之前我們介紹了Map接口的兩個實現類HashMap和TreeMap,本節來介紹另一個實現類LinkedHashMap。它是HashMap的子類,但可以保持元素按插入或訪問有序,這與TreeMap按鍵排序不同。
按插入有序容易理解,按訪問有序是什麼意思呢?這兩個有序有什麼用呢?內部是怎麼實現的呢?本節就來探討這些問題。從用法開始。
用法
基本概念
LinkedHashMap是HashMap的子類,但內部還有一個雙向鏈表維護鍵值對的順序,每個鍵值對既位於哈希表中,也位於這個雙向鏈表中。
LinkedHashMap支持兩種順序,一種是插入順序,另外一種是訪問順序。
插入順序容易理解,先添加的在前面,後添加的在後面,修改操作不影響順序。
訪問順序是什麼意思呢?所謂訪問是指get/put操作,對一個鍵執行get/put操作後,其對應的鍵值對會移到鏈表末尾,所以,最末尾的是最近訪問的,最開始的最久沒被訪問的,這種順序就是訪問順序。
LinkedHashMap有五個構造方法,其中四個都是按插入順序,如下所示:
public LinkedHashMap() public LinkedHashMap(int initialCapacity) public LinkedHashMap(int initialCapacity, float loadFactor) public LinkedHashMap(Map<? extends K, ? extends V> m)
只有一個構造方法,可以指定按訪問順序,如下所示:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder)
其中參數accessOrder就是用來指定是否按訪問順序,如果為true,就是訪問順序。
下面,我們通過一些簡單的例子來看下。
按插入有序
默認情況下,LinkedHashMap是按插入有序的,我們來看代碼:
Map<String,Integer> seqMap = new LinkedHashMap<>();
seqMap.put("c", 100);
seqMap.put("d", 200);
seqMap.put("a", 500);
seqMap.put("d", 300);
for(Entry<String,Integer> entry : seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
鍵是按照"c", "d", "a"的順序插入的,修改"d"的值不會修改順序,所以輸出為:
c 100 d 300 a 500
什麼時候希望保持插入順序呢?
Map經常用來處理一些數據,其處理模式是,接受一些鍵值對作為輸入,處理,然後輸出,輸出時希望保持原來的順序。比如一個配置文件,其中有一些鍵值對形式的配置項,但其中有一些鍵是重復的,希望保留最後一個值,但還是按原來的鍵順序輸出,LinkedHashMap就是一個合適的數據結構。
再比如,希望的數據模型可能就是一個Map,但希望保持添加的順序,比如一個購物車,鍵為購買項目,值為購買數量,按用戶添加的順序保存。
另外一種常見的場景是,希望Map能夠按鍵有序,但在添加到Map前,鍵已經通過其他方式排好序了,這時,就沒有必要使用TreeMap了,畢竟TreeMap的開銷要大一些。比如,在從數據庫查詢數據放到內存時,可以使用SQL的order by語句讓數據庫對數據排序。
按訪問有序
我們來看按訪問有序的例子,代碼如下:
Map<String,Integer> accessMap = new LinkedHashMap<>(16, 0.75f, true);
accessMap.put("c", 100);
accessMap.put("d", 200);
accessMap.put("a", 500);
accessMap.get("c");
accessMap.put("d", 300);
for(Entry<String,Integer> entry : accessMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
每次訪問都會將該鍵值對移到末尾,所以輸出為:
a 500 c 100 d 300
什麼時候希望按訪問有序呢?一種典型的應用是LRU緩存,它是什麼呢?
LRU緩存
緩存是計算機技術中一種非常有用的技術,是一個通用的提升數據訪問性能的思路,一般用來保存常用的數據,容量較小,但訪問更快,緩存是相對而言的,相對的是主存,主存的容量更大、但訪問更慢。緩存的基本假設是,數據會被多次訪問,一般訪問數據時,都先從緩存中找,緩存中沒有再從主存中找,找到後,再放入緩存,這樣,下次如果再找相同數據,訪問就快了。
緩存用於計算機技術的各個領域,比如CPU裡有緩存,有一級緩存、二級緩存、三級緩存等,一級緩存非常小、非常貴、也非常快,三級緩存則大一些、便宜一些、也慢一些,CPU緩存是相對於內存而言,它們都比內存快。內存裡也有緩存,內存的緩存一般是相對於硬盤數據而言的。硬盤也可能是緩存,緩存網絡上其他機器的數據,比如浏覽器訪問網頁時,會把一些網頁緩存到本地硬盤。
LinkedHashMap可以用於緩存,比如緩存用戶基本信息,鍵是用戶Id,值是用戶信息,所有用戶的信息可能保存在數據庫中,部分活躍用戶的信息可能在緩存。
一般而言,緩存容量有限,不能無限存儲所有數據,如果緩存滿了,當需要存儲新數據時,就需要一定的策略將一些老的數據清理出去,這個策略一般稱為替換算法。LRU是一種流行的替換算法,它的全稱是Least Recently Used,最近最少使用,它的思路是,最近剛被使用的很快再次被用的可能性最高,而最久沒被訪問的很快再次被用的可能性最低,所以被優先清理。
使用LinkedHashMap,可以非常容易的實現LRU緩存,默認情況下,LinkedHashMap沒有對容量做限制,但它可以容易的做的,它有一個protected方法,如下所示:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
在添加元素到LinkedHashMap後,LinkedHashMap會調用這個方法,傳遞的參數是最久沒被訪問的鍵值對,如果這個方法返回true,則這個最久的鍵值對就會被刪除。LinkedHashMap的實現總是返回false,所有容量沒有限制,但子類可以重寫該方法,在滿足一定條件的情況,返回true。
下面就是一個簡單的LRU緩存的實現,它有一個容量限制,這個限制在構造方法中傳遞,代碼是:
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private int maxEntries;
public LRUCache(int maxEntries){
super(16, 0.75f, true);
this.maxEntries = maxEntries;
}
@Override
protected boolean removeEldestEntry(Entry<K, V> eldest) {
return size() > maxEntries;
}
}
這個緩存可以這麼用:
LRUCache<String,Object> cache = new LRUCache<>(3);
cache.put("a", "abstract");
cache.put("b", "basic");
cache.put("c", "call");
cache.get("a");
cache.put("d", "call");
System.out.println(cache);
限定緩存容量為3,先後添加了4個鍵值對,最久沒被訪問的鍵是"b",會被刪除,所以輸出為:
{c=call, a=abstract, d=call}
實現原理
理解了LinkedHashMap的用法,下面我們來看其實現代碼。關於代碼,我們說明下,本系列文章,如果沒有額外說明,都是基於JDK 7的。
內部組成
LinkedHashMap是HashMap的子類,內部增加了如下實例變量:
private transient Entry<K,V> header; private final boolean accessOrder;
accessOrder表示是按訪問順序還是插入順序。header表示雙向鏈表的頭,它的類型Entry是一個內部類,這個類是HashMap.Entry的子類,增加了兩個變量before和after,指向鏈表中的前驅和後繼,Entry的完整定義為:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
recordAccess和recordRemoval是HashMap.Entry中定義的方法,在HashMap中,這兩個方法的實現為空,它們就是被設計用來被子類重寫的,在put被調用且鍵存在時,HashMap會調用Entry的recordAccess方法,在鍵被刪除時,HashMap會調用Entry的recordRemoval方法。
LinkedHashMap.Entry重寫了這兩個方法,在recordAccess中,如果是按訪問順序的,則將該節點移到鏈表的末尾,在recordRemoval中,將該節點從鏈表中移除。
了解了內部組成,我們來看操作方法,先看構造方法。
構造方法
在HashMap的構造方法中,會調用init方法,init方法在HashMap的實現中為空,也是被設計用來被重寫的。LinkedHashMap重寫了該方法,用於初始化鏈表的頭節點,代碼如下:
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
header被初始化為一個Entry對象,前驅和後繼都指向自己,如下圖所示:
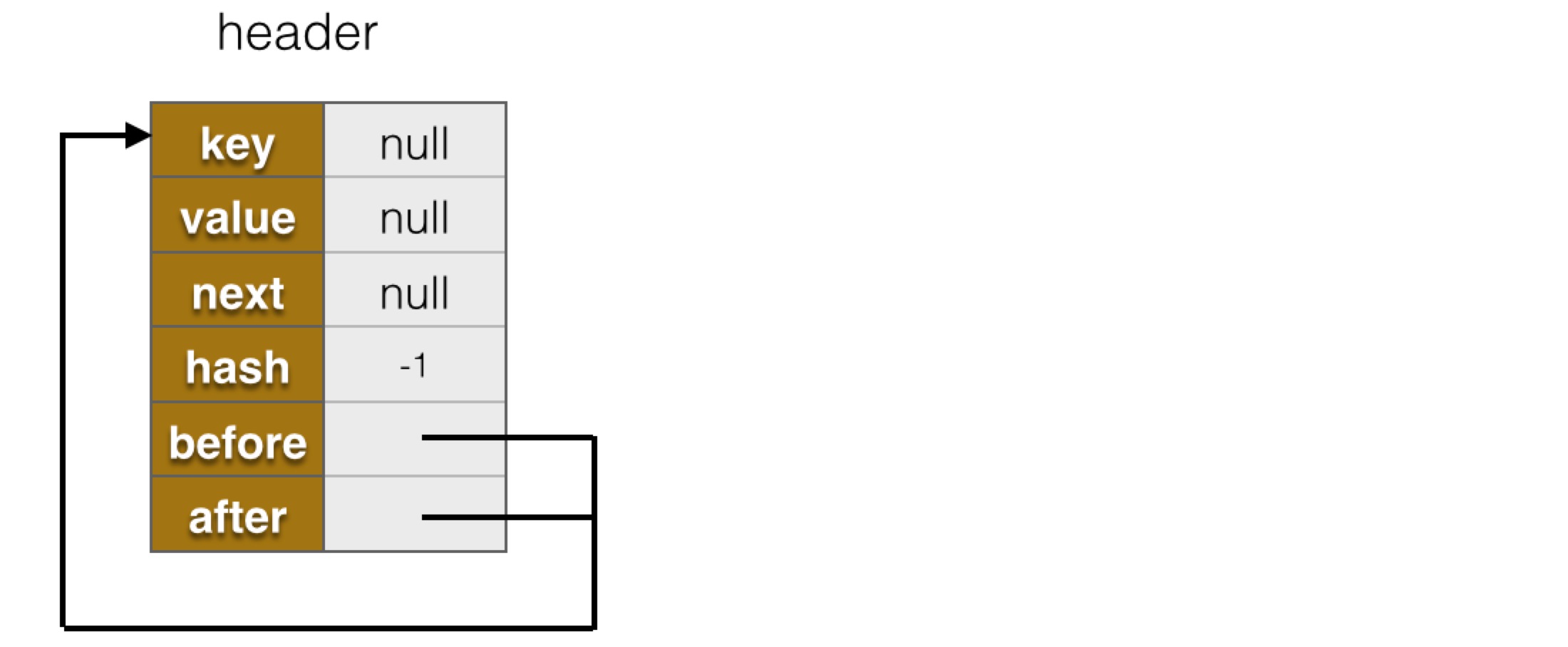
header.after指向第一個節點,header.before指向最後一個節點,指向header表示鏈表為空。
put方法
在LinkedHashMap中,put方法還會將節點加入到鏈表中來,如果是按訪問有序的,還會調整節點到末尾,並根據情況刪除最久沒被訪問的節點。
HashMap的put實現中,如果是新的鍵,會調用addEntry方法添加節點,LinkedHashMap重寫了該方法,代碼為:
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
它先調用父類的addEntry方法,父類的addEntry會調用createEntry創建節點,LinkedHashMap重寫了createEntry,代碼為:
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
新建節點,加入哈希表中,同時加入鏈表中,加到鏈表末尾的代碼是:
e.addBefore(header)
比如,執行如下代碼:
Map<String,Integer> countMap = new LinkedHashMap<>();
countMap.put("hello", 1);
執行後,圖示結構如下:
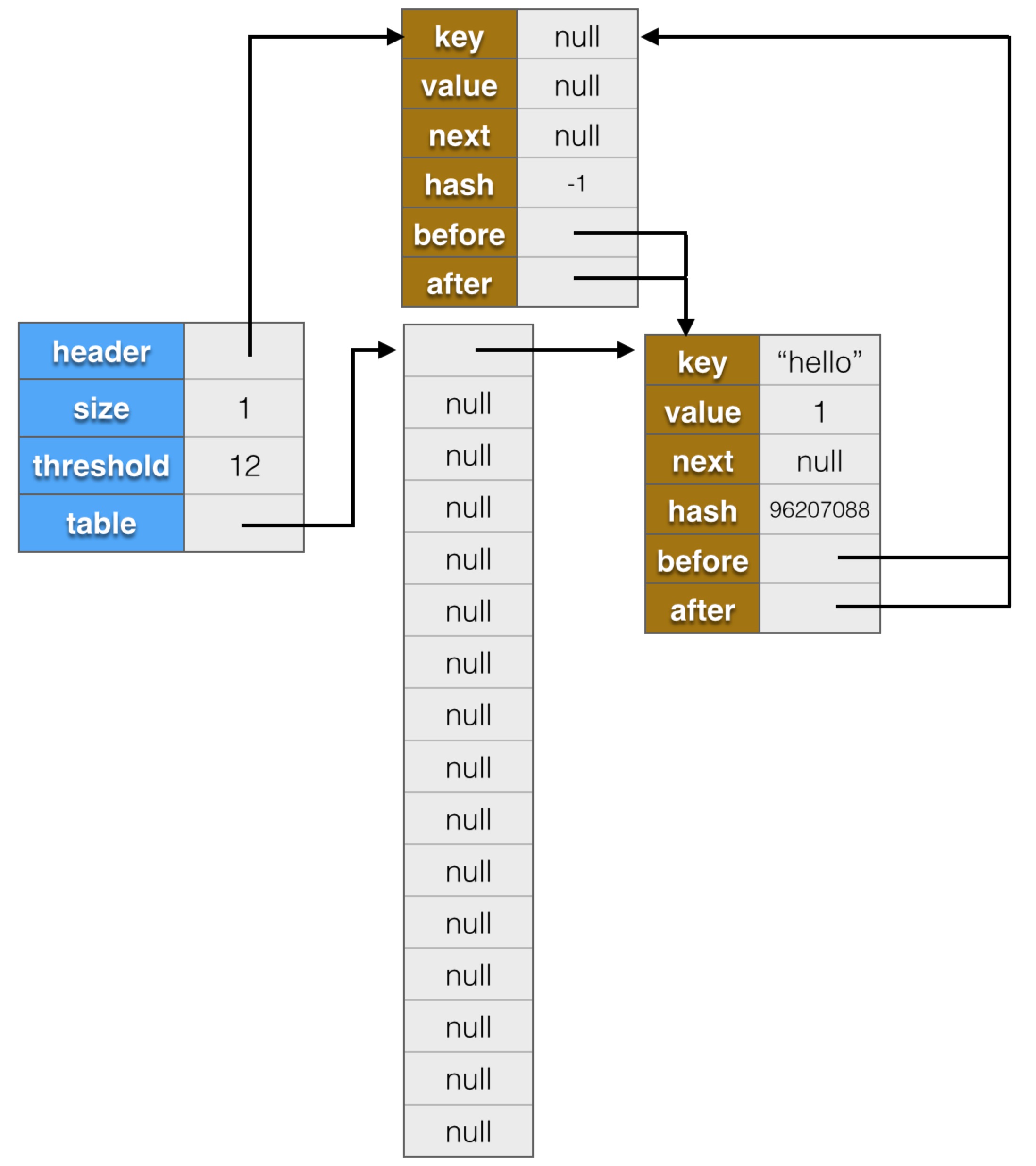
添加完後,調用removeEldestEntry檢查是否應該刪除老節點,如果返回值為true,則調用removeEntryForKey進行刪除,removeEntryForKey是HashMap中定義的方法,刪除節點時會調用HashMap.Entry的recordRemoval方法,該方法被LinkedHashMap.Entry重寫了,會將節點從鏈表中刪除。
在HashMap的put實現中,如果鍵已經存在了,則會調用節點的recordAccess方法,LinkedHashMap.Entry重寫了該方法,如果是按訪問有序,則調整該節點到鏈表末尾。
get方法
LinkedHashMap重寫了get方法,代碼為:
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
與HashMap的get方法的區別,主要是調用了節點的recordAccess方法,如果是按訪問有序,recordAccess調整該節點到鏈表末尾。
查看是否包含某個值
查看HashMap中是否包含某個值需要進行遍歷,由於LinkedHashMap維護了單獨的鏈表,它可以使用鏈表進行更為高效的遍歷,containsValue的代碼為:
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}
代碼比較簡單,就不解釋了。
原理小結
以上就是LinkedHashMap的基本實現原理,它是HashMap的子類,它的節點類LinkedHashMap.Entry是HashMap.Entry的子類,LinkedHashMap內部維護了一個單獨的雙向鏈表,每個節點即位於哈希表中,也位於雙向鏈表中,在鏈表中的順序默認是插入順序,也可以配置為訪問順序,LinkedHashMap及其節點類LinkedHashMap.Entry重寫了若干方法以維護這種關系。
LinkedHashSet
之前介紹的Map接口的實現類都有一個對應的Set接口的實現類,比如HashMap有HashSet,TreeMap有TreeSet,LinkedHashMap也不例外,它也有一個對應的Set接口的實現類LinkedHashSet。LinkedHashSet是HashSet的子類,但它內部的Map的實現類是LinkedHashMap,所以它也可以保持插入順序,比如:
Set<String> set = new LinkedHashSet<>();
set.add("b");
set.add("c");
set.add("a");
set.add("c");
System.out.println(set);
輸出為:
[b, c, a]
LinkedHashSet的實現比較簡單,我們就不再介紹了。
小結
本節主要介紹了LinkedHashMap的用法和實現原理,用法上,它可以保持插入順序或訪問順序,插入順序經常用於處理鍵值對的數據,並保持其輸入順序,也經常用於鍵已經排好序的場景,相比TreeMap效率更高,訪問順序經常用於實現LRU緩存。實現原理上,它是HashMap的子類,但內部有一個雙向鏈表以維護節點的順序。
最後,我們簡單介紹了LinkedHashSet,它是HashSet的子類,但內部使用LinkedHashMap。
如果需要一個Map的實現類,並且鍵的類型為枚舉類型,可以使用HashMap,但應該使用一個專門的實現類EnumMap,為什麼呢?讓我們下節來探討。
----------------
未完待續,查看最新文章,敬請關注微信公眾號“老馬說編程”(掃描下方二維碼),從入門到高級,深入淺出,老馬和你一起探索Java編程及計算機技術的本質。用心原創,保留所有版權。