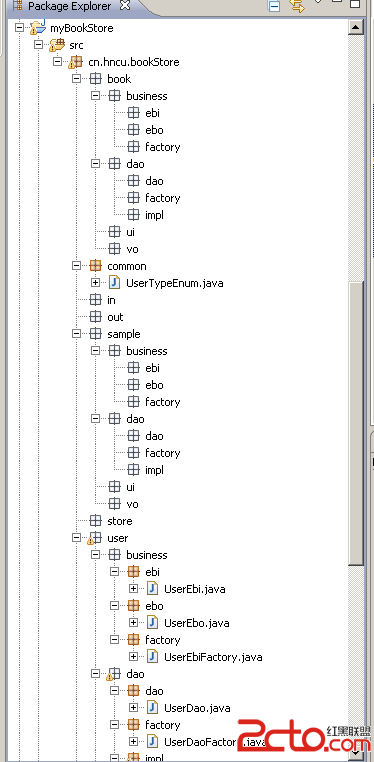
一、抽象過程:
1,萬物皆為對象。
狗、房子這種具體的事物是對象,“服務”這種抽象的概念也是對象。
你可以用對象來存儲東西。狗對象可以存儲狗頭,狗腿等。“服務”對象可以存儲服務類型、服務員、顧客等。
你可以要求對象執行某種操作。比如,讓狗叫一聲,讓“服務”對象做一個“送貨上門”的動作。
2,程序是對象的集合
程序中的各個對象通過發送消息來告訴彼此要做什麼,來合作完成一項任務。比如你調用某個對象的某個方法,“調用”的過程就是“發消息”。
3,一個對象可以由許多其他對象組成。
4,每一個對象都有自己的類型。
比如,A a=new A();那麼,a的類型就是A,“類”就是“類型”。你創建了一個狗對象,那麼,狗對象的類型就是狗。
類與類區分開來的一個重要因素是:“可以發送什麼樣的消息給它”,即:每個類都有自己的方法。
5,某一特定類型的對象可以接收同樣的消息。
接收消息即調用方法。泰迪類、博美類都屬於狗類。上面這句話的意思就是:因為泰迪和博美都是狗,所以,它們都能夠調用狗的“叫”、“跑”等方法。比如:
BoMei和TaiDi繼承了Dog,所以,它們創建的對象可以調用Dog的方法。
這就意味著,我們要編寫BoMei或者TaiDi相關的代碼時,只需要編寫Dog相關代碼就可以,這就是OOP(面向對象設計)中最強有力的概念之一。如下:
我給Dog定義了legs屬性。在test(Dog dog)方法中,我傳入的參數是“Dog”,操作的也是Dog類的屬性。但是當我在16行調用這個方法時,我傳的參數是“BoMei”對象,此時,操作的就是BoMei。
同理,當我們要操作的是TaiDi對象時,給test傳入TaiDi對象就行。我們就不必分別為TaiDi和BoMei再定義一個test(TaiDi ta)、test(BoMei bo)方法。
6,每個對象都是唯一的
對象都有狀態、行為、標識、類型。比如上面的BoMei類,“狀態”就是“變量”,就是“屬性”,上面的BoMei類,legs就是它的“狀態”。行為就是“方法”、“函數”,對應上面的bark()、eat()等。行為可以改變狀態,比如上面的test(Dog dog)改變了legs屬性的值。類型就是對象所屬的類,而“標識”就相當於身份證一樣,這在java中表現為:每個對象在內存中都有唯一的地址。
二、每個對象都有一個接口
蘋果有皮、有核,是甜的,長在樹上。梨也有皮,也有核,也是甜的,也長在樹上。那麼蘋果和梨有很多相似性,被劃分到同一類型:水果類。這個“水果類”就是一個抽象數據類型(所謂的抽象,就是抽取了一些類似的表象東西,比如皮、核、味道、生長環境等)。
抽象數據類型的運作方式與基本數據類型是一致的。比如對於基本數據類型,可以這樣使用:
對於抽象數據類型,可以這樣使用:
創建某一類型的變量(創建對象或者實例),並調用其方法(發送消息或請求,讓它知道該做什麼)。
每個具體的對象又有自己特有的狀態,比如,蘋果的皮是紅的,梨子的皮是綠的。蘋果水分少,梨子水分多等。所以,蘋果、梨都是水果類,但是它們又是水果類中獨立的個體,這些個體就是一個個唯一的對象,那麼對象與類的關系就明了了:每一個對象都屬於定義了特性和行為的某個特定的類。編程系統對待抽象數據類型與對待一般數據類型是一視同仁的,也會作類型檢查等:
蘋果和梨子都能吃,能搾果汁,能制作蘋果罐頭等。吃、搾果汁、制作罐頭這屬於行為(也就是方法,也就是請求),蘋果和梨子都滿足這些特定的請求,那麼這些特定的請求就定義在接口中,而接口也是一種類型:
接口只是定義了可以向某一特定對象發出的請求,那麼具體到蘋果、梨子該發出怎樣的請求,剝皮吃還是不剝皮,搾果汁時要注意什麼,這都是具體請求該有的細節,在蘋果類、梨子類中必須有這些具體的細節方法,這些代碼就構成了“實現”。
三、每個對象都提供服務
不要試圖把所有功能都擁擠在一個對象裡,完成一項服務項目需要各個對象的配合,比如實現一個打印模塊,我們可以定義一個對象專門檢查配置是否正常,另一個對象定義怎樣打印一張4A圖紙,再定義一個對象集合,調用前兩個對象,再加之自己的方法最終把圖紙打印出來。每個對象都可以很好的完成一個任務,但並不試圖做更多的事情。然後這些對象齊心協力去完成一項服務。
上述的“齊心協力”其實就是軟件設計的基本質量要求之一:高內聚。
四、訪問控制
Java用三個關鍵字控制了變量及方法的訪問:public、private、protected。public其他類都可以訪問,private只有本類及類的內部方法能夠訪問,其他類不可見。protected表示只有本類及繼承本類的子類可見,其他不可見。除此之外,Java還有一種默認的訪問權限:包訪問權限,類可以訪問同一個包中的其他類成員。
訪問控制的原因1:讓客戶端程序員(類的調用者)無法觸及他們不該觸及的部分。調用者只需要調用有用的方法,有些變量等是設計者為了實現內部邏輯而使用的,不需要讓客戶端程序員知道。如果把那些私有變量公開化,既會干擾到客戶端程序員的調用思路,也可能被客戶端程序員誤操作而修改了狀態值。
訪問控制的原因2:類庫的設計者可以改變內部的工作方式而不會影響到外部客戶端程序員的調用。
五、組合,聚合,代碼復用
代碼復用是面向對象程序設計語言所提供的最了不起的優點之一。
直接用某個類創建一個對象也屬於復用,下面第6行就是在復用Apple類。
將某個類的對象置於某個新類中(創建一個成員對象),也屬於復用:
上例中是用Fruit、Dog合成了Test類,所以,這個概念稱為:組合(composition)。如果組合是動態發生的,則稱為“聚合(aggregation)”。
什麼是動態發生呢?看:
第7行並沒有創建Apple實例,等到11行調用時,才實例化了Apple,這就是動態發生。
組合的關系是:has-a,即:汽車擁有引擎、公司擁有員工、Test擁有Fruit、Dog。
六、繼承
復制現有的類,然後添加和修改這個復制品來創建新類,這就是繼承。當源類(又叫:父類、超類、基類)發生變動時,被修改的子類也會發生這些變動。
上面Circle繼承了Shape,自然也就繼承了Shape的color屬性,以及getColor()、setColor()方法、draw()方法。在繼承過來的同時,Circle修改了draw()方法,表現出自己與父類不同的地方(這一行為叫做override,即:覆蓋)。當然,Circle也可以添加自己的新方法。
如果我把父類的getColor方法修改一下:
那麼子類的這個方法就跟著發生了改變。
父類含有所有子類所共享的特性和行為。比如上例,color變量是共享的(color屬於特性),draw()方法也是共享的(draw()屬於行為)。
父類與子類有著相同的類型。
從上面代碼可以看出,Circle類型同時也是Shape類型,這個很容易理解,博美是狗,泰迪是狗,圓是圖形,沒毛病。
理解面向對象設計的重要門檻是理解:通過繼承而產生的類型等價性。
使父類與子類產生差異的兩種方法:
1, 添加新方法。(此時,子類與父類的關系是:is like a)
2, 覆蓋。(只覆蓋而不添加新方法的話,子類與父類的關系是:is a)。
七、向上轉型
上面代碼中,test()裡面的參數為父類Shape,調用的也是父類Shape的draw()方法。當在main方法中調用test時,卻傳入了子類Circle對象,test方法也可以正常調用,且這時,調用的是Circle的draw()方法。
經常需要這樣,把一個子類對象當做它的父類型來對待,這樣做的好處是,不依賴特定類型的代碼,也不受添加新類型的影響。比如,下一次你傳入一個正方形子類,那麼test內部就會自動調用正方形的draw()方法。你如果添加一個新類:六角形,然後把六角形對象傳入test,它也能夠正常調用。
面向對象設計語言采用的是“後期綁定”。當test()方法具體調用時,才能確定參數所對應的具體類型。
上述把子類當做父類型的過程叫做“向上轉型,upcasting”。
八、容器
我們有時需要管理很多對象,我們不知道需要多少個對象,不知道這些對象能夠活多久,不知道存儲這些對象需要多大空間,一問三不知。
容器(集合)幫助我們解決了上述問題。我們把對象放入容器中,在任何時候都可以去擴充它。
Java中具有滿足各種需要的容器。比如:List(有序的對象集合),Map(建立對象之間的關聯,也叫映射),Set(每種對象只有一個,不會重復,類似於數學中的集合),當然,還有隊列(先放進去的對象先出來,FIFO)、樹(以任意順序把許多對象放進該容器,當你遍歷時每個值已經排好序)、堆棧(最後放進去的對象先出來,LIFO隊列)等。
對象的關聯比如:
把”張三”與”NAME”關聯,把”17”與”AGE”關聯,這樣,在獲取”張三”時,只需要如下:
1,不同的容器作用不同(接口不同、方法不同)。
比如:下面是Stack(堆棧)的繼承層次及接口方法:
下面是Queue的繼承層次及方法:
二者不在一個繼承樹下,且各自的方法功能不相同。實際上,Stack(堆棧)是一種後進先出的模式,只能在棧頭進行插入與刪除操作。Queue(隊列)是一種先進先出的模式,只能在隊尾進行插入,在隊頭進行刪除。
2,不同的容器性能不同
比如:ArrayList和LinkedList。如果是隨機訪問一個元素,對於ArrayList來說時間是固定的,而LinkedList需要從第一個元素開始查找,直到找到目標元素,如果目標元素在容器的末端,那麼就要花費更多時間。
如果是插入一個元素,對於ArrayList,插入位置後面的元素統統要往後移動一位(想想實際生活中的插隊),而對於LinkedList來說,只需要把插入位置的兩個對象拆開,然後把目標元素加入進來即可(想想實際生活中小朋友們手拉手的情況)。下圖是LinkedList的插入與刪除:
九、泛型,向下轉型
Java中,所有對象都繼承自Object,那麼由向上轉型規律可知,能存放Object的容器,就能存放任何Java對象。
其實容器裡放置的並不是對象本身,而只是對象的”引用”,指向對象的地址。
當你把一個非Object對象(比如String)的引用放進一個容器時,由於該容器只能存放Object引用,所以,它將會強制轉成Object引用。那麼當你再次取出該引用時,就變成了Object引用,而不是你想要的String。如下:
雖然存入List中的是dog的引用,而把它賦值給dog2時,卻報錯,因為dog.get(0)取出來的是Object類型的引用。這時,就要用到向下轉型。
向上轉型是把子類當作父類來用,而向下轉型是把父類型轉換為一個更具體的類型:
比如上圖,把Object引用強制轉換為Dog。
向上轉型是安全的,比如你可以大膽的說:蘋果是水果,梨子是水果,所以,你可以大膽的把任何對象強制轉成Object:
向下轉型卻是不安全的,你只知道它是一條狗,但是你不知它具體是什麼種類:
上例把泰迪放入List,取出來時是Object,卻錯誤的把它轉換成博美,結果發生了錯誤。
為了避免上面種種風險的發生,Java中引入了泛型:
如上圖,明確說明List狗窩中只能放泰迪,那麼你放入博美就會直接報錯。
如上圖,我已經知道List狗窩裡面睡的是泰迪,你取出來把它喊成博美,那麼也會報錯。
十、對象的生命周期
出生:
當你每次new一個對象時,Java就動態地在一個稱為“堆”的內存池中創建一個對象。由於是動態的,所以,直到運行時才能知道要創建多少個對象,對象的生命周期是什麼,以及對象的具體類型是什麼。再搬出前面出現過的一段代碼來加深對“動態”的了解:
上例中,直到運行test()時才會創建Apple實例。
死亡:
Java的垃圾回收機制會自動發現對象什麼時候不用了,然後去銷毀它,以達到釋放內存的目的。
Java判斷某個對象是否可以回收是一件復雜的事情。比如,一般情況下,創建一個對象,會在堆中生成一個對象,而會在棧中放一個該對象的引用(一個數字,指向這個對象在堆中的地址),垃圾回收器有一種早期策略,每生成一個引用,計數器就會+1,而每減少一個引用,計數器就會-1,當發現計數器為0時,說明該對象可以回收了。如下圖:
圖中第四步,per2指向了per1引用的地址,那麼就沒有引用指向age=20的那個對象了,於是,那個對象會被垃圾回收器回收。
十一、異常處理
異常是一種對象,當程序發生錯誤時,它從那個錯誤點“拋出”,然後由該錯誤對應的專門的處理器“抓住”。所以,如果代碼是正常的,異常代碼將不會發生。
有些異常是在運行的時候才能發現的,主要是由於程序員的失誤造成的,這類異常叫做“運行時異常”,比如:
你明知道test不能轉成整數,還非要轉,運行時就會報錯。
還有一種異常,叫“非運行時異常”,就是運行前就該有所防范的,比如想從某個路徑下加載一個文件,這種情況下,就有找不到這個文件的可能性,那麼,你必須做出防患於未然,可以拋出異常:
也可以捕獲異常:
十二、並發編程
為了提高響應能力,我們想把一個任務分成多個子任務獨立的運行,讓他們一起干活。這些獨立運行的子任務就是”線程”,而“一起干活”就是“並發”。
實際上,在單一處理器環境中,線程之間是輪番交叉運行的,由處理器來分給每個線程時間。而在多處理器上才存在真正的”一起干活”,即“並行”。
多線程並發完成一項工作的過程中,資源共享就帶來隱患,比如桌子上有一個粉筆(資源),兩個小朋友(線程)同時伸手去拿粉筆(搶占資源),那麼就會打起來。所以,就要有一種機制,當一個小朋友要去拿粉筆時,先把粉筆保護起來(加鎖),等這個小朋友不用了,再釋放鎖,另一個小朋友才可以用粉筆。
更多內容請關注: