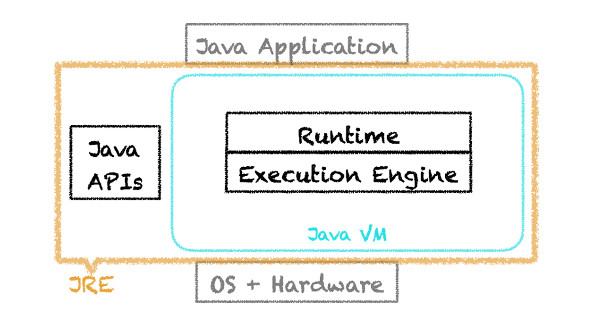
OpenJDK HotSpot Java Virtual Machine被人親切地稱為Java虛擬機或JVM,由兩個主要組件構成:執行引擎和運行時。JVM和Java API組成Java運行環境,也稱為JRE。
在本文中,我們將探討執行引擎,特別是即時編譯,以及OpenJDK HotSpot VM的運行時優化。
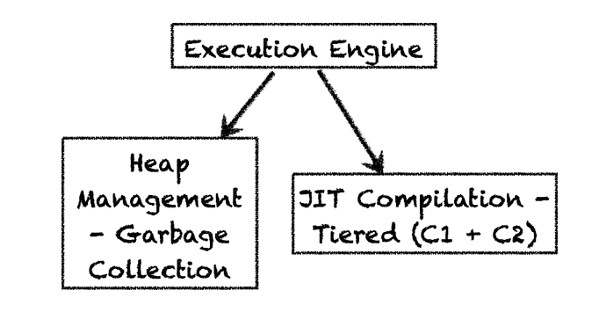
執行引擎由兩個主要組件構成:垃圾回收器(它回收垃圾對象並提供自動的內存或堆管理))以及即時編譯器(它把字節碼轉換為可執行的機器碼)。在OpenJDK 8中,“分層的編譯器”是默認的服務端編譯器。HotSpot也可以通過禁用分層的編譯器(-XX:-TieredCompilation)仍然選擇不分層的服務端編譯器(也稱為“C2”)。我們接下來將了解這些編譯器的更多內容。
JVM的運行時掌控著類的加載、字節碼的驗證和其他以下列出的重要功能。其中一個功能是“解釋”,我們將馬上對其進行深入地探討。你可以點擊此處了解JVM運行時的更多內容。
相關廠商內容
相關贊助商
通過引進分層編譯,OpenJDK HotSpot VM 用戶可以通過使用服務端編譯器改進啟動時間獲得好處。分層編譯有五個編譯層次。在第0層(解釋層)啟動,儀表在這一層提供了性能關鍵方法的信息。很快就會 到達第1層,簡單的C1(客戶端)編譯器,它來優化這段代碼。在第一層沒有性能優化的信息。下面來到第2層,在此只有少數方法是編譯過的(再提一下是通過 客戶端編譯器)。在第2層,為這些少數方法針對進入次數和循環分支收集性能分析信息。第3層將會看到由客戶端編譯器編譯的所有方法及其全部性能優化信息, 最後的第4層只對C2自身有效,是服務端編譯器。
當使用客戶端編譯(第2層之前)時,代碼在啟動期間通過客戶端編譯器予以優化,此時關鍵執行路徑保持預熱。這有助於生成比解釋型代碼更好的性能優化信息。編譯的代碼存在在一個稱為“代碼緩存”的緩存裡。代碼緩存有固定的大小,如果滿了,JVM將停止方法編譯。
分層編譯可以針對每一層設定它自己的臨界值,比如-XX:Tier3MinInvocationThreshold, -XX:Tier3CompileThreshold, -XX:Tier3BackEdgeThreshold。第三層最低調用臨界值為100。而未分層的C1的臨界值為1500,與之對比你會發現會非常頻繁 地發生分層編譯,針對客戶端編譯的方法生成了更多的性能分析信息。於是用於分層編譯的代碼緩存必須要比用於不分層的代碼緩存大得多,所以在OpenJDK 中用於分層編譯的代碼緩存默認大小為240MB,而用於不分層的代碼緩存大小默認只有48MB。
如果代碼緩存滿了,JVM將給出警告標識,鼓勵用戶使用 –XX:ReservedCodeCacheSize 選項去增加代碼緩存的大小。
為了可視化什麼方法會在何時得到編譯,OpenJDK HotSpot VM提供了一個非常有用的命令行選項,叫做-XX:+PrintCompilation,它會報告什麼時候代碼緩存滿了,以及什麼時候編譯停止了。
舉例如下:
567 693 % ! 3 org.h2.command.dml.Insert::insertRows @ 76 (513 bytes) 656 797 n 0 java.lang.Object::clone (native) 779 835 s 4 java.lang.StringBuffer::append (13 bytes)
上面的輸出格式為:
timestamp compilation-id flags tiered-compilation-level class: method <@ osr_bci> code-size <deoptimization>
在此,
timestamp(時間戳) 是JVM開始啟動到此時的時間
compilation-id(編譯器id) 是內部的引用id
flags(標記) 可以是以下其中一種:
%: is_osr_method (是否osr方法@ 針對OSR方法表明字節碼)
s: is_synchronized(是否同步的)
!: has_exception_handler(有異常處理器)
b: is_blocking(是否堵塞)
n: is_native(是否原生)
tiered-compilation(分層的編譯器) 表示當開啟了分層編譯時的編譯層
Method(方法) 將用以下格式表示類和方法 類名::方法
@osr_bci(osr字節碼索引) 是OSR中的字節碼索引
code-size(代碼大小) 字節碼總大小
deoptimization(逆優化)表示一個方法是否是逆優化,以及不會被調用或是僵屍方法(更多詳細內容請見“動態逆優化”一節)。
基於以上關鍵字,我們可以斷定例子中的第一行
567 693 % ! 3 org.h2.command.dml.Insert::insertRows @ 76 (513 bytes)
的timestamp是567,compilation-ide是693。該方法有個以“!”標明的異常處理器。我們還能斷定分層編譯處於第3層, 它是一個OSR方法(以“%”標識的),字節碼索引為76。字節碼總大小為513個字節。請注意513個字節是字節碼的大小而不是編譯碼的大小。
示例的第2行顯示:
656 797 n 0 java.lang.Object::clone (native)
JVM使一個原生方法更容易調用,第3行是:
779 835 s 4 java.lang.StringBuffer::append (13 bytes)
顯示這個方法是在第4層編譯的且是同步的。
動態逆優化
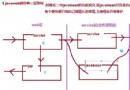
我們知道Java會做動態類加載,JVM在每次動態類加載時檢查內部依賴。當不再需要一個之前優化過的方法時,OpenJDK HotSpot VM將執行該方法的動態逆優化。自適應優化有助於動態逆優化,換句話說,一個動態逆優化的代碼應恢復到它之前編譯層,或者轉到新的編譯層,如下圖所示。 (注意:當在命令行中開啟PrintCompilation時會輸出如下信息):
573 704 2 org.h2.table.Table::fireAfterRow (17 bytes) 7963 2223 4 org.h2.table.Table::fireAfterRow (17 bytes) 7964 704 2 org.h2.table.Table::fireAfterRow (17 bytes) made not entrant 33547 704 2 org.h2.table.Table::fireAfterRow (17 bytes) made zombie
這個輸出顯示timestamp為7963,fireAfterRow是在第4層編譯的。之後的timestamp是7964,之前在第2層編譯的fireAfterRow沒有進入。然後過了一會兒,fireAfterRow標記為僵屍,也就是說,之前的代碼被回收了。
自適應優化的最大一個好處是有能力內聯性能關鍵的方法。通過把調用替換為實際的方法體,有助於規避調用這些關鍵方法的間接開銷。針對內聯有很多基於規模和調用臨界值的“協調”選項,內聯已經得到了充分地研究和優化,幾乎已經挖掘出了最大的潛力。
如果你想投入時間看一下內聯決策,可以使用一個叫做-XX:+PrintInlining的JVM診斷選項。在理解決策時PrintInlining會提供很大的幫助,示例如下:
@ 76 java.util.zip.Inflater::setInput (74 bytes) too big @ 80 java.io.BufferedInputStream::getBufIfOpen (21 bytes) inline (hot) @ 91 java.lang.System::arraycopy (0 bytes) (intrinsic) @ 2 java.lang.ClassLoader::checkName (43 bytes) callee is too large
在這裡你能看到該內聯的位置和被內聯的總字節數。有時你看到如“too big”或“callee is too large”的標簽,這表明因為已經超過臨界值所以未進行內聯。第3行的輸出信息顯示了一個“intrinsic”標簽,讓我們在下一節詳細了解一下 intrinsics(內部函數)。
通常OpenJDK HotSpot VM 即時編譯器將執行為性能關鍵方法生成的代碼,但有時有些方法有非常公共的模式,比如java.lang.System::arraycopy,如前一節中PrintInlining輸出的結果。這些方法可以得到手工優化從而形成更好的性能,優化的代碼類似於擁有你的原生方法,但沒有間接開銷。這些內部函數可以高效地內聯,就像JVM內聯常規方法一樣。
討論內部函數的時候,我喜歡強調一個常用的編譯優化,那就是向量化。向量化可用於任何潛在的平台(處理器),能處理特殊的並行計算或向量指令,比如 “SIMD”指令(單指令、多數據)。SIMD和“向量化”有助於在較大的緩存行規模(64字節)數據量上進行數據層的並行操作。
HotSpot VM提供了兩種不同層次的向量支持:
在第一種情況下,在內部循環的工作過程中配備的樁能為內部循環提供向量支持,而且這個內部循環可以通過向量指令進行優化和替換。這與內部函數是類似的。
在HotSpot VM中SLP支持的理論依據是MIT實驗室的一篇論文。目前,HotSpot VM只優化固定展開次數的目標數組,Vladimir Kozlov舉了以下一個示例,他是Oracle編譯團隊的資深成員,在各種編譯器優化作出了傑出貢獻,其中就包括自動向量化支持。
a[j] = b + c * z[i]
如上代碼展開之後就可以被自動向量化了。
逃逸分析
逃逸分析是自適應優化的另一個額外好處。為判定任何內存分配是否“逃逸”,逃逸分析(縮寫為EA)會將整個中間表示圖考慮進來。也就是說,任意內存分配是否不在下列之一:
如果已分配的對象不是逃逸的,編譯的方法和對象不作為參數傳遞,那麼該內存分配就可以被移除了,這個域的值可以存儲在寄存器中。如果已分配的對象未逃逸已編譯的方法,但作為參數傳遞了,JVM仍然可以移除與該對象有關聯的鎖,當用它比對其他對象時可以使用優化的比對指令。
還有一些自適應即時編譯器一起帶來的一些其他的OpenJDK HotSpot VM優化:
引用:http://www.infoq.com/cn/articles/OpenJDK-HotSpot-What-the-JIT