數據結構中有數組和鏈表來實現對數據的存儲,但是數組存儲區間是連續的,尋址容易,插入和刪除困難;而鏈表的空間是離散的,因此尋址困難,插入和刪除容易。
因此,綜合了二者的優勢,我們可以設計一種數據結構——哈希表(hash table),它尋址、插入和刪除都很方便。在java中,哈希表的實現主要就是HashMap了,可以說HashMap是java開發中使用最多的類之一吧。
HashMap的底層其實就是鏈表的數組,代碼為
transient Entry[] table;
這裡的table其實就是一個鏈表的數組,因為我們的數據是二元的,因此HashMap定義了一個內部的類Entry,它包含了key和value兩個屬性。這樣一個一維的線性數組就可以存儲兩個值了。同時Entry是一個鏈表,因此還有一個Entry next屬性,它指向了下一個節點。
存儲put時:
首先計算出key的hash,然後用table[hash]得到那個鏈表,再遍歷這個鏈表,如果鏈表中有一個key和這個key是滿足equals的話,則將value替換掉;如果沒有的話,則插入到鏈表的尾部。
int h = hash(key); Entry e = table[h];
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在鏈表中已存在,則替換為新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
在get時,也是以同樣的方法得到那個鏈表Entry e;然後遍歷這個鏈表取出元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
HashMap對性能的優化:
HashMap對性能優化,主要是在於減少hash沖突(不同的key算出同樣的hash),因為hash沖突越多,從鏈表中需要的尋址時間就越長。
1.通過計算hash值的方式減少hash沖突:
這個hash方法有效的減少了hash沖突:(具體我確實不懂!大家參考http://zhangshixi.iteye.com/blog/672697)
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
我自己寫了一個非常簡單計算hash值的方式,勉強能用:
Math.abs(o==null?0:o.hashCode()) % length
2.自動擴容
當HashMap中的元素越來越多的時候,hash沖突的幾率也就越來越高,因為數組的長度是固定的。因此,此時就需要對數組進行擴容了。
當HashMap中的元素個數超過數組大小*loadFactor(默認值0.75)時,就會進行數組擴容。這時,需要創建一張新表,將原表的映射到新表中。
擴容時,遍歷每個元素,重新計算其hash值,然後加入新表中。
一般來說,擴容數組的大小為原數組大小的兩倍。而這是一個很耗性能的操作,因此,如果我們已經預知HashMap中元素的個數,那麼提前設置初始容量將大大提升其性能。
我將我的源碼放到了github上,歡迎大家下載交流。
http://pan.baidu.com/s/1dFj2405
https://github.com/xcr1234/my-java
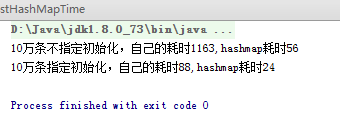
附上自己實現的性能測試結果,勉強能接受
這篇博文和代碼肯定還有很多不足的地方,也請各位大神指出!或者fork我的代碼並提出寶貴的建議,謝謝!