HBase的數據寫入操作,會先記錄到HLog中,再真正寫入到MemStore中。
前者是對寫入友好的格式,後者是對查詢友好的格式。所以前者吞吐量更高,寫入成功率大,提高了系統的可靠性,“基本”可以實現宕機後繼續沒有完成的數據更新操作。
WAL interface提供了對外的WAL API。其中最常用的方法是append()。
long append(HRegionInfo info, WALKey key, WALEdit edits, boolean inMemstore) throws IOException;
它追加寫入一系列WALEdit。
每一個HBase region有一個單獨的WAL interface的實例:

HBase客戶端 == Protobuf協議 ==> HRegionServer.execRegionServerService() => MultiRowMutationProtos.callMethod() => MultiRowMutationProtos.mutateRows()=> MultiRowMutationEndpoint.mutateRows() => HRegion.processRowsWithLocks() =>HRegion.doWALAppend()會寫入WAL。
HRegion.processRowsWithLocks()是HRegion更新操作的總控方法——驅動了 獲取所、寫入WAL、寫入MemStore 這一流程。
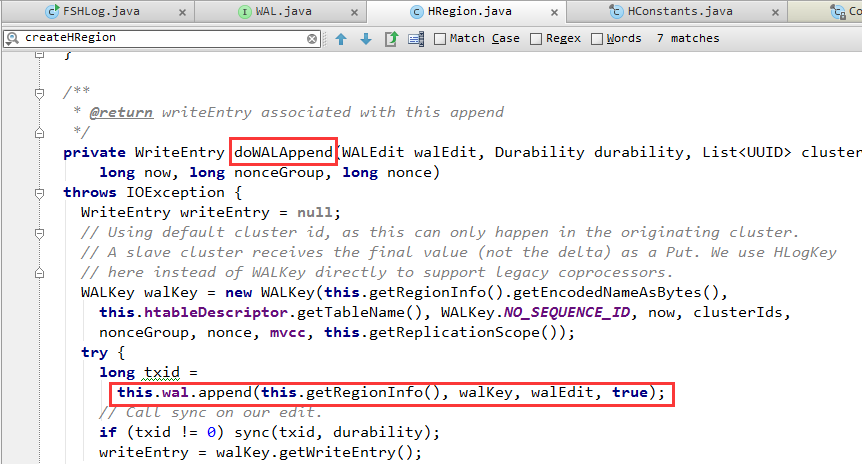
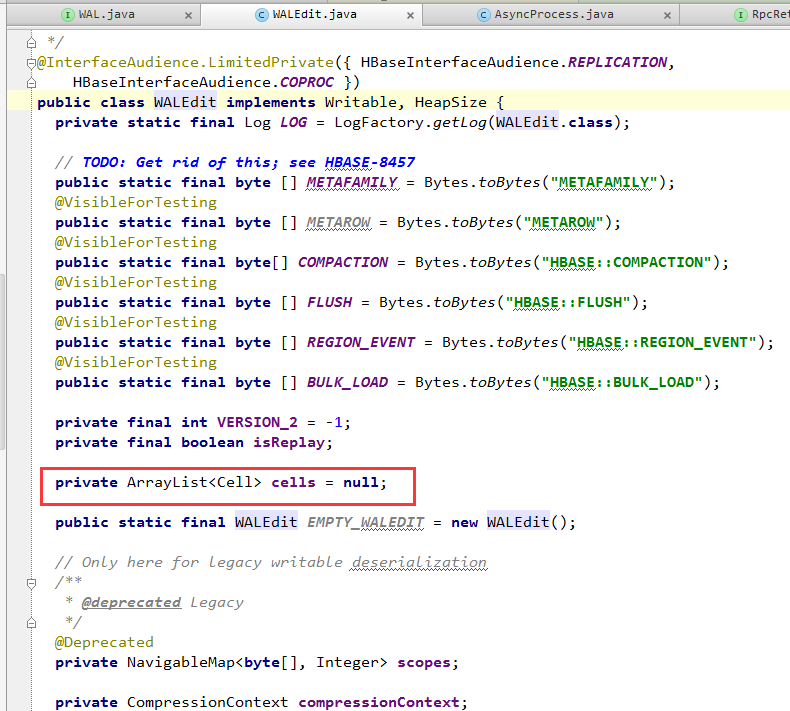
為了實現HBase寫入一行裡的多個列時的原子性,對一行上所有列(即所有KeyValue)的更新操作,都包含在同一個WALEdit對象中:

所以WALEdit中最主要的成員變量,是一系列KeyValue(也就是Cell)的集合:
所謂Flush應該是指將這個Region的業務數據從MemStore寫入Store。
如果一個Region被Flush了,那麼其業務數據已經落地到了HFile中。則這個Region的WAL日志(數據操作記錄)就沒有必要存在了,可以刪除,以騰出磁盤空間。
AbstractFSWAL.findRegionsToForceFlush() 用於找到已經被Flush的、相應WAL日志可以被刪除的Region。
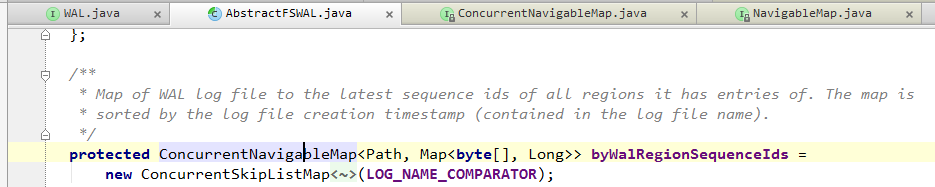
1. 從AbstractFWSAL.byWalRegionSequenceIds找到第一個文件。
ConcurrentNavigableMap<Path, Map<byte[], Long>> byWalRegionSequenceIds 維護了當前WAL的所有文件,以及每個文件所涉及的Region (包括Region的byte[]名稱和這個Region中最後一次append操作的sequence id)
即 Path (WAL文件名) => (byte[] Region名稱, Long sequence id)
2. 從第一個文件,找到它的所有Region中,哪些還沒有被Flush
ConcurrentMap<byte[], ConcurrentMap<byte[], Long>> AbstractFWSAL.SequenceIdAccounting.lowestUnflushedSequenceIds 維護了byte[] Region名稱 + byte[] family名稱 到第一個(即最小的)沒有被Flush的sequence id的映射,稱為lowestUnflushedSequenceId。這裡,每一次append操作對應一個自增的sequence id。所有大於等於lowestUnflushedSequenceId的sequence id,其對應的append操作都沒有被Flush。
因此對於第一步得到的第一個WAL日志文件所涉及的所有Region, 和每個Region的最大sequence id,如果這個最大的sequece id大於這個Region的lowestUnflushedSequenceId,說明這個Region有WAL日志還沒有被Flush。那麼這個Region就會被包含在findRegionsToForceFlush()的結果中。