噢,它明白了,河水既沒有牛伯伯說的那麼淺,也沒有小松鼠說的那麼深,只有親自試過才知道。
---寓言故事《小馬過河》
數據處理是每種語言必備的功能,Java更甚之,數據集可以允許重復,也可以不允許重復,可以允許null存在,也可以不允許null存在,可以自動排序,也可以不自動排序,可以是阻塞式的,也可以是非阻塞式的,可以是棧,也可以是隊列......
本章將圍繞我們使用最多的三個數據集合(數組,ArrayList和HashMap)來闡述在開發過程中要注意的事項,並由此延伸至Set、Quene、Stack等集合。
數組在實際的系統開發中用的越來越少了,我們通常只有在閱讀一些開源項目時才會看到它們的身影,在Java中它確實沒有List、Set、Map這些集合類用起來方便,但是在基本類型處理方面,數組還是占優勢的,而且集合類的底層也都是通過數組實現的,比如對一數據集求和這樣的計算:
1 //對數組求和
2 public static int sum(int datas[]) {
3 int sum = 0;
4 for (int i = 0; i < datas.length; i++) {
5 sum += datas[i];
6 }
7 return sum;
8 }
對一個int類型 的數組求和,取出所有數組元素並相加,此算法中如果是基本類型則使用數組效率是最高的,使用集合則效率次之。再看使用List求和:
1 // 對列表求和計算
2 public static int sum(List<Integer> datas) {
3 int sum = 0;
4 for (int i = 0; i < datas.size(); i++) {
5 sum += datas.get(i);
6 }
7 return sum;
8 }
注意看sum += datas.get(i);這行代碼,這裡其實已經做了一個拆箱動作,Integer對象通過intValue方法自動轉換成了一個int基本類型,對於性能瀕於臨界的系統來說該方案是比較危險的,特別是大數量的時候,首先,在初始化List數組時要進行裝箱操作,把一個int類型包裝成一個Integer對象,雖然有整型池在,但不在整型池范圍內的都會產生一個新的Integer對象,而且眾所周知,基本類型是在棧內存中操作的,而對象是堆內存中操作的,棧內存的特點是:速度快,容量小;堆內存的特點是:速度慢,容量大(從性能上講,基本類型的處理占優勢)。其次,在進行求和運算時(或者其它遍歷計算)時要做拆箱動作,因此無謂的性能消耗也就產生了。在實際測試中發現:對基本類型進行求和運算時,數組的效率是集合的10倍。
注意:性能要求較高的場景中使用數組代替集合。
Java中的數組是定長的,一旦經過初始化聲明就不可改變長度,這在實際使用中非常不方便,比如要對班級學生的信息進行統計,因為我們不知道一個班級會有多少學生(隨時都可能會有學生入學、退學或轉學),所以需要一個足夠大的數組來容納所有的學生,但問題是多大才算足夠大?20年前一台台式機64MB的內存已經很牛了,現在要是沒有2GB的內存(現在這個都太小了)你都不好意思跟別人交流計算機的配置,所以呀,這個足夠大是相對於當時的場景而言的,隨著環境的變化,"足夠大"也可能會轉變成"足夠小",然後就會出現超出數組最大容量的情況,那該如何解決呢?事實上,可以通過對數組擴容"婉轉" 地解決該問題,代碼如下:
1 public static <T> T[] expandCapacity(T[] datas, int newLen) {
2 // 不能是負值
3 newLen = newLen < 0 ? 0 : newLen;
4 // 生成一個新數組,並拷貝原值
5 return Arrays.copyOf(datas, newLen);
6 }
上述代碼采用的是Arrays數組工具類的copyOf方法,產生了一個newLen長度的新數組,並把原有的值拷貝了進去,之後就可以對超長的元素進行賦值了(依據類型的不同分別賦值0、false或null),使用方法如下:
public class Client61 {
public static void main(String[] args) {
//一個班級最多容納60個學生
Stu [] stuNums= new Stu[60];
//stuNums初始化......
//偶爾一個班級可以容納80人,數組加長
stuNums=expandCapacity(stuNums,80);
/* 重新初始化超過限額的20人...... */
}
public static <T> T[] expandCapacity(T[] datas, int newLen) {
// 不能是負值
newLen = newLen < 0 ? 0 : newLen;
// 生成一個新數組,並拷貝原值
return Arrays.copyOf(datas, newLen);
}
}
class Stu{
}
通過這樣的處理方式,曲折的解決了數組的變長問題,其實,集合的長度自動維護功能的原理與此類似。在實際開發中,如果確實需要變長的數據集,數組也是在考慮范圍之內的,不能因固定長度而將其否定之。
有這樣一個例子,第一個箱子裡有赤橙黃綠青藍紫7色氣球,現在希望在第二個箱子中也放入7個氣球,其中最後一個氣球改為藍色,也就是赤橙黃綠青藍藍7個氣球,那我們很容易就會想到第二個箱子中的氣球可以通過拷貝第一個箱子中的氣球來實現,畢竟有6個氣球是一樣的嘛,來看實現代碼:
1 import java.util.Arrays;
2 import org.apache.commons.lang.builder.ToStringBuilder;
3
4 public class Client62 {
5 public static void main(String[] args) {
6 // 氣球數量
7 int ballonNum = 7;
8 // 第一個箱子
9 Balloon[] box1 = new Balloon[ballonNum];
10 // 初始化第一個箱子中的氣球
11 for (int i = 0; i < ballonNum; i++) {
12 box1[i] = new Balloon(Color.values()[i], i);
13 }
14 // 第二個箱子的氣球是拷貝第一個箱子裡的
15 Balloon[] box2 = Arrays.copyOf(box1, box1.length);
16 // 修改最後一個氣球顏色
17 box2[6].setColor(Color.Blue);
18 // 打印出第一個箱子中的氣球顏色
19 for (Balloon b : box1) {
20 System.out.println(b);
21 }
22
23 }
24 }
25
26 // 氣球顏色
27 enum Color {
28 Red, Orange, Yellow, Green, Indigo, Blue, Violet
29 }
30
31 // 氣球
32 class Balloon {
33 // 編號
34 private int id;
35 // 顏色
36 private Color color;
37
38 public Balloon(Color _color, int _id) {
39 color = _color;
40 id = _id;
41 }
42
43 public int getId() {
44 return id;
45 }
46
47 public void setId(int id) {
48 this.id = id;
49 }
50
51 public Color getColor() {
52 return color;
53 }
54
55 public void setColor(Color color) {
56 this.color = color;
57 }
58
59 @Override
60 public String toString() {
61 //apache-common-lang包下的ToStringBuilder重寫toString方法
62 return new ToStringBuilder(this).append("編號", id).append("顏色", color).toString();
63 }
64
65 }
第二個箱子裡最後一個氣球的顏色毫無疑問是被修改為藍色了,不過我們是通過拷貝第一個箱子裡的氣球然後再修改的方式來實現的,那會對第一個箱子的氣球顏色有影響嗎?我們看看輸出結果:
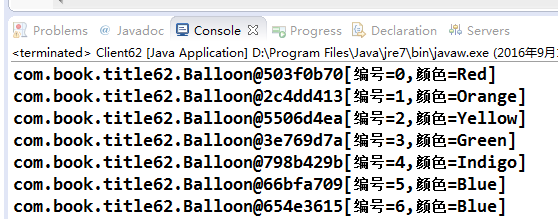
最後一個氣球顏色竟然也被修改了,我們只是希望修改第二個箱子的氣球啊,這是為何?這是典型的淺拷貝(Shallow Clone)問題,以前第一章序列化時講過,但是這裡與之有一點不同:數組中的元素沒有實現Serializable接口。
確實如此,通過copyOf方法產生的數組是一個淺拷貝,這與序列化的淺拷貝完全相同:基本類型是直接拷貝值,其它都是拷貝引用地址。需要說明的是,數組的clone方法也是與此相同的,同樣是淺拷貝,而且集合的clone方法也都是淺拷貝,這就需要大家在拷貝時多留心了。
問題找到了,解決辦法也很簡單,遍歷box1的每個元素,重新生成一個氣球(Balloon)對象,並放置到box2數組中,代碼比較簡單,不再贅述。
該方法用的最多的地方是在使用集合(如List),進行業務處理時,比如發覺需要拷貝集合中的元素,可集合沒有提供拷貝方法,如果自己寫會很麻煩,所以干脆使用List.toArray方法轉換成數組,然後通過Arrays.copyOf拷貝,再轉換回集合,簡單便捷!但是,非常遺憾的是,這裡我們又撞到淺拷貝的槍口上了,雖然很多時候淺拷貝可以解決業務問題,但更多時候會留下隱患,我們需要提防又提防。
我們經常使用ArrayList、Vector、HashMap等集合,一般都是直接用new跟上類名聲明出一個集合來,然後使用add、remove等方法進行操作,而且因為它是自動管理長度的,所以不用我們特別費心超長的問題,這確實是一個非常好的優點,但也有我們必須要注意的事項。
下面以ArrayList為例深入了解一下Java是如何實現長度的動態管理的,先從add方法的閱讀開始,代碼(JDK7)如下:
1 public boolean add(E e) {
2 //擴展長度
3 ensureCapacityInternal(size + 1); // Increments modCount!!
4 //追加元素
5 elementData[size++] = e;
6 return true;
7 }
我們知道ArrayList是一個大小可變的數組,但它在底層使用的是數組存儲(也就是elementData變量),而且數組長度是定長的,要實現動態長度必然要進行長度的擴展,ensureCapacityInternal方法提供了此功能,代碼如下:
private void ensureCapacityInternal(int minCapacity) {
//修改計數器
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
//上次(原始)定義的數組長度
int oldCapacity = elementData.length;
//新長度為原始長度+原始長度右移一位 ==>原始長度的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//數組拷貝,生成新數組
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
大概分析一下這些源碼,這個源碼還是JDK7之前的版本上做了優化處理的。先說一下第一個方法ensureCapacityIntenal, 方法名的英文大致意思是“確保內部容量”,這裡要說明,size表示的是現有的元素個數,並非ArrayList的容量,容量應該是數組 elementData的長度。參數minCapacity是需要檢查的最小容量,即方法的功能就是確保elementData的長度不小於 minCapacity,如果不夠,則調用grow增加容量。容量的增長也算結構性變動,所以modCount需要加1。
grow方法:先對容量擴大1.5倍,這裡oldCapacity >> 1是二進制操作右移,相當於除以2,如果不知道這個面壁去吧。接再來把新的臨時容量(還沒正式改變容量,應該叫預期容量)和實際需要的最小容量比較,如果還不滿 足,則把臨時容量改成需要的最小容量值。在判斷容量是否超過MAX_ARRAY_SIZE的值,MAX_ARRAY_SIZE值為 Integer.MAX_VALUE - 8,比int的最大值小8,不知道設計初衷是什麼,可能方便判斷吧。如果已經超過,調用hugeCapacity方法檢查容量的int值是不是已經溢出。一般很 少用到int最大值的情況,那麼多數據也不會用ArrayList來做容器了,估計沒機會見到hugeCapacity運行一次了。最後確定了新的容量,就使用Arrays.copyOf方法來生成新的數組,copyOf也已經完成了將就的數據拷貝到新數組的工作。
回歸正題,大家注意看數組長度的計算方法,並不是增加一個元素,elementData的長度就加1,而是在達到elementData長度的臨界點時,才將elementData擴容1.5倍,這樣實現避免了多次copyOf方法的性能開銷,否則每增加一個元素都要擴容一次,那性能會更差。不知道大家有沒有這樣一個疑問,為啥要擴容1.5倍,而不是2.5,倍、3.5倍呢?其實我也這麼想過,原因是一次擴容太大,占用的內存就越大,浪費的內存也就越多(1.5倍擴容,最多浪費33%的數組空間,而2.5倍則最多消耗60%的內存),而一次擴容太小,則需要多次對數組重新分配內存,性能消耗嚴重,經過測試驗證,擴容1.5倍既滿足了性能要求,也減少了內存消耗。
現在我們知道了ArrayList的擴容原則,那還有一個問題:elementData的默認長度是多少呢?答案是10,如果我們使用默認方式聲明ArrayList,如new ArrayList(),則elementData的初始長度是10,我們看看ArrayList的三個構造函數。
//無參構造
public ArrayList() {
this(10);
}
//構造一個具有指定初始容量的空列表。
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
//構造一個包含指定 collection 的元素的列表,這些元素是按照該 collection 的迭代器返回它們的順序排列的
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
ArrayList():默認構造函數,提供初始容量為10的空列表。
ArrayList(int initialCapacity):構造一個具有指定初始容量的空列表。
ArrayList(Collection<? extends E> c):構造一個包含指定 collection 的元素的列表,這些元素是按照該 collection 的迭代器返回它們的順序排列的。
從這裡我們可以看出,如果不設置初始容量,系統會按照1.5倍的規則擴容,每次擴容都是一次數組的拷貝,如果數據量大,這樣的拷貝會非常消耗資源,而且效率非常低下。所以,我們如果知道一個ArrayList的可能長度,然後對ArrayList設置一個初始容量則可以顯著提高系統性能。
其它的集合如Vector和ArrayList類似,只是擴容的倍數不同而已,Vector擴容2倍,大家有興趣的話可以看看Vector,HashMap的JDK源碼。
對一批數據進行排序,然後找出其中的最大值或最小值,這是基本的數據結構知識。在Java中我們可以通過編寫算法的方式,也可以通過數組先排序再取值的方式來實現,下面以求最大值為例,解釋一下多種算法:
(1)、自行實現,快速查找最大值
先看看用快速查找法取最大值的算法,代碼如下:
1 public static int max(int[] data) {
2 int max = data[0];
3 for (int i : data) {
4 max = max > i ? max : i;
5 }
6 return max;
7 }
這是我們經常使用的最大值算法,也是速度最快的算法。它不要求排序,只要遍歷一遍數組即可找出最大值。
(2)、先排序,後取值
對於求最大值,也可以采用先排序後取值的方式,代碼如下:
1 public static int max(int[] data) {
2 Arrays.sort(data);
3 return data[data.length - 1];
4 }
從效率上講,當然是自己寫快速查找法更快一些了,只用遍歷一遍就可以計算出最大值,但在實際測試中發現,如果數組量少於10000,兩個基本上沒有區別,但在同一個毫秒級別裡,此時就可以不用自己寫算法了,直接使用數組先排序後取值的方式。
如果數組元素超過10000,就需要依據實際情況來考慮:自己實現,可以提高性能;先排序後取值,簡單,通俗易懂。排除性能上的差異,兩者都可以選擇,甚至後者更方便一些,也更容易想到。
現在問題來了,在代碼中為什麼先使用data.clone拷貝再排序呢?那是因為數組也是一個對象,不拷貝就改變了原有的數組元素的順序嗎?除非數組元素的順序無關緊要。那如果要查找僅次於最大值的元素(也就是老二),該如何處理呢?要注意,數組的元素時可以重復的,最大值可能是多個,所以單單一個排序然後取倒數第二個元素時解決不了問題的。
此時,就需要一個特殊的排序算法了,先要剔除重復數據,然後再排序,當然,自己寫算法也可以實現,但是集合類已經提供了非常好的方法,要是再使用自己寫算法就顯得有點重復造輪子了。數組不能剔除重復數據,但Set集合卻是可以的,而且Set的子類TreeSet還能自動排序,代碼如下:
1 public static int getSecond(Integer[] data) {
2 //轉換為列表
3 List<Integer> dataList = Arrays.asList(data);
4 //轉換為TreeSet,剔除重復元素並升序排列
5 TreeSet<Integer> ts = new TreeSet<Integer>(dataList);
6 //取得比最大值小的最大值,也就是老二了
7 return ts.lower(ts.last());
8 }
剔除重復元素並升序排列,這都是由TreeSet類實現的,然後可再使用lower方法尋找小於最大值的值,大家看,上面的程序非常簡單吧?那如果是我們自己編寫代碼會怎麼樣呢?那至少要遍歷數組兩遍才能計算出老二的值,代碼復雜度將大大提升。因此在實際應用中求最值,包括最大值、最小值、倒數第二小值等,使用集合是最簡單的方式,當然從性能方面來考慮,數組才是最好的選擇。
注意:最值計算時使用集合最簡單,使用數組性能最優。