一:垃圾回收機制的原因
java中,當沒有對象引用指向原先分配給某個對象的內存時候,該內存就成為了垃圾。JVM的一個系統級線程會自動釋放該內存塊。垃圾回收意味著程序不再需要的對象是"無用信息",這些信息將被丟棄。當一個對象不再被引用的時候,內存回收它占領的空間,以便空間被後來的新對象使用。事實上,除了釋放沒用的對象,垃圾回收也可以清除內存記錄碎片。由於創建對象和垃圾回收器釋放丟棄對象所占的內存空間,內存會出現碎片。碎片是分配給對象的內存塊之間的空閒內存洞。碎片整理將所占用的堆內存移到堆的一端,JVM將整理出的內存分配給新的對象。
垃圾回收的優點:垃圾回收能自動釋放內存空間,減輕編程的負擔。首先,它能使編程效率提高。在沒有垃圾回收機制的時候,可能要花許多時間來解決一個難懂的存儲器問題。在用Java語言編程的時候,靠垃圾回收機制可大大縮短時間。其次是它保護程序的完整性, 垃圾回收是Java語言安全性策略的一個重要部份。
垃圾回收的缺點:垃圾回收的開銷影響程序性能。Java虛擬機必須追蹤運行程序中有用的對象,而且最終釋放沒用的對象。這一個過程需要花費處理器的時間。其次垃圾回收算法的不完備性,早先采用的某些垃圾回收算法就不能保證100%收集到所有的廢棄內存。當然隨著垃圾回收算法的不斷改進以及軟硬件運行效率的不斷提升,這些問題都可以迎刃而解。
二:垃圾收集的算法分析
引用計數法是唯一沒有使用根集的垃圾回收的方法,該算法使用引用計數器來區分存活對象和不再使用的對象。
引用計數器算法是給每個對象設置一個計數器,當有地方引用這個對象的時候,計數器+1,當引用失效的時候,計數器-1,當計數器為0的時候,JVM就認為對象不再被使用,是“垃圾”了。
引用計數器實現簡單,效率高;但是不能解決循環引用問問題(A對象引用B對象,B對象又引用A對象,但是A,B對象已不被任何其他對象引用),同時每次計數器的增加和減少都帶來了很多額外的開銷,所以在JDK1.1之後,這個算法已經不再使用了。
2.根搜索方法:
大多數垃圾回收算法使用了根集(root set)這個概念;所謂根集就是正在執行的Java程序可以訪問的引用變量的集合(包括局部變量、參數、類變量),程序可以使用引用變量訪問對象的屬性和調用對象的方法。垃圾回收首先需要確定從根開始哪些是可達的和哪些是不可達的,從根集可達的對象都是活動對象,它們不能作為垃圾被回收,這也包括從根集間接可達的對象。而根集通過任意路徑不可達的對象符合垃圾收集的條件,應該被回收。下面介紹幾個常用的算法。
2.1 標記—清除算法(Mark-Sweep)
原理:標記—清除算法包括兩個階段:“標記”和“清除”。在標記階段,確定所有要回收的對象,並做標記。清除階段緊隨標記階段,將標記階段確定不可用的對象清除。
缺點:標記—清除算法是基礎的收集算法,標記和清除階段的效率不高,而且清除後回產生大量的不連續空間,這樣當程序需要分配大內存對象時,可能無法找到足夠的連續空間。
垃圾回收前:

垃圾回收後:
綠色:存活對象 紅色:可回收對象 白色:未使用空間
2.2復制算法(Copying)
原理:復制算法是把內存分成大小相等的兩塊,每次使用其中一塊,當垃圾回收的時候,把存活的對象復制到另一塊上,然後把這塊內存整個清理掉。
缺點:復制算法實現簡單,運行效率高,但是由於每次只能使用其中的一半,造成內存的利用率不高。現在的JVM用復制方法收集新生代,由於新生代中大部分對象(98%)都是朝生夕死的,所以兩塊內存的比例不是1:1(大概是8:1)。
垃圾回收前:
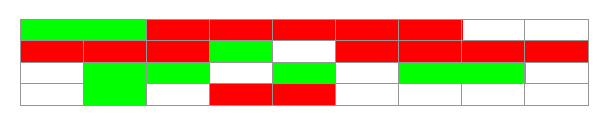
垃圾回收後:

綠色:存活對象 紅色:可回收對象 白色:未使用空間
原理:標記—整理算法和標記—清除算法一樣,但是標記—整理算法不是把存活對象復制到另一塊內存,而是把存活對象往內存的一端移動,然後直接回收邊界以外的內存。
標記—整理算法提高了內存的利用率,並且它適合在收集對象存活時間較長的老年代。
垃圾回收前:
垃圾回收後:
綠色:存活對象 紅色:可回收對象 白色:未使用空間
上面這四種是最基本的垃圾回收算法,在這四種算法思想之上發展出來其余算法,個人認為更多的是一種內存管理策略,甚至可以看成就是基本算法的組合應用,就像加減乘除與方程式的關系一樣,因此將其分開描述。
這類算法一般由基本算法組成,其核心思想是將內存分區域進行管理,在不同的區域和不同的時間采用不同的內存管理策略,從而避免因全系統的垃圾回收導致程序長時間暫停。這類算法一般有以下幾種:
3.1.火車算法
這種算法把成熟的內存空間劃為固定長度的內存塊,算法每次在一個塊中單獨執行,每一個塊屬於一個集合。此算法的具體執行步驟較復雜,且沒有具體的應用場景,在此不浪費筆墨,有興趣的同學可以自己研究之。
3.2.分代收集算法
這種算法在sun/oracle公司的Hotspot虛擬機中得到應用,是java程序員需要重點關注的一種算法。
這種算法是通過對對象的生命周期進行分析後得出的,它將堆內存分成了三個部分:年青代,年老代,持久代(相當於方法區)。處於不同生命周期的對象被存儲於不同的區域,並使用不同的算法進行回收。這種算法的具體執行細節將會在後續的學習筆記中詳細介紹。
關於分代收集 詳見 http://www.importnew.com/19255.html
4.多線程實現的堆垃圾回收技術
4.1.串行收集
串行收集使用單線程處理所有垃圾回收工作,因為無需多線程交互,實現容易,而且效率比較高。但是,其局限性也比較明顯,即無法使用多處理器的優勢,所以此收集適合單處理器機器。當然,此收集器也可以用在小數據量(100M左右)情況下的多處理器機器上。
適用情況:數據量比較小(100M左右);單處理器下並且對響應時間無要求的應用。
缺點:只能用於小型應用。
4.2.並行收集
並行收集使用多線程處理垃圾回收工作,因而速度快,效率高。而且理論上CPU數目越多,越能體現出並行收集器的優勢。
適用情況:“對吞吐量有高要求”,多CPU、對應用響應時間無要求的中、大型應用。舉例:後台處理、科學計算。
缺點:應用響應時間可能較長 。
4.3.並發收集
相對於串行收集和並行收集而言,前面兩個在進行垃圾回收工作時,需要暫停整個運行環境,而只有垃圾回收程序在運行,因此,系統在垃圾回收時會有明顯的暫停,而且暫停時間會因為堆越大而越長。
適用情況:“對響應時間有高要求”,多CPU、對應用響應時間有較高要求的中、大型應用。舉例:Web服務器/應用服務器、電信交換、集成開發環境。
參考:
http://blog.csdn.net/zsuguangh/article/details/6429592
http://blog.csdn.net/ol_beta/article/details/6791229
https://my.oschina.net/GameKing/blog/198347