為一談。尤其是最近看到好幾篇講這個的文章,很多都有謬誤,很容易把本來就搞不清楚的人弄的更加迷糊。
最適合IO模型的例子應該是咱們平常生活中的去餐館吃飯這個場景,下文就結合這個來講解一下經典的幾個IO模型。在此之前,先需要說明以下幾點:
- IO有內存IO、網絡IO和磁盤IO三種,通常我們說的IO指的是後兩者。
- 阻塞和非阻塞,是函數/方法的實現方式,即在數據就緒之前是立刻返回還是等待。
- 以文件IO為例,一個IO讀過程是文件數據從磁盤→內核緩沖區→用戶內存的過程。同步與異步的區別主要在於數據從內核緩沖區→用戶內存這個過程需不需要用戶進程等待。(網絡IO把磁盤換做網卡即可)
IO模型
同步阻塞
去餐館吃飯,點一個自己最愛吃的蓋澆飯,然後在原地等著一直到蓋澆飯做好,自己端到餐桌就餐。這就是典型的同步阻塞。當廚師給你做飯的時候,你需要一直在那裡等著。
網絡編程中,讀取客戶端的數據需要調用recvfrom。在默認情況下,這個調用會一直阻塞直到數據接收完畢,就是一個同步阻塞的IO方式。這也是最簡單的IO模型,在通常fd較少、就緒很快的情況下使用是沒有問題的。
同步非阻塞
接著上面的例子,你每次點完飯就在那裡等著,突然有一天你發現自己真傻。於是,你點完之後,就回桌子那裡坐著,然後估計差不多了,就問老板飯好了沒,如果好了就去端,沒好的話就等一會再去問,依次循環直到飯做好。這就是同步非阻塞。
這種方式在編程中對socket設置O_NONBLOCK即可。但此方式僅僅針對網絡IO有效,對磁盤IO並沒有作用。因為本地文件IO就沒有被認為是阻塞,我們所說的網絡IO的阻塞是因為網路IO有無限阻塞的可能,而本地文件除非是被鎖住,否則是不可能無限阻塞的,因此只有鎖這種情況下,O_NONBLOCK才會有作用。而且,磁盤IO時要麼數據在內核緩沖區中直接可以返回,要麼需要調用物理設備去讀取,這時候進程的其他工作都需要等待。因此,後續的IO復用和信號驅動IO對文件IO也是沒有意義的。
此外,需要說明的一點是nginx和node中對於本地文件的IO是用線程的方式模擬非阻塞的效果的,而對於靜態文件的io,使用zero copy(例如sendfile)的效率是非常高的。
IO復用
接著上面的列子,你點一份飯然後循環的去問好沒好顯然有點得不償失,還不如就等在那裡直到准備好,但是當你點了好幾樣飯菜的時候,你每次都去問一下所有飯菜的狀態(未做好/已做好)肯定比你每次阻塞在那裡等著好多了。當然,你問的時候是需要阻塞的,一直到有准備好的飯菜或者你等的不耐煩(超時)。這就引出了IO復用,也叫多路IO就緒通知。這是一種進程預先告知內核的能力,讓內核發現進程指定的一個或多個IO條件就緒了,就通知進程。使得一個進程能在一連串的事件上等待。
IO復用的實現方式目前主要有select、poll和epoll。
select和poll的原理基本相同:
- 注冊待偵聽的fd(這裡的fd創建時最好使用非阻塞)
- 每次調用都去檢查這些fd的狀態,當有一個或者多個fd就緒的時候返回
- 返回結果中包括已就緒和未就緒的fd
相比select,poll解決了單個進程能夠打開的文件描述符數量有限制這個問題:select受限於FD_SIZE的限制,如果修改則需要修改這個宏重新編譯內核;而poll通過一個pollfd數組向內核傳遞需要關注的事件,避開了文件描述符數量限制。
此外,select和poll共同具有的一個很大的缺點就是包含大量fd的數組被整體復制於用戶態和內核態地址空間之間,開銷會隨著fd數量增多而線性增大。
select和poll就類似於上面說的就餐方式。但當你每次都去詢問時,老板會把所有你點的飯菜都輪詢一遍再告訴你情況,當大量飯菜很長時間都不能准備好的情況下是很低效的。於是,老板有些不耐煩了,就讓廚師每做好一個菜就通知他。這樣每次你再去問的時候,他會直接把已經准備好的菜告訴你,你再去端。這就是事件驅動IO就緒通知的方式-epoll。
epoll的出現,解決了select、poll的缺點:
- 基於事件驅動的方式,避免了每次都要把所有fd都掃描一遍。
- epoll_wait只返回就緒的fd。
- epoll使用nmap內存映射技術避免了內存復制的開銷。
- epoll的fd數量上限是操作系統的最大文件句柄數目,這個數目一般和內存有關,通常遠大於1024。
目前,epoll是Linux2.6下最高效的IO復用方式,也是Nginx、Node的IO實現方式。而在freeBSD下,kqueue是另一種類似於epoll的IO復用方式。
此外,對於IO復用還有一個水平觸發和邊緣觸發的概念:
- 水平觸發:當就緒的fd未被用戶進程處理後,下一次查詢依舊會返回,這是select和poll的觸發方式。
- 邊緣觸發:無論就緒的fd是否被處理,下一次不再返回。理論上性能更高,但是實現相當復雜,並且任何意外的丟失事件都會造成請求處理錯誤。epoll默認使用水平觸發,通過相應選項可以使用邊緣觸發。
信號驅動
上文的就餐方式還是需要你每次都去問一下飯菜狀況。於是,你再次不耐煩了,就跟老板說,哪個飯菜好了就通知我一聲吧。然後就自己坐在桌子那裡干自己的事情。更甚者,你可以把手機號留給老板,自己出門,等飯菜好了直接發條短信給你。這就類似信號驅動的IO模型。
流程如下:
- 開啟套接字信號驅動IO功能
- 系統調用sigaction執行信號處理函數(非阻塞,立刻返回)
- 數據就緒,生成sigio信號,通過信號回調通知應用來讀取數據。
異步非阻塞
之前的就餐方式,到最後總是需要你自己去把飯菜端到餐桌。這下你也不耐煩了,於是就告訴老板,能不能飯好了直接端到你的面前或者送到你的家裡(外賣)。這就是異步非阻塞IO了。
對比信號驅動IO,異步IO的主要區別在於:信號驅動由內核告訴我們何時可以開始一個IO操作(數據在內核緩沖區中),而異步IO則由內核通知IO操作何時已經完成(數據已經在用戶空間中)。
異步IO又叫做事件驅動IO,在Unix中,POSIX1003.1標准為異步方式訪問文件定義了一套庫函數,定義了AIO的一系列接口。使用aio_read或者aio_write發起異步IO操作。使用aio_error檢查正在運行的IO操作的狀態。
網絡編程模型
上文講述了UNIX環境的五種IO模型。基於這五種模型,在Java中,隨著NIO和NIO2.0(AIO)的引入,一般具有以下幾種網絡編程模型:
BIO
BIO是一個典型的網絡編程模型,是通常我們實現一個服務端程序的過程,步驟如下:
- 主線程accept請求阻塞
- 請求到達,創建新的線程來處理這個套接字,完成對客戶端的響應。
- 主線程繼續accept下一個請求
這種模型有一個很大的問題是:當客戶端連接增多時,服務端創建的線程也會暴漲,系統性能會急劇下降。因此,在此模型的基礎上,類似於 tomcat的bio connector,采用的是線程池來避免對於每一個客戶端都創建一個線程。有些地方把這種方式叫做偽異步IO(把請求拋到線程池中異步等待處理)。
NIO
JDK1.4開始引入了NIO類庫,這裡的NIO指的是Non-blcok IO,主要是使用Selector多路復用器來實現。Selector在Linux等主流操作系統上是通過epoll實現的。
NIO的實現流程,類似於select:
- 創建ServerSocketChannel監聽客戶端連接並綁定監聽端口,設置為非阻塞模式。
- 創建Reactor線程,創建多路復用器(Selector)並啟動線程。
- 將ServerSocketChannel注冊到Reactor線程的Selector上。監聽accept事件。
- Selector在線程run方法中無線循環輪詢准備就緒的Key。
- Selector監聽到新的客戶端接入,處理新的請求,完成tcp三次握手,建立物理連接。
- 將新的客戶端連接注冊到Selector上,監聽讀操作。讀取客戶端發送的網絡消息。
- 客戶端發送的數據就緒則讀取客戶端請求,進行處理。
相比BIO,NIO的編程非常復雜。
AIO
JDK1.7引入NIO2.0,提供了異步文件通道和異步套接字通道的實現,是真正的異步非阻塞IO, 對應於Unix中的異步IO。
- 創建AsynchronousServerSocketChannel,綁定監聽端口
- 調用AsynchronousServerSocketChannel的accpet方法,傳入自己實現的CompletionHandler。包括上一步,都是非阻塞的
- 連接傳入,回調CompletionHandler的completed方法,在裡面,調用AsynchronousSocketChannel的read方法,傳入負責處理數據的CompletionHandler。
- 數據就緒,觸發負責處理數據的CompletionHandler的completed方法。繼續做下一步處理即可。
- 寫入操作類似,也需要傳入CompletionHandler。
其編程模型相比NIO有了不少的簡化。
對比
.
同步阻塞IO
偽異步IO
NIO
AIO
客戶端數目 :IO線程
1 : 1
m : n
m : 1
m : 0
IO模型
同步阻塞IO
同步阻塞IO
同步非阻塞IO
異步非阻塞IO
吞吐量
低
中
高
高
編程復雜度
簡單
簡單
非常復雜
復雜