List接口提供了subList方法,其作用是返回一個列表的子列表,這與String類subSting有點類似,但它們的功能是否相同呢?我們來看如下代碼:
1 public class Client70 {
2 public static void main(String[] args) {
3 // 定義一個包含兩個字符串的列表
4 List<String> c = new ArrayList<String>();
5 c.add("A");
6 c.add("B");
7 // 構造一個包含c列表的字符串列表
8 List<String> c1 = new ArrayList<String>(c);
9 // subList生成與c相同的列表
10 List<String> c2 = c.subList(0, c.size());
11 // c2增加一個元素
12 c2.add("C");
13 System.out.println("c==c1? " + c.equals(c1));
14 System.out.println("c==c2? " + c.equals(c2));
15 }
16 }
c1是通過ArrayList的構造函數創建的,c2是通過列表的subList方法創建的,然後c2又增加了一個元素"C",現在的問題是輸出的結果是什麼呢?列表c與c1、c2之間是什麼關系呢?先不回答這個問題,我們先來回想一下String類的subString方法,看看它是如何工作的,代碼如下:
1 public static void testStr() {
2 String str = "AB";
3 String str1 = new String(str);
4 String str2 = str.substring(0) + "C";
5 System.out.println("str==str1? " + str.equals(str1));
6 System.out.println("str==str2? " + str.equals(str2));
7 }
很明顯,str和str1是相等的(雖然不是同一個對象,但用equals方法判斷是相等的),但它們與str2不相等,這毋庸置疑,因為str2在對象池中重新生成了一個新的對象,其表面值是ABC,那當然與str和str1不相等了。
說完了subString的小插曲,現在回到List是否相等的判斷上來。subList與subString的輸出結果是一樣的嗎?讓事實說話,運行結果如下:c==c1? false c==c2? true
很遺憾,與String類正好相反,同樣是一個sub類型的操作,為什麼會相反呢?c2是通過subList方法從c列表中生成的一個子列表,然後c2又增加了一個元素,可為什麼增加了一個元素還會相等呢?我們從subList的源碼來分析一下:
1 public List<E> subList(int fromIndex, int toIndex) {
2 return (this instanceof RandomAccess ?
3 new RandomAccessSubList<>(this, fromIndex, toIndex) :
4 new SubList<>(this, fromIndex, toIndex));
5 }
subList的方法是由AbstractList實現的,它會根據是不是可以隨機存取來提供不同的SubList實現方式,不過,隨機存取的使用頻率比較高,而且RandomAccessSubList也是subList的子類,所以所有的操作都是由Sublist類實現的(除了自身的SubList方法外),那麼,我們就直接看看SubList類的代碼:
1 class SubList<E> extends AbstractList<E> {
2 //原始列表
3 private final AbstractList<E> l;
4 //偏移量
5 private final int offset;
6 private int size;
7 //構造函數,注意list參數就是我們的原始列表
8 SubList(AbstractList<E> list, int fromIndex, int toIndex) {
9 /*下標校驗代碼 略*/
10 //傳遞原始列表
11 l = list;
12 offset = fromIndex;
13 //子列表的長度
14 size = toIndex - fromIndex;
15 this.modCount = l.modCount;
16 }
17 //獲得制定位置的元素
18 public E get(int index) {
19 /*下標校驗 略*/
20 //從原始字符串中獲得制定位置的元素
21 return l.get(index+offset);
22 }
23 //增加或插入
24 public void add(int index, E element) {
25 /*下標校驗 略*/
26 //直接增加到原始字符串上
27 l.add(index+offset, element);
28 /*處理長度和修改計數器*/
29 }
30 /*其它方法 略*/
31 }
通過閱讀這段代碼,我們就非常清楚subList方法的實現原理了:它返回的SubList類也是AbstractList的子類,其所有的get、set、add、remove等都是在原始列表上的操作,它自身並沒有生成一個新的數組或是鏈表,也就是子列表只是原列表的一個視圖(View)而已。所有的修改動作都映射到了原列表上。
我們例子中的c2增加了一個元素C,不過增加的元素C到了c列表上,兩個變量的元素仍然保持一致,相等也就是自然的了。
解釋完相等的問題,再回過頭來看看變量c與c1不行等的原因,很簡單,因為通過ArrayList構造函數創建的List對象實際上是新列表,它是通過數組的copyOf動作生成的,所生成的列表c1與原列表c之間沒有任何關系(雖然是淺拷貝,但元素類型是String,也就是說元素是深拷貝的),然後c又增加了元素,因為c1與c之間已經沒有一毛線關系了。
注意:subList產生的列表只是一個視圖,所有的修改動作直接作用於原列表。
我們來看這樣一個簡單的需求:一個列表有100個元素,現在要刪除索引位置為20~30的元素。這很簡單,一個遍歷很快就可以完成,代碼如下:
1 public class Client71 {
2 public static void main(String[] args) {
3 // 初始化一個固定長度,不可變列表
4 List<Integer> initData = Collections.nCopies(100, 0);
5 // 轉換為可變列表
6 List<Integer> list = new ArrayList<Integer>(initData);
7 // 遍歷,刪除符合條件的元素
8 for (int i = 0; i < list.size(); i++) {
9 if (i >= 20 && i < 30) {
10 list.remove(i);
11 }
12 }
13 }
14 }
或者將for循環改為:
1 for(int i=20;i<30;i++){
2 if(i<list.size()){
3 list.remove(i);
4 }
5 }
相信首先出現在大家腦海中的實現算法就是此算法了,遍歷一遍,符合條件的刪除,簡單而使用,不過,有沒有其它方式呢?有沒有“one-lining”一行代碼就解決問題的方式呢?
有,直接使用ArrayList的removeRange方法不就可以了嗎?不過好像不可能呀,雖然JDK上由此方法,但是它有protected關鍵字修飾著,不能直接使用,那怎麼辦?看看如下代碼:
1 public static void main(String[] args) {
2 // 初始化一個固定長度,不可變列表
3 List<Integer> initData = Collections.nCopies(100, 0);
4 // 轉換為可變列表
5 List<Integer> list = new ArrayList<Integer>(initData);
6 //刪除指定范圍內的元素
7 list.subList(20, 30).clear();
8 }
上一個建議講了subList方法的具體實現方式,所有的操作都是在原始列表上進行的,那我們就用subList先取出一個子列表,然後清空。因為subList返回的list是原始列表的一個視圖,刪除這個視圖中 的所有元素,最終都會反映到原始字符串上,那麼一行代碼解決問題了。
順便貼一下上面方法調用的源碼:
public void clear() {
removeRange(0, size());
}
1 protected void removeRange(int fromIndex, int toIndex) {
2 ListIterator<E> it = listIterator(fromIndex);
3 for (int i=0, n=toIndex-fromIndex; i<n; i++) {
4 it.next();
5 it.remove();
6 }
7 }
前面說了,subList生成的子列表是原列表的一個視圖,那在subList執行完後,如果修改了原列表的內容會怎樣呢?視圖是否會改變呢?如果是數據庫視圖,表數據變更了,視圖當然會變了,至於subList生成的視圖是否會改變,還是從源碼上來看吧,代碼如下:
1 public class Client72 {
2 public static void main(String[] args) {
3 List<String> list = new ArrayList<String>();
4 list.add("A");
5 list.add("B");
6 list.add("C");
7 List<String> subList = list.subList(0, 2);
8 //原字符串增加一個元素
9 list.add("D");
10 System.out.println("原列表長度:"+list.size());
11 System.out.println("子列表長度:"+subList.size());
12 }
13 }
程序中有一個原始列表,生成了一個子列表,然後在原始列表中增加一個元素,最後打印出原始列表和子列表的長度,大家想一下,這段程序什麼地方會出現錯誤呢?list.add("D")會報錯嗎?不會,subList並沒有鎖定原列表,原列表當然可以繼續修改。難道有size方法?正確,確實是size方法出錯了,輸出結果如下:
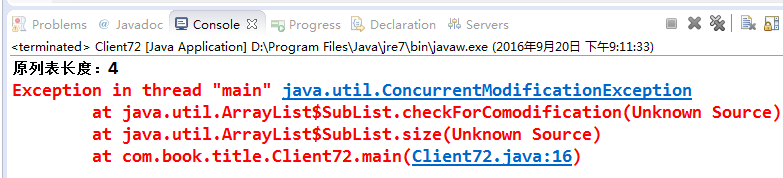
什麼,居然是subList的size方法出現了異常,而且還是並發修改異常?這沒道理呀,這裡根本就沒有多線程操作,何來並發修改呢?這個問題很容易回答,那是因為subList取出的列表是原列表的一個視圖,原數據集(代碼中的lsit變量)修改了,但是subList取出的子列表不會重新生成一個新列表(這點與數據庫視圖是不相同的),後面在對子列表繼續操作時,就會檢測到修改計數器與預期的不相同,於是就拋出了並發修改異常。出現這個問題的最終原因還是在子列表提供的size方法的檢查上,還記得上面幾個例子中經常提到的修改計數器?原因就在這裡,我們來看看size的源代碼:
1 public int size() {
2 checkForComodification();
3 return size;
4 }
其中的checkForComodification()方法就是用於檢測是否並發修改的,代碼如下:
1 private void checkForComodification()
2 {
3 //判斷當前修改計數器是否與子列表生成時一致
4 if(modCount != l.modCount)
5 throw new ConcurrentModificationException();
6 else
7 return;
8 }
modCount 是從什麼地方來的呢?它是在subList子列表的構造函數中賦值的,其值等於生成子列表時的修改次數嗎。因此在生成子列表後再修改原始列表,l.modCount的值就必然比modeCount大1,不再保持相等了,於是就拋出了ConcurrentModificationException異常。
subList的其它方法也會檢測修改計數器,例如set、get、add等方法,若生成子列表後,再修改原列表,這些方法也會拋出ConcurrentModificationException異常。
對於子列表的操作,因為視圖是動態生成的,生成子列表後再操作原列表,必然會導致"視圖 "的不穩定,最有效的方法就是通過Collections.unmodifiableList方法設置列表為只讀狀態,代碼如下:
1 public static void main(String[] args) {
2 List<String> list = new ArrayList<String>();
3 List<String> subList = list.subList(0, 2);
4 //設置列表為只讀狀態
5 list=Collections.unmodifiableList(list);
6 //對list進行只讀操作
7 //......
8 //對subList進行讀寫操作
9 //......
10 }
這在團隊編碼中特別有用,比如我生成了一個list,需要調用其他同事寫的共享方法,但是一些元素是不能修改的,想想看,此時subList方法和unmodifiableList方法配合使用是不是就可以解決我們的問題了呢?防御式編程就是教我們如此做的。
這裡還有一個問題,數據庫的一張表可以有多個視圖,我們的List也可以有多張視圖,也就是可以有多個子列表,但問題是只要生成的子列表多於一個,任何一個子列表都不能修改了,否則就會拋出ConcurrentModificationException異常。
注意:subList生成子列表後,保持原列表的只讀狀態。
在項目開發中,我們經常要對一組數據進行排序,或者升序或者降序,在Java中排序有多種方式,最土的方式就是自己寫排序算法,比如冒泡排序、快速排序、二叉樹排序等,但一般不需要自己寫,JDK已經為我們提供了很多的排序算法,我們采用"拿來主義" 就成了。在Java中,要想給數據排序,有兩種實現方式,一種是實現Comparable接口,一種是實現Comparator接口,這兩者有什麼區別呢?我們來看一個例子,就比如給公司職員按照工號排序吧,先定義一個職員類代碼,如下所示:
1 import org.apache.commons.lang.builder.CompareToBuilder;
2 import org.apache.commons.lang.builder.ToStringBuilder;
3 public class Employee implements Comparable<Employee> {
4 // 工號--按照進入公司的先後順序編碼的
5 private int id;
6 // 姓名
7 private String name;
8 // 職位
9 private Position position;
10
11 public Employee(int _id, String _name, Position _position) {
12 id = _id;
13 name = _name;
14 position = _position;
15 }
16 //getter和setter方法略
17 // 按照Id排序,也就是按照資歷的深淺排序
18 @Override
19 public int compareTo(Employee o) {
20 return new CompareToBuilder().append(id, o.id).toComparison();
21 }
22
23 @Override
24 public String toString() {
25 return ToStringBuilder.reflectionToString(this);
26 }
27
28 }
29 //枚舉類型(三個級別Boss(老板)、經理(Manager)、普通員工(Staff))
30 enum Position {
31 Boss, Manager, Staff
32 }
這是一個簡單的JavaBean,描述的是一個員工的基本信息,其中id是員工編號,按照進入公司的先後順序編碼,position是崗位描述,表示是經理還是普通職員,這是一個枚舉類型。
注意Employee類中的compareTo方法,它是Comparable接口要求必須實現的方法,這裡使用apache的工具類來實現,表明是按照Id的自然序列排序的(也就是升序),現在我們看看如何排序:
1 public static void main(String[] args) {
2 List<Employee> list = new ArrayList<Employee>(5);
3 // 兩個職員
4 list.add(new Employee(1004, "馬六", Position.Staff));
5 list.add(new Employee(1005, "趙七", Position.Staff));
6 // 兩個經理
7 list.add(new Employee(1002, "李四", Position.Manager));
8 list.add(new Employee(1003, "王五", Position.Manager));
9 // 一個老板
10 list.add(new Employee(1001, "張三", Position.Boss));
11 // 按照Id排序,也就是按照資歷排序
12 Collections.sort(list);
13 for (Employee e : list) {
14 System.out.println(e);
15 }
16 }
在收集數據的時候本來應該從老板到員工,為了結果更清晰,故將其打亂,從員工到老板,排序結果如下:
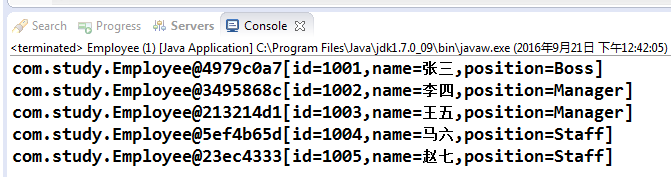
是按照ID升序排列的,結果正確,但是,有時候我們希望按照職位來排序,那怎麼做呢?此時,重構Employee類已經不合適了,Employee已經是一個穩定類,為了排序功能修改它不是一個好辦法,哪有什麼好的解決辦法嗎?
有辦法,看Collections.sort方法,它有一個重載方法Collections.sort(List<T> list, Comparator<? super T> c),可以接收一個Comparator實現類,這下就好辦了,代碼如下:
1 class PositionComparator implements Comparator<Employee> {
2 @Override
3 public int compare(Employee o1, Employee o2) {
4 // 按照職位降序排列
5 return o1.getPosition().compareTo(o2.getPosition());
6 }
7 }
創建了一個職位排序法,依據職位的高低進行降序排列,然後只要Collections.sort(list)修改為Collections.sort(list,new PositionComparator() )即可實現按照職位排序的要求。
現在問題又來了:按職位臨時倒敘排列呢?注意只是臨時的,是否需要重寫一個排序器呢?完全不用,有兩個解決辦法:
第二個問題:先按照職位排序,職位相同再按照工號排序,這如何處理呢?這可是我們經常遇到的實際問題。很好處理,在compareTo或者compare方法中判斷職位是否相等,相等的話再根據工號排序,使用apache工具類來簡化處理,代碼如下:
@Override
public int compareTo(Employee o) {
return new CompareToBuilder().append(position, o.position)
.append(id, o.id).toComparison();
}
在JDK中,對Collections.sort方法的解釋是按照自然順序進行升序排列,這種說法其實不太准確的,sort方法的排序方式並不是一成不變的升序,也可能是倒序,這依賴於compareTo的返回值,我們知道如果compareTo返回負數,表明當前值比對比值小,零表示相等,正數表明當前值比對比值大,比如我們修改一下Employee的compareTo方法,如下所示:
@Override
public int compareTo(Employee o) {
return new CompareToBuilder().append(o.id, id).toComparison();
}
兩個參數調換了一下位置,也就是compareTo的返回值與之前正好相反,再使用Collections.sort進行排序,順序也就相反了,這樣也實現了倒序。
第三個問題:在Java中,為什麼要有兩個排序接口呢?
其實也很好回答,實現了Comparable接口的類表明自身是可以比較的,有了比較才能進行排序,而Comparator接口是一個工具類接口,它的名字(比較器)也已經表明了它的作用:用作比較,它與原有類的邏輯沒有關系,只是實現兩個類的比較邏輯,從這方面來說,一個類可以有很多的比較器,只要有業務需求就可以產生比較器,有比較器就可以產生N多種排序,而Comparable接口的排序只能說是實現類的默認排序算法,一個類穩定、成熟後其compareTo方法基本不會變,也就是說一個類只能有一個固定的、由compareTo方法提供的默認排序算法。
注意:Comparable接口可以作為實現類的默認排序算法,Comparator接口則是一個類的擴展排序工具。
對一個列表進行檢索時,我們使用最多的是indexOf方法,它簡單、好用,而且也不會出錯,雖然它只能檢索到第一個符合條件的值,但是我們可以生成子列表後再檢索,這樣也即可以查找出所有符合條件的值了。
Collections工具類也提供了一個檢索方法,binarySearch,這個是干什麼的?該方法也是對一個列表進行檢索的,可查找出指定值的索引,但是在使用這個方法時就有一些注意事項,我們看如下代碼:
1 public class Client74 {
2 public static void main(String[] args) {
3 List<String> cities = new ArrayList<String> ();
4 cities.add("上海");
5 cities.add("廣州");
6 cities.add("廣州");
7 cities.add("北京");
8 cities.add("天津");
9 //indexOf取得索引值
10 int index1= cities.indexOf("廣州");
11 //binarySearch找到索引值
12 int index2= Collections.binarySearch(cities, "廣州");
13 System.out.println("索引值(indexOf):"+index1);
14 System.out.println("索引值(binarySearch):"+index2);
15 }
16 }
先不考慮運行結果,直接看JDK上對binarySearch的描述:使用二分搜索法搜索指定列表,以獲得指定對象。其實現的功能與indexOf是相同的,只是使用的是二分法搜索列表,所以估計兩種方法返回的結果是一樣的,看結果:
索引值(indexOf):1
索引值(binarySearch):2
結果不一樣,雖然我們說有兩個"廣州" 這樣的元素,但是返回的結果都應該是1才對呀,為何binarySearch返回的結果是2呢?問題就出在二分法搜索上,二分法搜索就是“折半折半再折半” 的搜索方法,簡單,而且效率高。看看JDK是如何實現的。
1 private static final int BINARYSEARCH_THRESHOLD = 5000;
2 public static <T>
3 int binarySearch(List<? extends Comparable<? super T>> list, T key) {
4 if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
5 //隨機存取列表或者元素數量少於5000的順序存取列表
6 return Collections.indexedBinarySearch(list, key);
7 else
8 //元素數量大於5000的順序存取列表
9 return Collections.iteratorBinarySearch(list, key);
10 }
ArrayList實現了RandomAccess接口,是一個順序存取列表,使用了indexedBinarySearch方法,代碼如下:
1 private static <T> int indexedBinarySearch(
2 List<? extends Comparable<? super T>> list, T key) {
3 // 默認商界
4 int low = 0;
5 // 默認下界
6 int high = list.size() - 1;
7
8 while (low <= high) {
9 //中間索引,無符號右移一位
10 int mid = (low + high) >>> 1;
11 //中間值
12 Comparable<? super T> midVal = list.get(mid);
13 //比較中間值
14 int cmp = midVal.compareTo(key);
15 //重置上界和下界
16 if (cmp < 0)
17 low = mid + 1;
18 else if (cmp > 0)
19 high = mid - 1;
20 else
21 //找到元素
22 return mid; // key found
23 }
24 //沒有找到,返回負值
25 return -(low + 1); // key not found
26 }
這也沒啥說的,就是二分法搜索的Java版實現。注意看第10和14行代碼,首先是獲得中間的索引值,我們的例子中也就是2,那索引值是2的元素值是多少呢?正好是“廣州” ,於是就返回索引值2,正確,沒問題,我們再看看indexOf的實現,代碼如下:
1 public int indexOf(Object o) {
2 //null元素查找
3 if (o == null) {
4 for (int i = 0; i < size; i++)
5 if (elementData[i]==null)
6 return i;
7 } else {
8 //非null元素查找
9 for (int i = 0; i < size; i++)
10 //兩個元素是否相等,注意這裡是equals方法
11 if (o.equals(elementData[i]))
12 return i;
13 }
14 return -1;
15 }
indexOf方法就是一個遍歷,找到第一個元素值相等則返回,沒什麼玄機,回到我們的程序來看,for循環的第二遍即是我們要查找的 " 廣州 " ,於是就返回索引值1了,也正確,沒有任何問題。
兩者的算法都沒有問題,難道是我們用錯了。這的確是我們使用的錯誤,因為二分法查詢的一個首要前提是:數據集以實現升序排列,否則二分法查找的值是不准確的。不排序怎麼確定是在小區(比中間值小的區域) 中查找還是在大區(比中間值大的區域)中查找呢?二分法查找必須要先排序,這是二分法查找的首要條件。
問題清楚了,解決辦法很easy,使用Collections.sort排下序即可解決。但這樣真的可以解決嗎?想想看,元素數據是從web或數據庫中傳遞進來的,原本是一個有規則的業務數據,我們為了查找一個元素對它進行了排序,也就是改變了元素在列表中的位置,那誰來保證業務規則的准確性呢?所以說,binarySearch方法在此處受限了,當然,拷貝一個數組,然後再排序,再使用binarySearch查找指定值,也可以解決該問題。
使用binarySearch首先要考慮排序問題,這是我們經常忘記的,而且在測試期間還不好發現問題,等到投入生產環境後才發現查找到的數據不准確,又是一個bug產生了,從這點看,indexOf要比binarySearch簡單的多.
使用binarySearch的二分法查找比indexOf的遍歷算法性能上高很多,特別是在大數據集且目標值又接近尾部時,binarySearch方法與indexOf方法相比,性能上會提升幾十倍,因此從性能的角度考慮時可以選擇binarySearch。