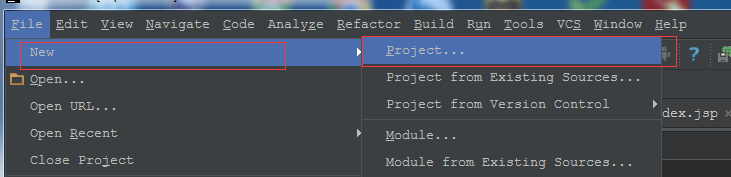
Application ID is application_1481285758114_422243, trackingURL: http://***:4040
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://mycluster-tj/user/engine_arch/data/mllib/sample_libsvm_data.txt
at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:287)
at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:229)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:315)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:199)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1994)
at org.apache.spark.rdd.RDD$$anonfun$reduce$1.apply(RDD.scala:1025)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.reduce(RDD.scala:1007)
at org.apache.spark.mllib.util.MLUtils$.loadLibSVMFile(MLUtils.scala:105)
at org.apache.spark.mllib.util.MLUtils$.loadLibSVMFile(MLUtils.scala:134)
at org.apache.spark.ml.source.libsvm.LibSVMRelation.buildScan(LibSVMRelation.scala:49)
at org.apache.spark.sql.execution.datasources.DataSourceStrategy$.apply(DataSourceStrategy.scala:135)
at org.apache.spark.sql.catalyst.planning.QueryPlanner$$anonfun$1.apply(QueryPlanner.scala:58)
at org.apache.spark.sql.catalyst.planning.QueryPlanner$$anonfun$1.apply(QueryPlanner.scala:58)
at scala.collection.Iterator$$anon$13.hasNext(Iterator.scala:371)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:59)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.planLater(QueryPlanner.scala:54)
at org.apache.spark.sql.execution.SparkStrategies$BasicOperators$.apply(SparkStrategies.scala:336)
at org.apache.spark.sql.catalyst.planning.QueryPlanner$$anonfun$1.apply(QueryPlanner.scala:58)
at org.apache.spark.sql.catalyst.planning.QueryPlanner$$anonfun$1.apply(QueryPlanner.scala:58)
at scala.collection.Iterator$$anon$13.hasNext(Iterator.scala:371)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:59)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan$lzycompute(QueryExecution.scala:47)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan(QueryExecution.scala:45)
at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:52)
at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:52)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:55)
at org.apache.spark.sql.DataFrame.rdd$lzycompute(DataFrame.scala:1638)
at org.apache.spark.sql.DataFrame.rdd(DataFrame.scala:1635)
at org.apache.spark.sql.DataFrame.map(DataFrame.scala:1411)
at org.apache.spark.ml.feature.StandardScaler.fit(StandardScaler.scala:90)
at com.xiaoju.arch.engine.spark.SparkDD.buildStandardScaler(SparkDD.java:149)
at com.xiaoju.arch.engine.spark.StandardScalerDemo.main(StandardScalerDemo.java:13)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
spark中讀取文件,在yarn模式下,必須將文件存入hdfs中,不然就會報錯。單機模式下無此問題。