2016-08-23 關於GC的算法和垃圾收集器的種類就暫且不說了,網上有大把的資料供參考
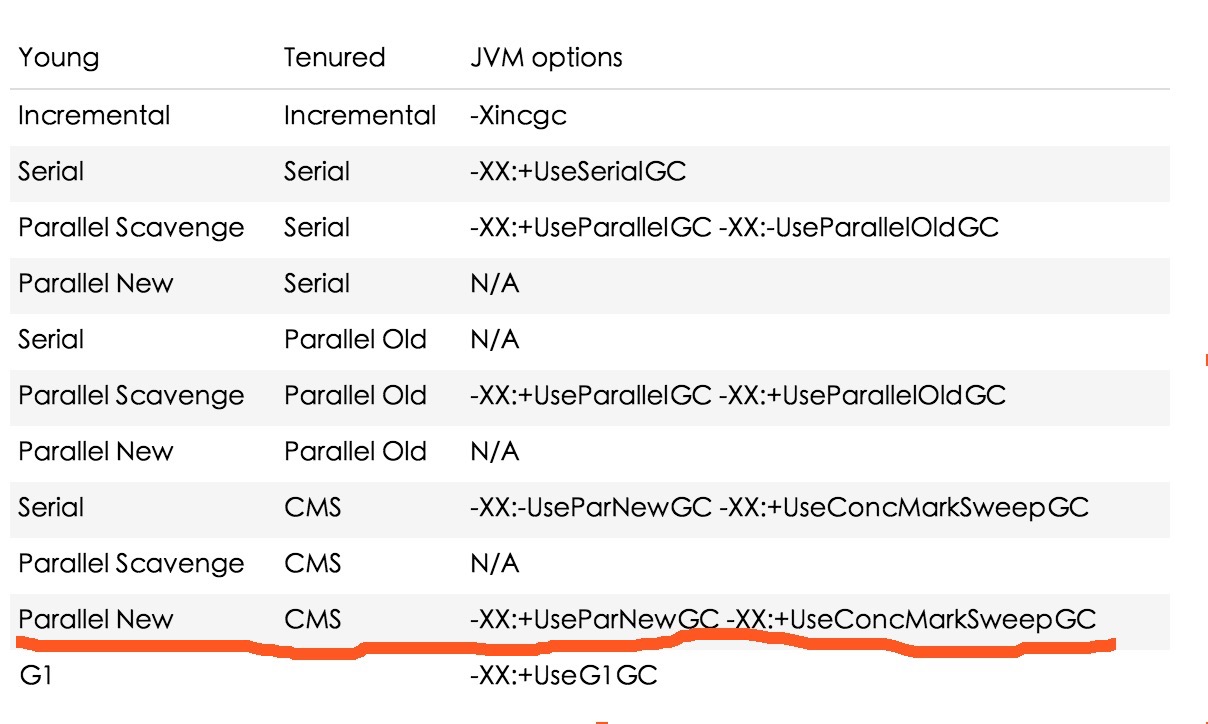
讓我們先簡單的看下整個堆年輕代和年老代的垃圾收集器組合(以下配合java8完美支持,其他版本可能稍有不同),其中標紅線的則是我們今天要著重講的內容:
"Concurrent Mark and Sweep" 是CMS的全稱,官方給予的名稱是:“Mostly Concurrent Mark and Sweep Garbage Collector”;
年輕代:采用 stop-the-world mark-copy 算法;
年老代:采用 Mostly Concurrent mark-sweep 算法;
設計目標:年老代收集的時候避免長時間的暫停;
能夠達成該目標主要因為以下兩個原因:
1 它不會花時間整理壓縮年老代,而是維護了一個叫做 free-lists 的數據結構,該數據結構用來管理那些回收再利用的內存空間;
2 mark-sweep分為多個階段,其中一大部分階段GC的工作是和Application threads的工作同時進行的(當然,gc線程會和用戶線程競爭CPU的時間),默認的GC的工作線程為你服務器物理CPU核數的1/4;
補充:當你的服務器是多核同時你的目標是低延時,那該GC的搭配則是你的不二選擇。
首先對整個GC日志有一個大概的認知
2016-08-23T02:23:07.219-0200: 64.322: [GC (Allocation Failure) 64.322: [ParNew: 613404K->68068K(613440K), 0.1020465 secs] 10885349K->10880154K(12514816K), 0.1021309 secs] [Times: user=0.78 sys=0.01, real=0.11 secs]
2016-08-23T02:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark: 10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2016-08-23T02:23:07.321-0200: 64.425: [CMS-concurrent-mark-start] 2016-08-23T02:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs] 2016-08-23T02:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start] 2016-08-23T02:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] 2016-08-23T02:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start] 2016-08-23T02:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074 secs] [Times: user=0.20 sys=0.00, real=1.07 secs] 2016-08-23T02:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K (613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing, 0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub symbol table, 0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00, real=0.01 secs] 2016-08-23T02:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2016-08-23T02:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs] 2016-08-23T02:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2016-08-23T02:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
2016-08-23T02:23:07.219-02001: 64.3222:[GC3(Allocation Failure4) 64.322: [ParNew5: 613404K->68068K6(613440K)7, 0.1020465 secs8] 10885349K->10880154K9(12514816K)10, 0.1021309 secs11][Times: user=0.78 sys=0.01, real=0.11 secs]12
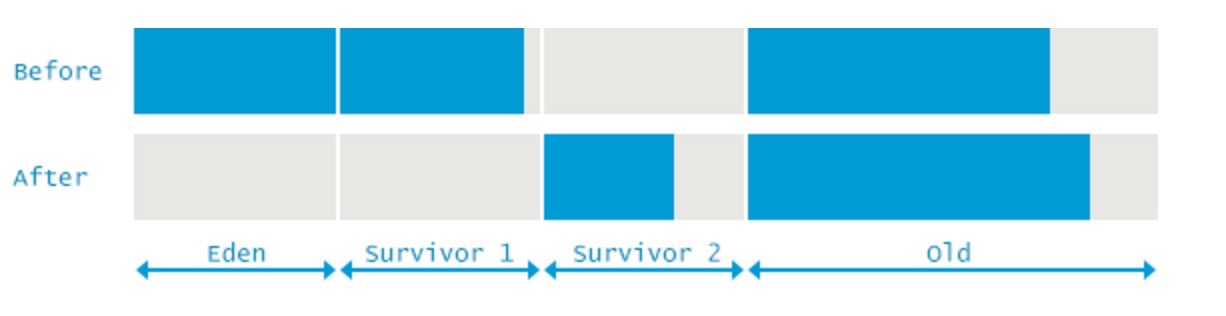
我們來分析下對象晉升問題(原文中的計算方式有問題):
開始的時候:整個堆的大小是 10885349K,年輕代大小是613404K,這說明老年代大小是 10885349-613404=10271945K,
收集完成之後:整個堆的大小是 10880154K,年輕代大小是68068K,這說明老年代大小是 10880154-68068=10812086K,
老年代的大小增加了:10812086-10271945=608209K,也就是說 年輕代到年老代promot了608209K的數據;
圖形分析:
2016-08-23T11:23:07.321-0200: 64.425: [GC (CMS Initial Mark)1 [1 CMS-initial-mark: 10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2016-08-23T11:23:07.321-0200: 64.425: [CMS-concurrent-mark-start] 2016-08-23T11:23:07.357-0200: 64.460: [CMS-concurrent-mark2: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs] 2016-08-23T11:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start] 2016-08-23T11:23:07.373-0200: 64.476: [CMS-concurrent-preclean3: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] 2016-08-23T11:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start] 2016-08-23T11:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean4: 0.167/1.074 secs] [Times: user=0.20 sys=0.00, real=1.07 secs] 2016-08-23T11:23:08.447-0200: 65.550: [GC (CMS Final Remark5)
[YG occupancy: 387920 K (613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559:
[weak refs processing, 0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560:
[scrub symbol table, 0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs]
[Times: user=0.06 sys=0.00, real=0.01 secs] 2016-08-23T11:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2016-08-23T11:23:08.485-0200: 65.588: [CMS-concurrent-sweep6: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs] 2016-08-23T11:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2016-08-23T11:23:08.497-0200: 65.601: [CMS-concurrent-reset7: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
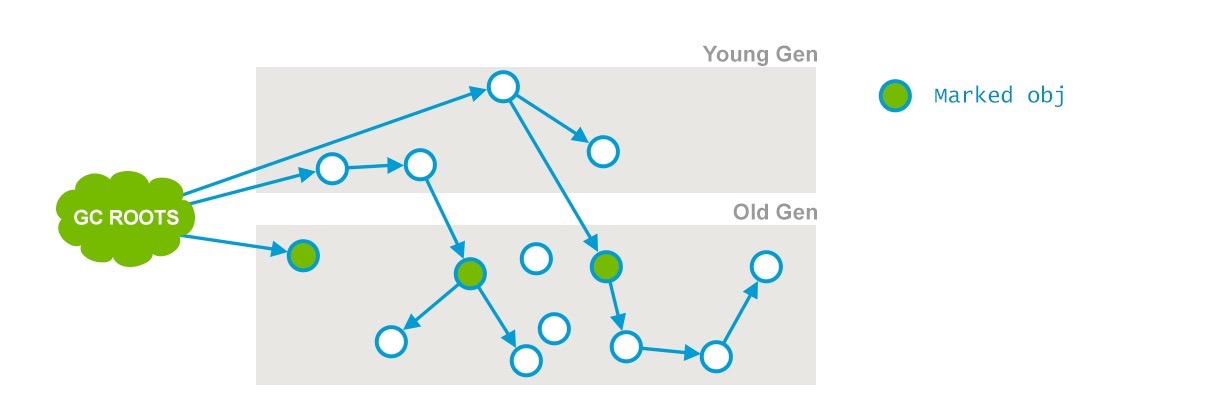
這是CMS中兩次stop-the-world事件中的一次。它有兩個目標:一是標記老年代中所有的GC Roots;二是標記被年輕代中活著的對象引用的對象。
標記結果如下:
分析:
2016-08-23T11:23:07.321-0200: 64.421: [GC (CMS Initial Mark2[1 CMS-initial-mark: 10812086K3(11901376K)4] 10887844K5(12514816K)6, 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]7
這個階段會遍歷整個老年代並且標記所有存活的對象,從“初始化標記”階段找到的GC Roots開始。並發標記的特點是和應用程序線程同時運行。並不是老年代的所有存活對象都會被標記,因為標記的同時應用程序會改變一些對象的引用等。
標記結果如下:
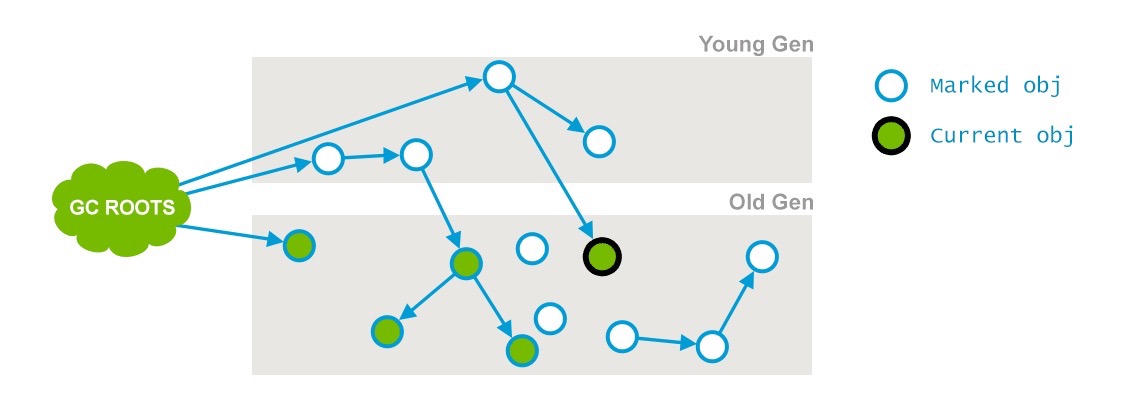
在上邊的圖中,一個引用的箭頭已經遠離了當前對象(current obj)
分析:
2016-08-23T11:23:07.321-0200: 64.425: [CMS-concurrent-mark-start] 2016-08-23T11:23:07.357-0200: 64.460: [CMS-concurrent-mark1: 035/0.035 secs2] [Times: user=0.07 sys=0.00, real=0.03 secs]3
這個階段又是一個並發階段,和應用線程並行運行,不會中斷他們。前一個階段在並行運行的時候,一些對象的引用已經發生了變化,當這些引用發生變化的時候,JVM會標記堆的這個區域為Dirty Card(包含被標記但是改變了的對象,被認為"dirty"),這就是 Card Marking。
如下圖:
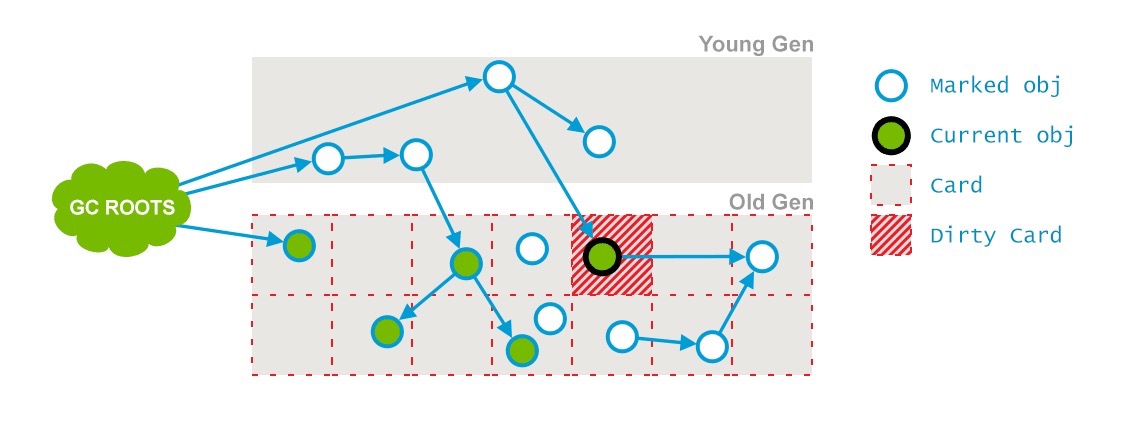
在pre-clean階段,那些能夠從dirty card對象到達的對象也會被標記,這個標記做完之後,dirty card標記就會被清除了,如下:
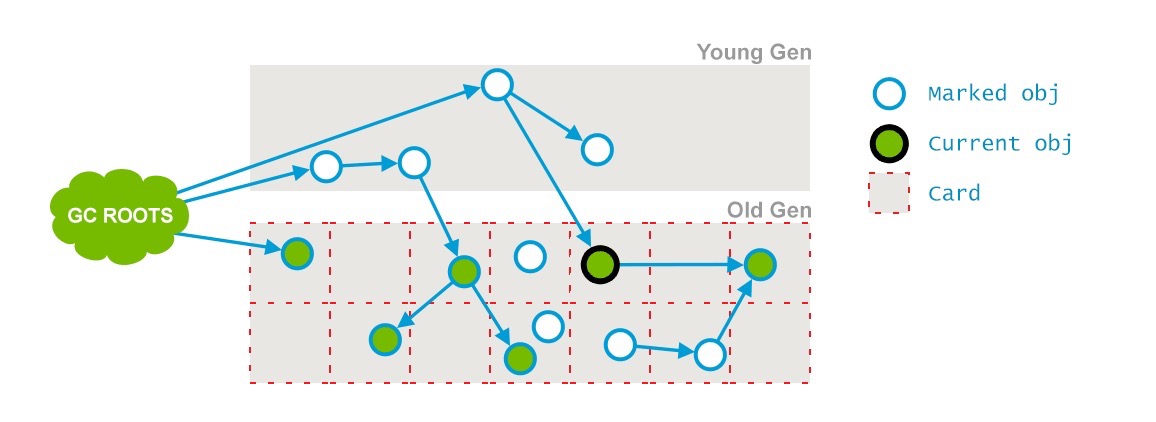
另外,一些必要的清掃工作也會做,還會做一些final remark階段需要的准備工作;
2016-08-23T11:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start] 2016-08-23T11:23:07.373-0200: 64.476: [CMS-concurrent-preclean1: 0.016/0.016 secs2] [Times: user=0.02 sys=0.00, real=0.02 secs]3
又一個並發階段不會停止應用程序線程。這個階段嘗試著去承擔STW的Final Remark階段足夠多的工作。這個階段持續的時間依賴好多的因素,由於這個階段是重復的做相同的事情直到發生aboart的條件(比如:重復的次數、多少量的工作、持續的時間等等)之一才會停止。
2016-08-23T11:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start] 2016-08-23T11:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean1: 0.167/1.074 secs2] [Times: user=0.20 sys=0.00, real=1.07 secs]3
這個階段很大程度的影響著即將來臨的Final Remark的停頓,有相當一部分重要的 configuration options 和 失敗的模式;
這個階段是CMS中第二個並且是最後一個STW的階段。該階段的任務是完成標記整個年老代的所有的存活對象。由於之前的預處理是並發的,它可能跟不上應用程序改變的速度,這個時候,STW是非常需要的來完成這個嚴酷考驗的階段。
通常CMS盡量運行Final Remark階段在年輕代是足夠干淨的時候,目的是消除緊接著的連續的幾個STW階段。
分析:
2016-08-23T11:23:08.447-0200: 65.5501: [GC (CMS Final Remark2) [YG occupancy: 387920 K (613440 K)3]65.550: [Rescan (parallel) , 0.0085125 secs]465.559: [weak refs processing, 0.0000243 secs]65.5595: [class unloading, 0.0013120 secs]65.5606: [scrub string table, 0.0001759 secs7][1 CMS-remark: 10812086K(11901376K)8] 11200006K(12514816K) 9, 0.0110730 secs10] [[Times: user=0.06 sys=0.00, real=0.01 secs]11
通過以上5個階段的標記,老年代所有存活的對象已經被標記並且現在要通過Garbage Collector采用清掃的方式回收那些不能用的對象了。
和應用線程同時進行,不需要STW。這個階段的目的就是移除那些不用的對象,回收他們占用的空間並且為將來使用。
如圖:
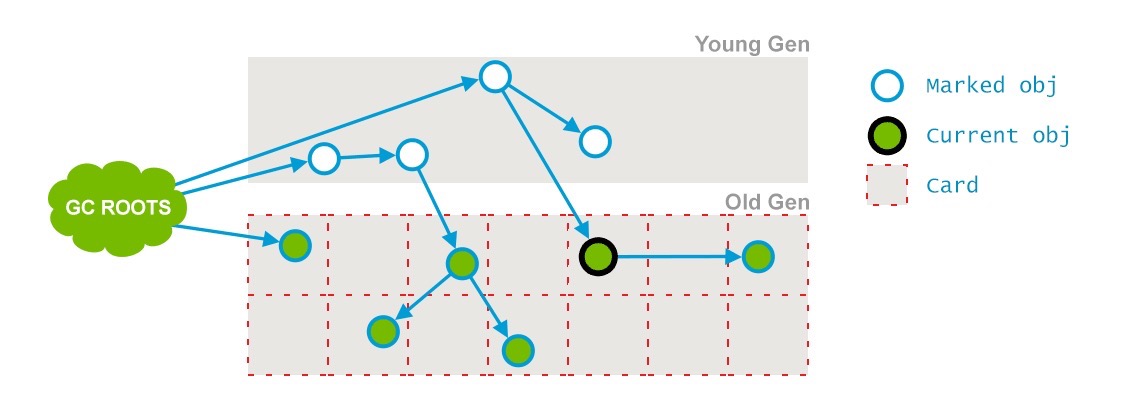
分析:
2016-08-23T11:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2016-08-23T11:23:08.485-0200: 65.588: [CMS-concurrent-sweep1: 0.027/0.027 secs2] [[Times: user=0.03 sys=0.00, real=0.03 secs] 3
這個階段並發執行,重新設置CMS算法內部的數據結構,准備下一個CMS生命周期的使用。
2016-08-23T11:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2016-08-23T11:23:08.497-0200: 65.601: [CMS-concurrent-reset1: 0.012/0.012 secs2] [[Times: user=0.01 sys=0.00, real=0.01 secs]3
https://plumbr.eu/handbook/garbage-collection-algorithms-implementations#concurrent-mark-and-sweep