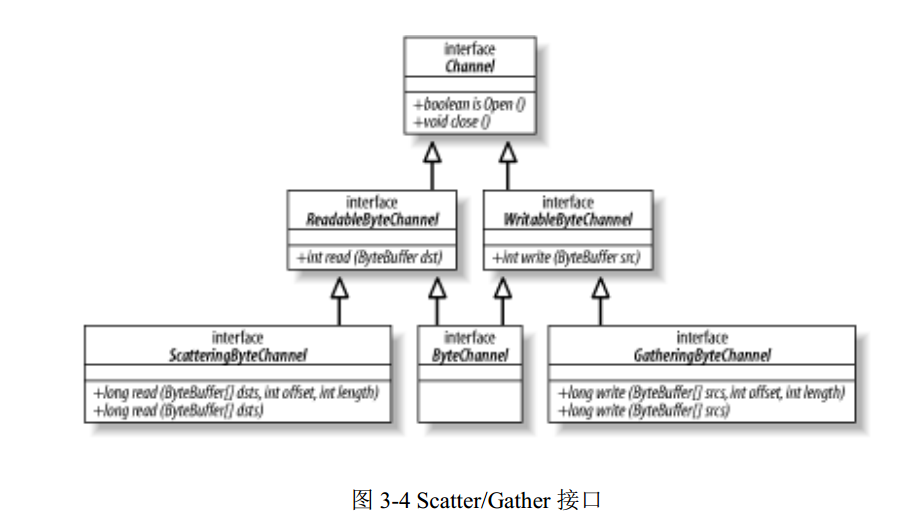
工廠方法模式(Factory Method Pattern)是" 創建對象的接口,讓子類決定實例化哪一個類,並使一個類的實例化延遲到其它子類"。工廠方法模式在我們的開發中經常會用到。下面以汽車制造為例,看看一般的工廠方法模式是如何實現的,代碼如下:
1 //抽象產品
2 interface Car{
3
4 }
5 //具體產品類
6 class FordCar implements Car{
7
8 }
9 //具體產品類
10 class BuickCar implements Car{
11
12 }
13 //工廠類
14 class CarFactory{
15 //生產汽車
16 public static Car createCar(Class<? extends Car> c){
17 try {
18 return c.newInstance();
19 } catch (InstantiationException | IllegalAccessException e) {
20 e.printStackTrace();
21 }
22 return null;
23 }
24 }
這是最原始的工廠方法模式,有兩個產品:福特汽車和別克汽車,然後通過工廠方法模式來生產。有了工廠方法模式,我們就不用關心一輛車具體是怎麼生成的了,只要告訴工廠" 給我生產一輛福特汽車 "就可以了,下面是產出一輛福特汽車時客戶端的代碼:
public static void main(String[] args) {
//生產車輛
Car car = CarFactory.createCar(FordCar.class);
}
這就是我們經常使用的工廠方法模式,但經常使用並不代表就是最優秀、最簡潔的。此處再介紹一種通過枚舉實現工廠方法模式的方案,誰優誰劣你自行評價。枚舉實現工廠方法模式有兩種方法:
(1)、枚舉非靜態方法實現工廠方法模式
我們知道每個枚舉項都是該枚舉的實例對象,那是不是定義一個方法可以生成每個枚舉項對應產品來實現此模式呢?代碼如下:
1 enum CarFactory {
2 // 定義生產類能生產汽車的類型
3 FordCar, BuickCar;
4 // 生產汽車
5 public Car create() {
6 switch (this) {
7 case FordCar:
8 return new FordCar();
9 case BuickCar:
10 return new BuickCar();
11 default:
12 throw new AssertionError("無效參數");
13 }
14 }
15
16 }
create是一個非靜態方法,也就是只有通過FordCar、BuickCar枚舉項才能訪問。采用這種方式實現工廠方法模式時,客戶端要生產一輛汽車就很簡單了,代碼如下:
public static void main(String[] args) {
// 生產車輛
Car car = CarFactory.BuickCar.create();
}
(2)、通過抽象方法生成產品
枚舉類型雖然不能繼承,但是可以用abstract修飾其方法,此時就表示該枚舉是一個抽象枚舉,需要每個枚舉項自行實現該方法,也就是說枚舉項的類型是該枚舉的一個子類,我們倆看代碼:
1 enum CarFactory {
2 // 定義生產類能生產汽車的類型
3 FordCar{
4 public Car create(){
5 return new FordCar();
6 }
7 },
8 BuickCar{
9 public Car create(){
10 return new BuickCar();
11 }
12 };
13 //抽象生產方法
14 public abstract Car create();
15 }
首先定義一個抽象制造方法create,然後每個枚舉項自行實現,這種方式編譯後會產生CarFactory的匿名子類,因為每個枚舉項都要實現create抽象方法。客戶端調用與上一個方案相同,不再贅述。
大家可能會問,為什麼要使用枚舉類型的工廠方法模式呢?那是因為使用枚舉類型的工廠方法模式有以下三個優點:
public static void main(String[] args) {
// 生產車輛
Car car = CarFactory.createCar(Car.class);
}
Car是一個接口,完全合乎createCar的要求,所以它在編譯時不會報任何錯誤,但一運行就會報出InstantiationException異常,而使用枚舉類型的工廠方法模式就不存在該問題了,不需要傳遞任何參數,只需要選擇好生產什麼類型的產品即可。
而枚舉類型的工廠方法就沒有這種問題了,它只需要依賴工廠類就可以生產一輛符合接口的汽車,完全可以無視具體汽車類的存在。
為了更好地使用枚舉,Java提供了兩個枚舉集合:EnumSet和EnumMap,這兩個集合使用的方法都比較簡單,EnumSet表示其元素必須是某一枚舉的枚舉項,EnumMap表示Key值必須是某一枚舉的枚舉項,由於枚舉類型的實例數量固定並且有限,相對來說EnumSet和EnumMap的效率會比其它Set和Map要高。
雖然EnumSet很好用,但是它有一個隱藏的特點,我們逐步分析。在項目中一般會把枚舉用作常量定義,可能會定義非常多的枚舉項,然後通過EnumSet訪問、遍歷,但它對不同的枚舉數量有不同的處理方式。為了進行對比,我們定義兩個枚舉,一個數量等於64,一個是65(大於64即可,為什麼是64而不是128,512呢,一會解釋),代碼如下:
1 //普通枚舉項,數量等於64
2 enum Const{
3 A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,
4 AA,BB,CC,DD,EE,FF,GG,HH,II,JJ,KK,LL,MM,NN,OO,PP,QQ,RR,SS,TT,UU,VV,WW,XX,YY,ZZ,
5 AAA,BBB,CCC,DDD,EEE,FFF,GGG,HHH,III,JJJ,KKK,LLL
6 }
7 //大枚舉,數量超過64
8 enum LargeConst{
9 A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,
10 AA,BB,CC,DD,EE,FF,GG,HH,II,JJ,KK,LL,MM,NN,OO,PP,QQ,RR,SS,TT,UU,VV,WW,XX,YY,ZZ,
11 AAAA,BBBB,CCCC,DDDD,EEEE,FFFF,GGGG,HHHH,IIII,JJJJ,KKKK,LLLL,MMMM
12 }
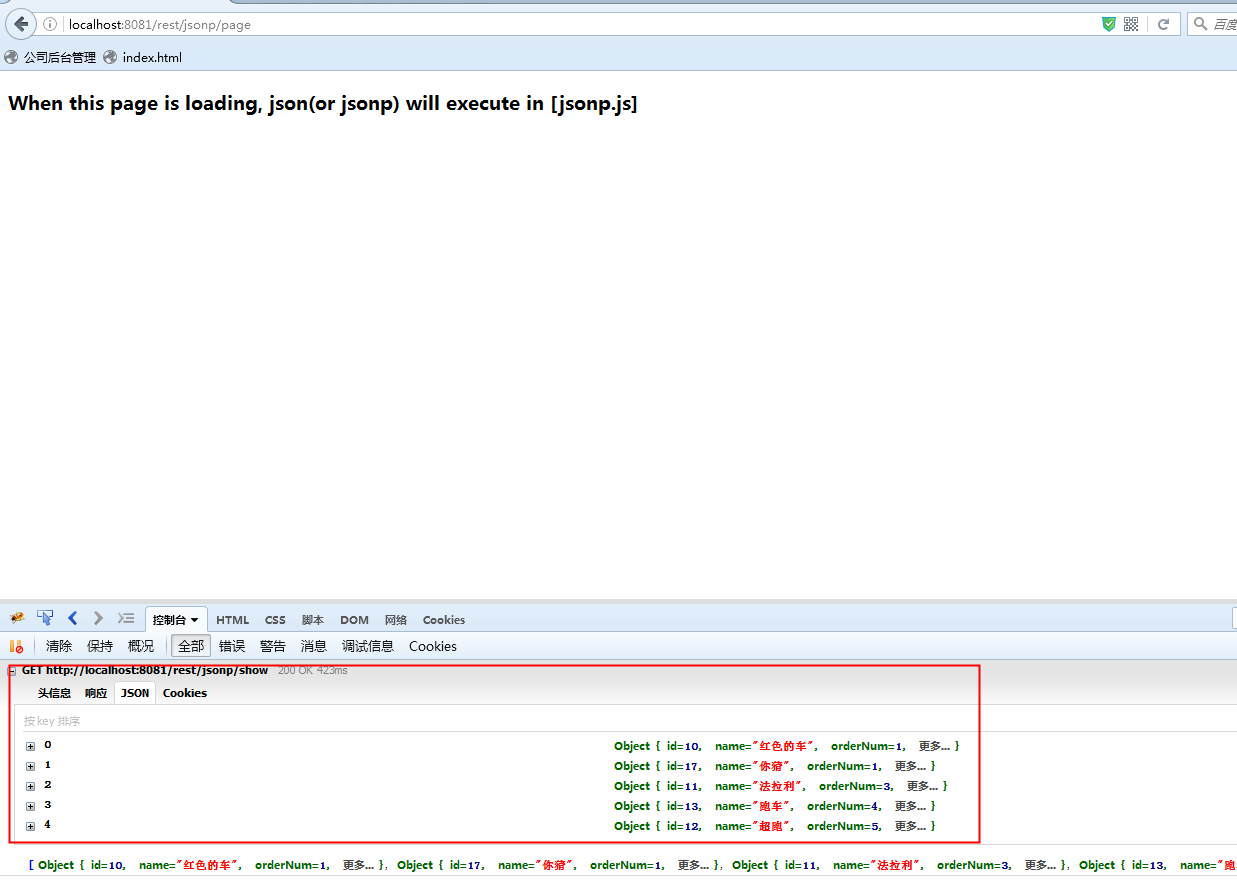
Const的枚舉項數量是64,LagrgeConst的枚舉項數量是65,接下來我們希望把這兩個枚舉轉換為EnumSet,然後判斷一下它們的class類型是否相同,代碼如下:
1 public class Client89 {
2 public static void main(String[] args) {
3 EnumSet<Const> cs = EnumSet.allOf(Const.class);
4 EnumSet<LargeConst> lcs = EnumSet.allOf(LargeConst.class);
5 //打印出枚舉數量
6 System.out.println("Const的枚舉數量:"+cs.size());
7 System.out.println("LargeConst的枚舉數量:"+lcs.size());
8 //輸出兩個EnumSet的class
9 System.out.println(cs.getClass());
10 System.out.println(lcs.getClass());
11 }
12 }
程序很簡單,現在的問題是:cs和lcs的class類型是否相同?應該相同吧,都是EnumSet類的工廠方法allOf生成的EnumSet類,而且JDK API也沒有提示EnumSet有子類。我們來看看輸出結果:
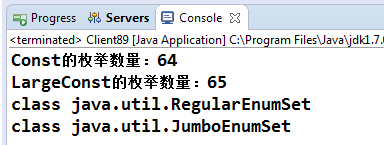
很遺憾,兩者不相等。就差一個元素,兩者就不相等了?確實如此,這也是我們重點關注枚舉項數量的原因。先來看看Java是如何處理的,首先跟蹤allOf方法,其源碼如下:
1 public static <E extends Enum<E>> EnumSet<E> allOf(Class<E> elementType) {
2 //生成一個空EnumSet
3 EnumSet<E> result = noneOf(elementType);
4 //加入所有的枚舉項
5 result.addAll();
6 return result;
7 }
allOf通過noneOf方法首先生成了一個EnumSet對象,然後把所有的枚舉都加進去,問題可能就出在EnumSet的生成上了,我們來看看noneOf的源碼:
1 public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
2 //獲得所有的枚舉項
3 Enum[] universe = getUniverse(elementType);
4 if (universe == null)
5 throw new ClassCastException(elementType + " not an enum");
6 //枚舉數量小於等於64
7 if (universe.length <= 64)
8 return new RegularEnumSet<>(elementType, universe);
9 else
10 //枚舉數量大於64
11 return new JumboEnumSet<>(elementType, universe);
12 }
看到這裡,恍然大悟,Java原來是如此處理的:當枚舉項數量小於等於64時,創建一個RegularEnumSet實例對象,大於64時則創建一個JumboEnumSet實例對象。
為什麼要如此處理呢?這還要看看這兩個類之間的差異,首先看RegularEnumSet類,源碼如下:
1 class RegularEnumSet<E extends Enum<E>> extends EnumSet<E> {
2 private static final long serialVersionUID = 3411599620347842686L;
3 /**
4 * Bit vector representation of this set. The 2^k bit indicates the
5 * presence of universe[k] in this set.
6 */
7 //記錄所有的枚舉號,注意是long型
8 private long elements = 0L;
9 //構造函數
10 RegularEnumSet(Class<E>elementType, Enum[] universe) {
11 super(elementType, universe);
12 }
13
14 //加入所有元素
15 void addAll() {
16 if (universe.length != 0)
17 elements = -1L >>> -universe.length;
18 }
19
20 //其它代碼略
21 }
我們知道枚舉項的排序值ordinal 是從0、1、2......依次遞增的,沒有重號,沒有跳號,RegularEnumSet就是利用這一點把每個枚舉項的ordinal映射到一個long類型的每個位置上的,注意看addAll方法的elements元素,它使用了無符號右移操作,並且操作數是負值,位移也是負值,這表示是負數(符號位是1)的"無符號左移":符號位為0,並補充低位,簡單的說,Java把一個不多於64個枚舉項映射到了一個long類型變量上。這才是EnumSet處理的重點,其他的size方法、contains方法等都是根據elements方法等都是根據elements計算出來的。想想看,一個long類型的數字包含了所有的枚舉項,其效率和性能能肯定是非常優秀的。
我們知道long類型是64位的,所以RegularEnumSet類型也就只能負責枚舉項的數量不大於64的枚舉(這也是我們以64來舉例,而不以128,512舉例的原因),大於64則由JumboEnumSet處理,我們看它是怎麼處理的:
1 class JumboEnumSet<E extends Enum<E>> extends EnumSet<E> {
2 private static final long serialVersionUID = 334349849919042784L;
3
4 /**
5 * Bit vector representation of this set. The ith bit of the jth
6 * element of this array represents the presence of universe[64*j +i]
7 * in this set.
8 */
9 //映射所有的枚舉項
10 private long elements[];
11
12 // Redundant - maintained for performance
13 private int size = 0;
14
15 JumboEnumSet(Class<E>elementType, Enum[] universe) {
16 super(elementType, universe);
17 //默認長度是枚舉項數量除以64再加1
18 elements = new long[(universe.length + 63) >>> 6];
19 }
20
21 void addAll() {
22 //elements中每個元素表示64個枚舉項
23 for (int i = 0; i < elements.length; i++)
24 elements[i] = -1;
25 elements[elements.length - 1] >>>= -universe.length;
26 size = universe.length;
27 }
28 }
JumboEnumSet類把枚舉項按照64個元素一組拆分成了多組,每組都映射到一個long類型的數字上,然後該數組再放置到elements數組中,簡單來說JumboEnumSet類的原理與RegularEnumSet相似,只是JumboEnumSet使用了long數組容納更多的枚舉項。不過,這樣的程序看著會不會覺得郁悶呢?其實這是因為我們在開發中很少使用位移操作。大家可以這樣理解:RegularEnumSet是把每個枚舉項映射到一個long類型數字的每個位上,JumboEnumSet是先按照64個一組進行拆分,然後每個組再映射到一個long類型數字的每個位上。
從以上的分析可知,EnumSet提供的兩個實現都是基本的數字類型操作,其性能肯定比其他的Set類型要好的多,特別是Enum的數量少於64的時候,那簡直就是飛一般的速度。
注意:枚舉項數量不要超過64,否則建議拆分。
Java從1.5版本開始引入注解(Annotation),其目的是在不影響代碼語義的情況下增強代碼的可讀性,並且不改變代碼的執行邏輯,對於注解始終有兩派爭論,正方認為注解有益於數據與代碼的耦合,"在有代碼的周邊集合數據";反方認為注解把代碼和數據混淆在一起,增加了代碼的易變性,消弱了程序的健壯性和穩定性。這些爭論暫且擱置,我們要說的是一個我們不常用的元注解(Meta-Annotation):@Inheruted,它表示一個注解是否可以自動繼承,我們開看它如何使用。
思考一個例子,比如描述鳥類,它有顏色、體型、習性等屬性,我們以顏色為例,定義一個注解來修飾一下,代碼如下:
1 import java.lang.annotation.ElementType;
2 import java.lang.annotation.Inherited;
3 import java.lang.annotation.Retention;
4 import java.lang.annotation.RetentionPolicy;
5 import java.lang.annotation.Target;
6
7 @Retention(RetentionPolicy.RUNTIME)
8 @Target(ElementType.TYPE)
9 @Inherited
10 public @interface Desc {
11 enum Color {
12 White, Grayish, Yellow
13 }
14
15 // 默認顏色是白色的
16 Color c() default Color.White;
17 }
該注解Desc前增加了三個注解:Retention表示的是該注解的保留級別,Target表示的是注解可以標注在什麼地方,@Inherited表示該注解會被自動繼承。注解定義完畢,我們把它標注在類上,代碼如下:
1 @Desc(c = Color.White)
2 abstract class Bird {
3 public abstract Color getColor();
4 }
5
6 // 麻雀
7 class Sparrow extends Bird {
8 private Color color;
9
10 // 默認是淺灰色
11 public Sparrow() {
12 color = Color.Grayish;
13 }
14
15 // 構造函數定義鳥的顏色
16 public Sparrow(Color _color) {
17 color = _color;
18 }
19
20 @Override
21 public Color getColor() {
22 return color;
23 }
24 }
25
26 // 鳥巢,工廠方法模式
27 enum BirdNest {
28 Sparrow;
29 // 鳥類繁殖
30 public Bird reproduce() {
31 Desc bd = Sparrow.class.getAnnotation(Desc.class);
32 return bd == null ? new Sparrow() : new Sparrow(bd.c());
33 }
34 }
上面程序聲明了一個Bird抽象類,並且標注了Desc注解,描述鳥類的顏色是白色,然後編寫一個麻雀Sparrow類,它有兩個構造函數,一個是默認的構造函數,也就是我們經常看到的麻雀是淺灰色的,另外一個構造函數是自定義麻雀的顏色,之後又定義了一個鳥巢(工廠方法模式),它是專門負責鳥類繁殖的,它的生產方法reproduce會根據實現類注解信息生成不同顏色的麻雀。我們編寫一個客戶端調用,代碼如下:
1 public static void main(String[] args) {
2 Bird bird = BirdNest.Sparrow.reproduce();
3 Color color = bird.getColor();
4 System.out.println("Bird's color is :" + color);
5 }
現在問題是這段客戶端程序會打印出什麼來?因為采用了工廠方法模式,它最主要的問題就是bird變量到底采用了那個構造函數來生成,是無參構造函數還是有參構造?如果我們單獨看子類Sparrow,它沒有被添加任何注釋,那工廠方法中的bd變量就應該是null了,應該調用的是無參構造。是不是如此呢?我們來看運行結果:“Bird‘s Color is White ”;
白色?這是我們添加到父類Bird上的顏色,為什麼?這是因為我們在注解上加了@Inherited注解,它表示的意思是我們只要把注解@Desc加到父類Bird上,它的所有子類都會從父類繼承@Desc注解,不需要顯示聲明,這與Java的繼承有點不同,若Sparrow類繼承了Bird卻不用顯示聲明,只要@Desc注解釋可自動繼承的即可。
采用@Inherited元注解有利有弊,利的地方是一個注解只要標注到父類,所有的子類都會自動具有父類相同的注解,整齊,統一而且便於管理,弊的地方是單單閱讀子類代碼,我們無從知道為何邏輯會被改變,因為子類沒有顯示標注該注解。總體上來說,使用@Inherited元注解弊大於利,特別是一個類的繼承層次較深時,如果注解較多,則很難判斷出那個注解對子類產生了邏輯劫持。
我們知道注解的寫法和接口很類似,都采用了關鍵字interface,而且都不能有實現代碼,常量定義默認都是public static final 類型的等,它們的主要不同點是:注解要在interface前加上@字符,而且不能繼承,不能實現,這經常會給我們的開發帶來些障礙。
我們來分析一下ACL(Access Control List,訪問控制列表)設計案例,看看如何避免這些障礙,ACL有三個重要元素:
鑒權人是整個ACL的設計核心,我們從最主要的鑒權人開始,代碼如下:
interface Identifier{
//無權訪問時的禮貌語
String REFUSE_WORD = "您無權訪問";
//鑒權
public boolean identify();
}
這是一個鑒權人接口,定義了一個常量和一個鑒權方法。接下來應該實現該鑒權方法,但問題是我們的權限級別和鑒權方法之間是緊耦合,若分拆成兩個類顯得有點啰嗦,怎麼辦?我們可以直接頂一個枚舉來實現,代碼如下:
1 enum CommonIdentifier implements Identifier {
2 // 權限級別
3 Reader, Author, Admin;
4
5 @Override
6 public boolean identify() {
7 return false;
8 }
9
10 }
定義了一個通用鑒權者,使用的是枚舉類型,並且實現了鑒權者接口。現在就剩下資源定義了,這很容易定義,資源就是我們寫的類、方法等,之後再通過配置來決定哪些類、方法允許什麼級別的訪問,這裡的問題是:怎麼把資源和權限級別關聯起來呢?使用XML配置文件?是個方法,但對我們的示例程序來說顯得太繁重了,如果使用注解會更簡潔些,不過這需要我們首先定義出權限級別的注解,代碼如下:
1 @Retention(RetentionPolicy.RUNTIME)
2 @Target(ElementType.TYPE)
3 @interface Access{
4 //什麼級別可以訪問,默認是管理員
5 CommonIdentifier level () default CommonIdentifier.Admin;
6 }
該注解釋標注在類上面的,並且會保留到運行期。我們定義一個資源類,代碼如下:
@Access(level=CommonIdentifier.Author)
class Foo{
}
Foo類只能是作者級別的人訪問。場景都定義完畢了,那我們看看如何模擬ACL實現,代碼如下:
1 public static void main(String[] args) {
2 // 初始化商業邏輯
3 Foo b = new Foo();
4 // 獲取注解
5 Access access = b.getClass().getAnnotation(Access.class);
6 // 沒有Access注解或者鑒權失敗
7 if (null == access || !access.level().identify()) {
8 // 沒有Access注解或者鑒權失敗
9 System.out.println(access.level().REFUSE_WORD);
10 }
11 }
看看這段代碼,簡單,易讀,而且如果我們是通過ClassLoader類來解釋該注解的,那會使我們的開發更簡潔,所有的開發人員只要增加注解即可解決訪問控制問題。注意看加粗代碼,access是一個注解類型,我們想使用Identifier接口的identity鑒權方法和REFUSE_WORD常量,但注解釋不能集成的,那怎麼辦?此處,可通過枚舉類型CommonIdentifier從中間做一個委派動作(Delegate),委派?你可以然identity返回一個對象,或者在Identifier上直接定義一個常量對象,那就是“赤裸裸” 的委派了。
@Override注解用於方法的覆寫上,它是在編譯器有效,也就是Java編譯器在編譯時會根據注解檢查方法是否真的是覆寫,如果不是就報錯,拒絕編譯。該注解可以很大程度地解決我們的誤寫問題,比如子類和父類的方法名少寫一個字符,或者是數字0和字母O為區分出來等,這基本是每個程序員都曾將犯過的錯誤。在代碼中加上@Override注解基本上可以杜絕出現此類問題,但是@Override有個版本問題,我們來看如下代碼:
1 interface Foo {
2 public void doSomething();
3 }
4
5 class FooImpl implements Foo{
6 @Override
7 public void doSomething() {
8
9 }
10 }
這是一個簡單的@Override示例,接口中定義了一個doSomething方法,實現類FooImpl實現此方法,並且在方法前加上了@Override注解。這段代碼在Java1.6版本上編譯沒問題,雖然doSomething方法只是實現了接口的定義,嚴格來說並不是覆寫,但@Override出現在這裡可減少代碼中出現的錯誤。
可如果在Java1.5版本上編譯此段代碼可能會出現錯誤:
The method doSomeThing() of type FooImpl must override a superclass method
注意,這是個錯誤,不能繼續編譯,原因是Java1.5版本的@Override是嚴格遵守覆寫的定義:子類方法與父類方法必須具有相同的方法名、輸出參數、輸出參數(允許子類縮小)、訪問權限(允許子類擴大),父類必須是一個類,不能是接口,否則不能算是覆寫。而這在Java1.6就開放了很多,實現接口的方法也可以加上@Override注解了,可以避免粗心大意導致方法名稱與接口不一致的情況發生。
在多環境部署應用時,需呀考慮@Override在不同版本下代表的意義,如果是Java1.6版本的程序移植到1.5版本環境中,就需要刪除實現接口方法上的@Override注解。