前面兩節介紹了ArrayList和LinkedList,它們的一個共同特點是,查找元素的效率都比較低,都需要逐個進行比較,本節介紹HashMap,它的查找效率則要高的多,HashMap是什麼?怎麼用?是如何實現的?本節詳細介紹。
字面上看,HashMap由兩個單詞組成,Hash和Map,這裡Map不是地圖的意思,而是表示映射關系,是一個接口,實現Map接口有多種方式,HashMap實現的方式利用了Hash。
下面,我們先來看Map接口,接著看如何使用HashMap,然後看實現原理,最後我們總結分析HashMap的特點。
Map接口
基本概念
Map有鍵和值的概念,一個鍵映射到一個值,Map按照鍵存儲和訪問值,鍵不能重復,即一個鍵只會存儲一份,給同一個鍵重復設值會覆蓋原來的值。使用Map可以方便地處理需要根據鍵訪問對象的場景,比如:
數組、ArrayList、LinkedList可以視為一種特殊的Map,鍵為索引,值為對象。
接口定義
Map接口的定義為:
public interface Map<K,V> {
V put(K key, V value);
V get(Object key);
V remove(Object key);
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
}
boolean equals(Object o);
int hashCode();
}
Map接口有兩個類型參數,K和V,分別表示鍵(Key)和值(Value)的類型,我們解釋一下其中的方法。
保存鍵值對
V put(K key, V value);
按鍵key保存值value,如果Map中原來已經存在key,則覆蓋對應的值,返回值為原來的值,如果原來不存在key,返回null。key相同的依據是,要麼都為null,要麼equals方法返回true。
根據鍵獲取值
V get(Object key);
如果沒找到,返回null。
根據鍵刪除鍵值對
V remove(Object key);
返回key原來對應的值,如果Map中不存在key,返回null。
查看Map的大小
int size(); boolean isEmpty();
查看是否包含某個鍵
boolean containsKey(Object key);
查看是否包含某個值
boolean containsValue(Object value);
批量保存
void putAll(Map<? extends K, ? extends V> m);
保存參數m中的所有鍵值對到當前Map。
清空Map中所有鍵值對
void clear();
獲取Map中鍵的集合
Set<K> keySet();
Set是一個接口,表示的是數學中的集合概念,即沒有重復的元素集合,它的定義為:
public interface Set<E> extends Collection<E> {
}
它擴展了Collection,但沒有定義任何新的方法,不過,它要求所有實現者都必須確保Set的語義約束,即不能有重復元素。關於Set,下節我們再詳細介紹。
Map中的鍵是沒有重復的,所以ketSet()返回了一個Set。
獲取Map中所有值的集合
Collection<V> values();
獲取Map中的所有鍵值對
Set<Map.Entry<K, V>> entrySet();
Map.Entry<K,V>是一個嵌套接口,定義在Map接口內部,表示一條鍵值對,主要方法有:
K getey(); V getValue();
keySet()/values()/entrySet()有一個共同的特點,它們返回的都是視圖,不是拷貝的值,基於返回值的修改會直接修改Map自身,比如說:
map.keySet().clear();
會刪除所有鍵值對。
HashMap
使用例子
HashMap實現了Map接口,我們通過一個簡單的例子,來看如何使用。
在隨機一節,我們介紹過如何產生隨機數,現在,我們寫一個程序,來看隨機產生的數是否均勻,比如,隨機產生1000個0到3的數,統計每個數的次數。代碼可以這麼寫:
Random rnd = new Random();
Map<Integer, Integer> countMap = new HashMap<>();
for(int i=0; i<1000; i++){
int num = rnd.nextInt(4);
Integer count = countMap.get(num);
if(count==null){
countMap.put(num, 1);
}else{
countMap.put(num, count+1);
}
}
for(Map.Entry<Integer, Integer> kv : countMap.entrySet()){
System.out.println(kv.getKey()+","+kv.getValue());
}
一次運行的輸出為:
0,269 1,236 2,261 3,234
代碼比較簡單,就不解釋了。
構造方法
除了默認構造方法,HashMap還有如下構造方法:
public HashMap(int initialCapacity) public HashMap(int initialCapacity, float loadFactor) public HashMap(Map<? extends K, ? extends V> m)
最後一個以一個已有的Map構造,拷貝其中的所有鍵值對到當前Map,這容易理解。前兩個涉及兩個兩個參數initialCapacity和loadFactor,它們是什麼意思呢?我們需要看下HashMap的實現原理。
實現原理
內部組成
HashMap內部有如下幾個主要的實例變量:
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; transient int size; int threshold; final float loadFactor;
size表示實際鍵值對的個數。
table是一個Entry類型的數組,其中的每個元素指向一個單向鏈表,鏈表中的每個節點表示一個鍵值對,Entry是一個內部類,它的實例變量和構造方法代碼如下:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
其中key和value分別表示鍵和值,next指向下一個Entry節點,hash是key的哈希值,待會我們會介紹其計算方法,直接存儲hash值是為了在比較的時候加快計算,待會我們看代碼。
table的初始值為EMPTY_TABLE,是一個空表,具體定義為:
static final Entry<?,?>[] EMPTY_TABLE = {};
當添加鍵值對後,table就不是空表了,它會隨著鍵值對的添加進行擴展,擴展的策略類似於ArrayList,添加第一個元素時,默認分配的大小為16,不過,並不是size大於16時再進行擴展,下次什麼時候擴展與threshold有關。
threshold表示阈值,當鍵值對個數size大於等於threshold時考慮進行擴展。threshold是怎麼算出來的呢?一般而言,threshold等於table.length乘以loadFactor,比如,如果table.length為16,loadFactor為0.75,則threshold為12。
loadFactor是負載因子,表示整體上table被占用的程度,是一個浮點數,默認為0.75,可以通過構造方法進行修改。
下面,我們通過一些主要方法的代碼來看下,HashMap是如何利用這些內部數據實現Map接口的。先看默認構造方法。需要說明的是,為清晰和簡單起見,我們可能會忽略一些非主要代碼。
默認構造方法
代碼為:
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
DEFAULT_INITIAL_CAPACITY為16,DEFAULT_LOAD_FACTOR為0.75,默認構造方法調用的構造方法主要代碼為:
public HashMap(int initialCapacity, float loadFactor) {
this.loadFactor = loadFactor;
threshold = initialCapacity;
}
主要就是設置loadFactor和threshold的初始值。
保存鍵值對
下面,我們來看HashMap是如何把一個鍵值對保存起來的,代碼為:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
如果是第一次保存,首先會調用inflateTable()方法給table分配實際的空間,inflateTable的主要代碼為:
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
}
默認情況下,capacity的值為16,threshold會變為12,table會分配一個長度為16的Entry數組。
接下來,檢查key是否為null,如果是,調用putForNullKey單獨處理,我們暫時忽略這種情況。
在key不為null的情況下,下一步調用hash方法計算key的哈希值,hash方法的代碼為:
final int hash(Object k) {
int h = 0
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
基於key自身的hashCode方法的返回值,又進行了一些位運算,目的是為了隨機和均勻性。
有了hash值之後,調用indexFor方法,計算應該將這個鍵值對放到table的哪個位置,代碼為:
static int indexFor(int h, int length) {
return h & (length-1);
}
HashMap中,length為2的冪次方,h&(length-1)等同於求模運算:h%length。
找到了保存位置i,table[i]指向一個單向鏈表,接下來,就是在這個鏈表中逐個查找是否已經有這個鍵了,遍歷代碼為:
for (Entry<K,V> e = table[i]; e != null; e = e.next)
而比較的時候,是先比較hash值,hash相同的時候,再使用equals方法進行比較,代碼為:
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
為什麼要先比較hash呢?因為hash是整數,比較的性能一般要比equals比較高很多,hash不同,就沒有必要調用equals方法了,這樣整體上可以提高比較性能。
如果能找到,直接修改Entry中的value即可。
modCount++的含義與ArrayList和LinkedList中介紹一樣,記錄修改次數,方便在迭代中檢測結構性變化。
如果沒找到,則調用addEntry方法在給定的位置添加一條,代碼為:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
如果空間是夠的,不需要resize,則調用createEntry添加,createEntry的代碼為:
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
代碼比較直接,新建一個Entry對象,並插入單向鏈表的頭部,並增加size。
如果空間不夠,即size已經要超過阈值threshold了,並且對應的table位置已經插入過對象了,具體檢查代碼為:
if ((size >= threshold) && (null != table[bucketIndex]))
則調用resize方法對table進行擴展,擴展策略是乘2,resize的主要代碼為:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
分配一個容量為原來兩倍的Entry數組,調用transfer方法將原來的鍵值對移植過來,然後更新內部的table變量,以及threshold的值。transfer方法的代碼為:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
參數rehash一般為false。這段代碼遍歷原來的每個鍵值對,計算新位置,並保存到新位置,具體代碼比較直接,就不解釋了。
以上,就是保存鍵值對的主要代碼,簡單總結一下,基本步驟為:
以上描述可能比較抽象,我們通過一個例子,用圖示的方式,再來看下,代碼是:
Map<String,Integer> countMap = new HashMap<>();
countMap.put("hello", 1);
countMap.put("world", 3);
countMap.put("position", 4);
在通過new HashMap()創建一個對象後,內存中的圖示結構大概是:

接下來執行
countMap.put("hello", 1);
"hello"的hash值為96207088,模16的結果為0,所以插入table[0]指向的鏈表頭部,內存結構會變為:
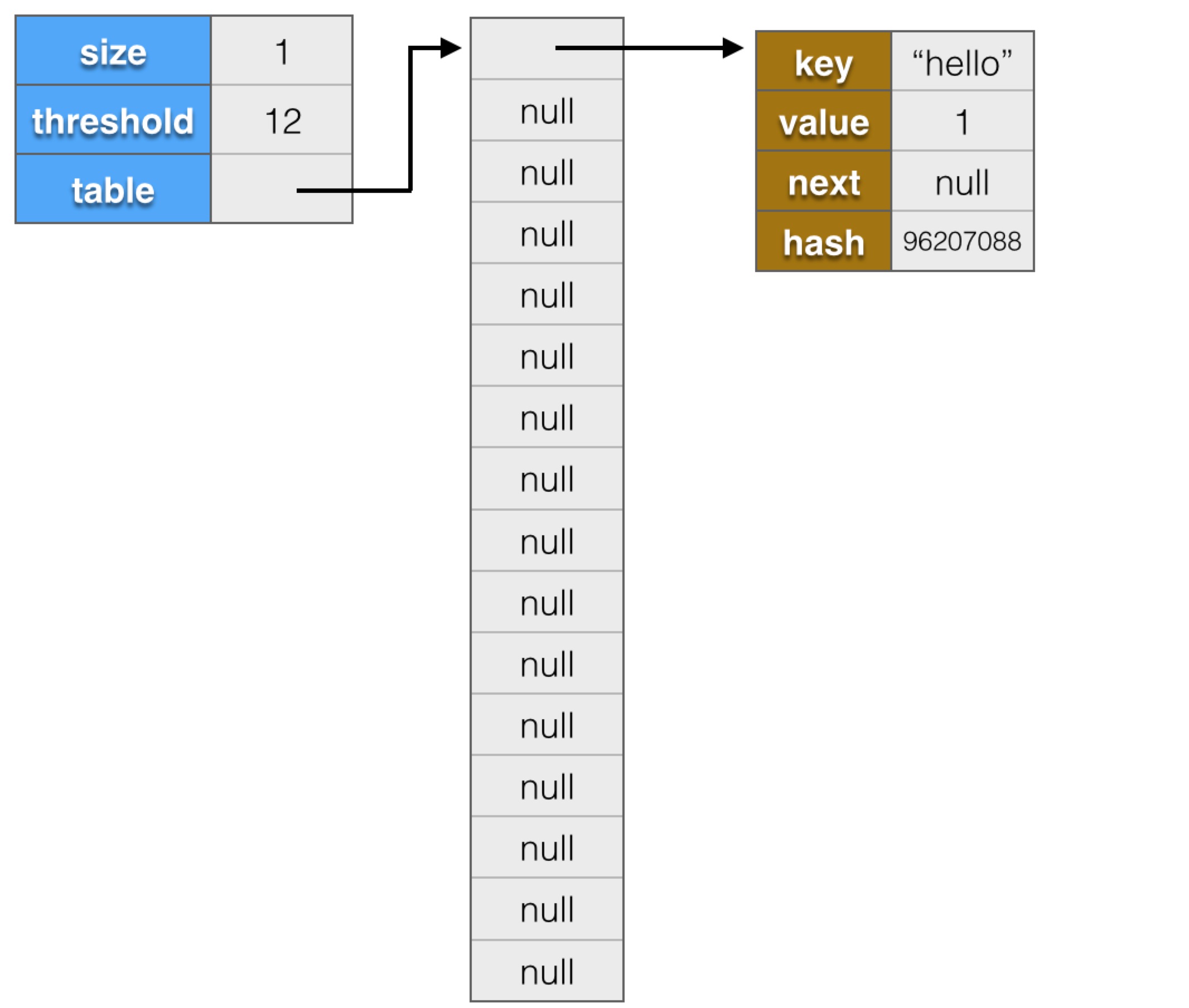
"world"的hash值為111207038,模16結果為15,所以保存完"world"後,內存結構會變為:
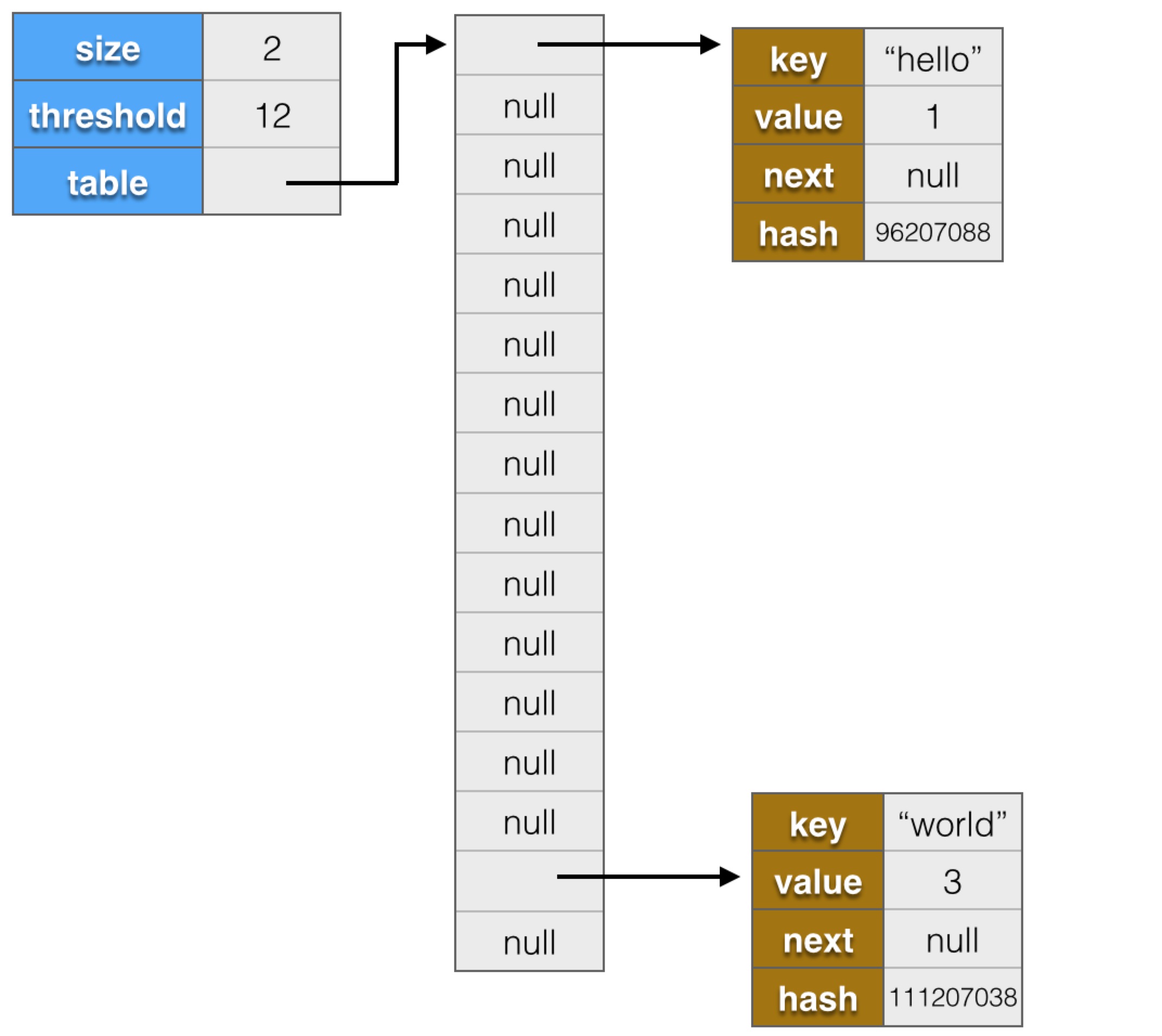
"position"的hash值為771782464,模16結果也為0,table[0]已經有節點了,新節點會插到鏈表頭部,內存結構會變為:
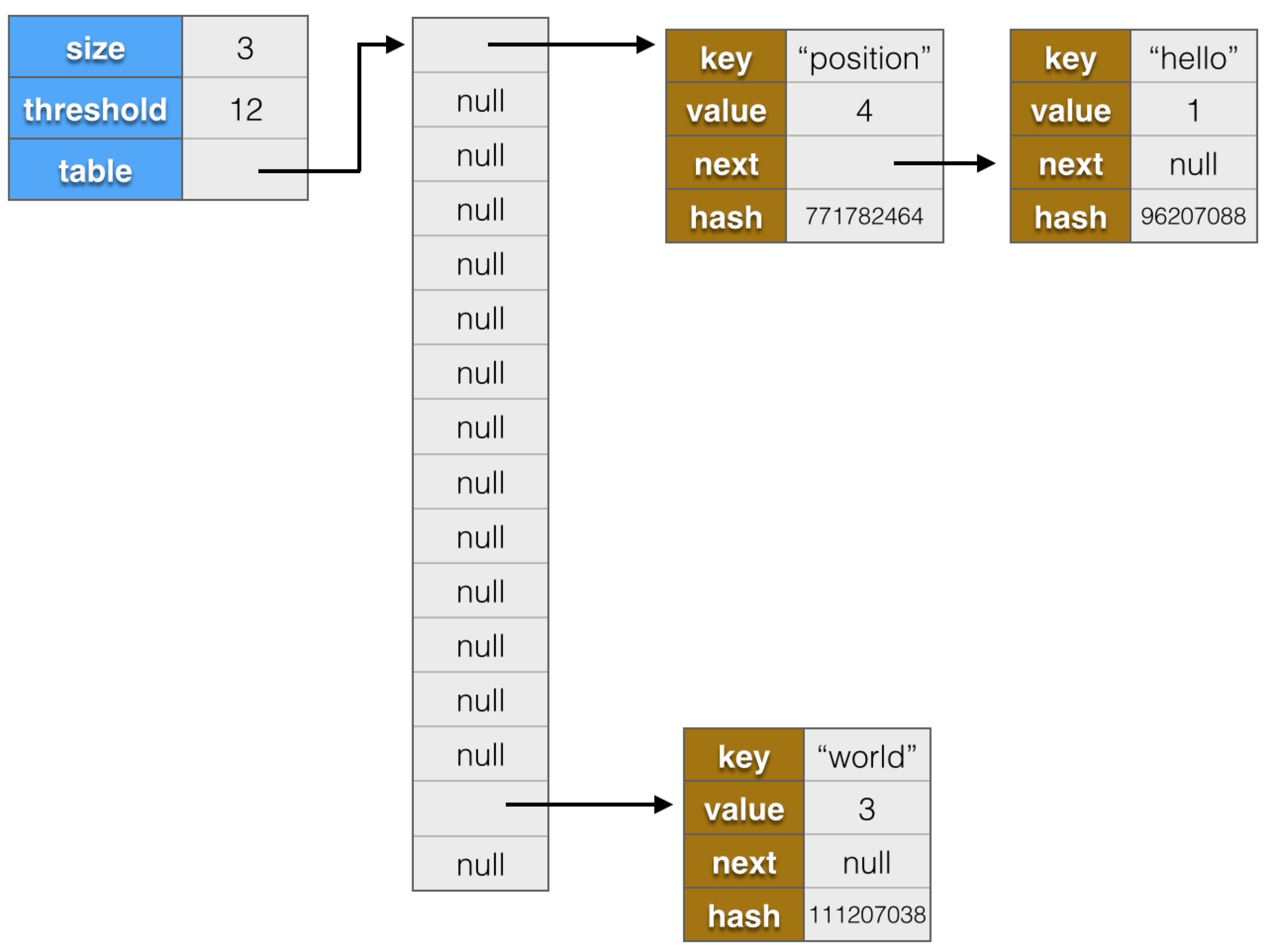
理解了鍵值對在內存是如何存放的,就比較容易理解其他方法了,我們來看get方法。
根據鍵獲取值
代碼為:
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
HashMap支持key為null,key為null的時候,放在table[0],調用getForNullKey()獲取值,如果key不為null,則調用getEntry()獲取鍵值對節點entry,然後調用節點的getValue()方法獲取值。getEntry方法的代碼是:
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
邏輯也比較簡單:
1. 計算鍵的hash值,代碼為:
int hash = (key == null) ? 0 : hash(key);
2. 根據hash找到table中的對應鏈表,代碼為:
table[indexFor(hash, table.length)];
3. 在鏈表中遍歷查找,遍歷代碼:
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next)
4. 逐個比較,先通過hash快速比較,hash相同再通過equals比較,代碼為:
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
查看是否包含某個鍵
containsKey的邏輯與get是類似的,節點不為null就表示存在,具體代碼為:
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
查看是否包含某個值
HashMap可以方便高效的按照鍵進行操作,但如果要根據值進行操作,則需要遍歷,containsValue方法的代碼為:
public boolean containsValue(Object value) {
if (value == null)
return containsNullValue();
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
如果要查找的值為null,則調用containsNullValue單獨處理,我們看不為null的情況,遍歷的邏輯也很簡單,就是從table的第一個鏈表開始,從上到下,從左到右逐個節點進行訪問,通過equals方法比較值,直到找到為止。
根據鍵刪除鍵值對
代碼為:
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
removeEntryForKey的代碼為:
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
基本邏輯為:
1. 計算hash,根據hash找到對應的table索引,代碼為:
int hash = (key == null) ? 0 : hash(key); int i = indexFor(hash, table.length);
2. 遍歷table[i],查找待刪節點,使用變量prev指向前一個節點,next指向下一個節點,e指向當前節點,遍歷結構代碼為:
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
if(找到了){
//刪除
return;
}
prev = e;
e = next;
}
3. 判斷是否找到,依然是先比較hash,hash相同時再用equals方法比較
4. 刪除的邏輯就是讓長度減小,然後讓待刪節點的前後節點連起來,如果待刪節點是第一個節點,則讓table[i]直接指向後一個節點,代碼為:
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);在HashMap中代碼為空,主要是為了HashMap的子類擴展使用。
實現原理小結
以上就是HashMap的基本實現原理,內部有一個數組table,每個元素table[i]指向一個單向鏈表,根據鍵存取值,用鍵算出hash,取模得到數組中的索引位置buketIndex,然後操作table[buketIndex]指向的單向鏈表。
存取的時候依據鍵的hash值,只在對應的鏈表中操作,不會訪問別的鏈表,在對應鏈表操作時也是先比較hash值,相同的話才用equals方法比較,這就要求,相同的對象其hashCode()返回值必須相同,如果鍵是自定義的類,就特別需要注意這一點。這也是hashCode和equals方法的一個關鍵約束,這個約束我們在介紹包裝類的時候也提到過。
HashMap特點分析
HashMap實現了Map接口,內部使用數組鏈表和哈希的方式進行實現,這決定了它有如下特點:
如果經常需要根據鍵存取值,而且不要求順序,那HashMap就是理想的選擇。
小結
本節介紹了HashMap的用法和實現原理,它實現了Map接口,可以方便的按照鍵存取值,它的實現利用了哈希,可以根據鍵自身直接定位,存取效率很高。
根據哈希值存取對象、比較對象是計算機程序中一種重要的思維方式,它使得存取對象主要依賴於自身哈希值,而不是與其他對象進行比較,存取效率也就與集合大小無關,高達O(1),即使進行比較,也利用哈希值提高比較性能。
不過HashMap沒有順序,如果要保持添加的順序,可以使用HashMap的一個子類LinkedHashMap,後續我們再介紹。Map還有一個重要的實現類TreeMap,它可以排序,我們也留待後續章節介紹。
本節提到了Set接口,下節,讓我們探討它的一種重要實現類HashSet。
----------------
未完待續,查看最新文章,敬請關注微信公眾號“老馬說編程”(掃描下方二維碼),從入門到高級,深入淺出,老馬和你一起探索Java編程及計算機技術的本質。用心原創,保留所有版權。