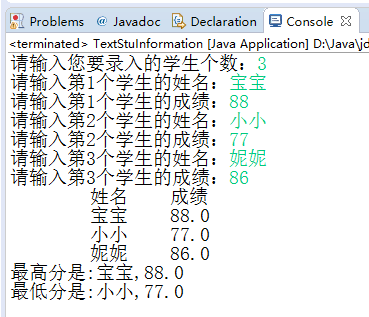
(更多內容請關注本人微信訂閱號:it_pupil)
拿到字符串,以特定形式編碼成字節數組(如UTF-8)。(字節數組是你人工轉換的)
告訴浏覽器,以相同方式解碼顯示(UTF-8)。
如果你使用的是字符流,那麼需要注意三點:
字符流其實就是你傳給它的是字符,它自己內部還是會轉換成字節的。
拿到字符串,告訴服務端,發送時以特定方式編碼成字節數組(如UTF-8)。(字節數組是字符流內部轉換的)
告訴浏覽器,以相同方式解碼顯示(UTF-8)。
就上面提出的幾點,有三種實現方案保證不亂碼(也是亂碼的解決思路):
方案一,字節流:
方案二,字符流:
方案三,還是字符流:
方案三其實可以像下面模擬一下編解碼的過程(toHex方法是把字節數組以16進制形式輸出):
所以,方案三的關鍵之處在於,一開始用UTF-8編碼,最後用UTF-8解碼,這是本質。
雖然ISO-8859-1是單字節編碼,但是,一開始用UTF-8編碼後,你用ISO-8859-1解碼,它會一個字節一個字節去解開,而UTF-8表示的漢字,一個漢字是三個字節,當然會亂碼。
但是亂碼不要緊啊,這個亂碼只是個中間過程,不需要顯示出來。緊接著用ISO-8859-1再編碼,那麼,編碼出的字節是跟UTF-8編碼的字節是相同的。
如此,最後再用UTF-8去解碼,完美!
本文是關於編碼分析的第5篇,原文地址:
http://mp.weixin.qq.com/s?__biz=MzIyNzUzNjQ3MA==&tempkey=37C%2F%2BA4Bi9W%2F7a0wo%2B56WiBFhphFwjbCfb6TgA3OcQ4v4JbKjTBmxOQLMoZldKoCJeAi%2BhxmRuBUwSzp7yjZCA2k5X%2BXxzpE3hD%2BaLWechfiCfr797hJOnJt29Rqr9eM5KF3ZKZOmQ%2FeJGYzG8vXRQ%3D%3D&#rd
更多內容請關注相關訂閱號查看。