一、概述
IdentityHashMap也是一類特殊的Map,根據其名字,Identity,即同一性,其表現出的具體特點便是,在判斷Map中的兩個key是否相等時,只通過==來判斷,而不通過equals,也就是說,如果兩個key相同,那麼這兩個key必須是同一個對象。
除此之外,雖然這也是HashMap,即至少是Key的存儲是基於Hash實現的,但其存儲方式跟HashMap還是有很大的不一樣。下面詳細分幾個方面進行說明。
二、實現分析
1. 初始化
可以通過三種方式來構造一個IdentityHashMap, 如下:
public IdentityHashMap() {
init(DEFAULT_CAPACITY);//默認32
}
public IdentityHashMap(int expectedMaxSize) {
if (expectedMaxSize < 0)
throw new IllegalArgumentException("expectedMaxSize is negative: " + expectedMaxSize);
init(capacity(expectedMaxSize));
}
public IdentityHashMap(Map<? extends K, ? extends V> m) {
// Allow for a bit of growth
this((int) ((1 + m.size()) * 1.1));
putAll(m);
}
可以看到,以上三種方式最終都調用了init方法,而傳入的參數即是容器的容量,而第二個方法中,在調用init之前會先對參數值進行處理,其目的是根據當前值構造一個最接近該數值的2的指數倍,這樣,保證初始化時,容量的大小為2的指數倍。
初始化的具體過程如下:
private void init(int initCapacity) {
threshold = (initCapacity * 2)/3; //阈值為初始值的2/3,所以對於默認值32來說,
//其大小為32*2/3=21,這是key的個數
table = new Object[2 * initCapacity];//為什麼*2,因為值也是放在這個table中的
//所以table的size不等於容量
}
代碼很簡單,設置阈值為容量的2/3,並申請一個2倍於容量的數組。之所以這裡要擴大一倍,是因為Map值也存儲於這個數組中,所以,需要與key一一對應。
2.存儲
對於存儲來說,我們還是來看下put的實現
public V put(K key, V value) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
Object item;
while ( (item = tab[i]) != null) {
if (item == k) {
V oldValue = (V) tab[i + 1];
tab[i + 1] = value;
return oldValue;
}
i = nextKeyIndex(i, len);
}
modCount++; //新增加一個
tab[i] = k;
tab[i + 1] = value;
if (++size >= threshold)
resize(len); // len == 2 * current capacity.
return null;
}
private static int nextKeyIndex(int i, int len) {
return (i + 2 < len ? i + 2 : 0);
}
根據上面的業務邏輯,我們將其用流程圖表示如下:
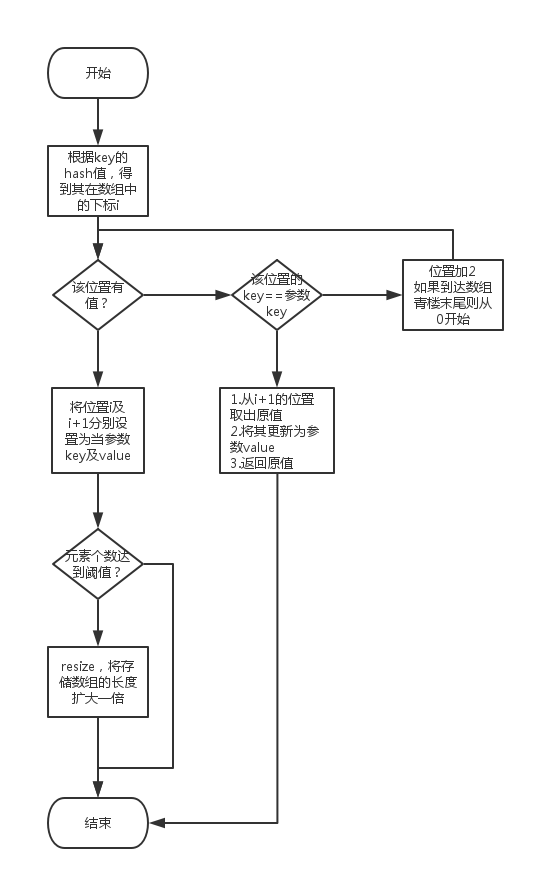
根據流程圖我們不難理解這個邏輯,有幾點需要注意一下:
1)key和value的值實際上都是存儲在數組中的,而且val是挨著key存儲的。
2)當發生沖突的時候,這裡采用的方式是依次找下一個,直到有空的位置,或者找到key應有的位置。
3)因為在超過阈值後會進行resize的操作,table的長度會被擴大一倍,所以步驟2)一定能找到一個空位置,或者找到之前設置的位置。
如果沒有自動擴容機制,則步驟2)很可能會出現死循環。
3. 查找
get方法的實現邏輯如下:
public V get(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);//表的長度,2的n次方
while (true) {
Object item = tab[i];
if (item == k)
return (V) tab[i + 1];
if (item == null)
return null; //那麼這個表示不存在該key, 所以返回null
i = nextKeyIndex(i, len);
}
}
這個過程很簡單,了解了存儲機制後,這個就容易理解了,需要說明的是,如果該位置為null,表示該位置未存儲key, 返回null.
4. 刪除
刪除的業務邏輯如下:
public V remove(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true) {
Object item = tab[i];
if (item == k) {
modCount++;
size--;
V oldValue = (V) tab[i + 1];
tab[i + 1] = null;
tab[i] = null;
closeDeletion(i);
return oldValue;
}
if (item == null) //未找到該key
return null;
i = nextKeyIndex(i, len);
}
}
查找的邏輯還是比較好理解,刪除的話,實際上就是把相應位置的值置null,實現引用的消除,以便垃圾回收。
三、總結
上面我們大致分析了這類Map的存儲機制,總的來說還是比較簡單,和HashMap有類似的地方,但實現方式差別很大。主要差別整理如下 :
1)IdentityHashMap的loadFactor固定為2/3
2)IdentityHashMap的所有key和value都存儲在數組中,key後的下一個位置即是對應的value
3)IdentityHashMap的沖突檢測方式為線性再探測,即找下一個元素再探測,沒有鏈式結構
4)最重要的一點,判斷兩個key是否相同,只根據==來判斷,不使用equals
如果我們的業務需要有第4)點的需求,則可以使用IdentityHashMap.