順序一致性內存模型是一個理論參考模型,JMM 和處理器內存模型在設計時通常會把順序一致性內存模型作為參照。JMM 和處理器內存模型在設計時會對順序一致性模型做一些放松,因為如果完全按照順序一致性模型來實現處理器和 JMM,那麼很多的處理器和編譯器優化都要被禁止,這對執行性能將會有很大的影響。
根據對不同類型讀/寫操作組合的執行順序的放松,可以把常見處理器的內存模型劃分為下面幾種類型:
注意,這裡處理器對讀/寫操作的放松,是以兩個操作之間不存在數據依賴性為前提的(因為處理器要遵守 as-if-serial 語義,處理器不會對存在數據依賴性的兩個內存操作做重排序)。
下面的表格展示了常見處理器內存模型的細節特征:
內存模型名稱 對應的處理器 Store-Load 重排序 Store-Store重排序 Load-Load 和Load-Store重排序 可以更早讀取到其它處理器的寫 可以更早讀取到當前處理器的寫 TSO sparc-TSOX64 Y Y PSO sparc-PSO Y Y Y RMO ia64 Y Y Y Y PowerPC PowerPC Y Y Y Y Y在這個表格中,我們可以看到所有處理器內存模型都允許寫-讀重排序,原因在第一章以說明過:它們都使用了寫緩存區,寫緩存區可能導致寫-讀操作重排序。同時,我們可以看到這些處理器內存模型都允許更早讀到當前處理器的寫,原因同樣是因為寫緩存區:由於寫緩存區僅對當前處理器可見,這個特性導致當前處理器可以比其他處理器先看到臨時保存在自己的寫緩存區中的寫。
上面表格中的各種處理器內存模型,從上到下,模型由強變弱。越是追求性能的處理器,內存模型設計的會越弱。因為這些處理器希望內存模型對它們的束縛越少越好,這樣它們就可以做盡可能多的優化來提高性能。
由於常見的處理器內存模型比 JMM 要弱,java 編譯器在生成字節碼時,會在執行指令序列的適當位置插入內存屏障來限制處理器的重排序。同時,由於各種處理器內存模型的強弱並不相同,為了在不同的處理器平台向程序員展示一個一致的內存模型,JMM 在不同的處理器中需要插入的內存屏障的數量和種類也不相同。下圖展示了 JMM 在不同處理器內存模型中需要插入的內存屏障的示意圖:
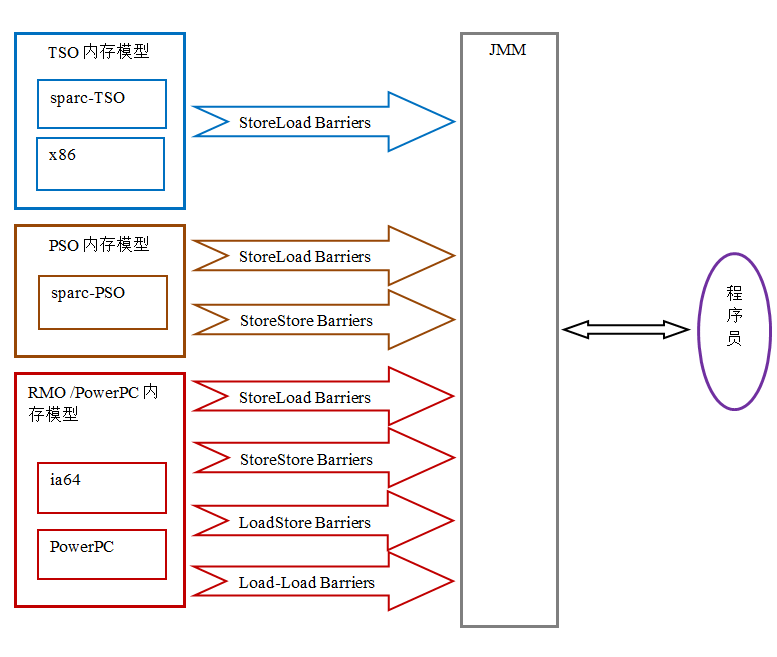
如上圖所示,JMM 屏蔽了不同處理器內存模型的差異,它在不同的處理器平台之上為 java 程序員呈現了一個一致的內存模型。
JMM 是一個語言級的內存模型,處理器內存模型是硬件級的內存模型,順序一致性內存模型是一個理論參考模型。下面是語言內存模型,處理器內存模型和順序一致性內存模型的強弱對比示意圖:
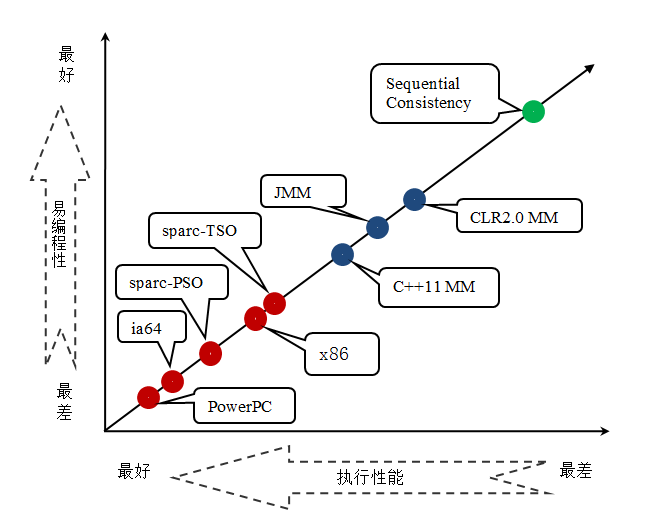
從上圖我們可以看出:常見的4種處理器內存模型比常用的3中語言內存模型要弱,處理器內存模型和語言內存模型都比順序一致性內存模型要弱。同處理器內存模型一樣,越是追求執行性能的語言,內存模型設計的會越弱。
從 JMM 設計者的角度來說,在設計 JMM 時,需要考慮兩個關鍵因素:
由於這兩個因素互相矛盾,所以 JSR-133 專家組在設計 JMM 時的核心目標就是找到一個好的平衡點:一方面要為程序員提供足夠強的內存可見性保證;另一方面,對編譯器和處理器的限制要盡可能的放松。下面讓我們看看 JSR-133 是如何實現這一目標的。
為了具體說明,請看前面提到過的計算圓面積的示例代碼:
double pi = 3.14; //A double r = 1.0; //B double area = pi * r * r; //C
上面計算圓的面積的示例代碼存在三個 happens- before 關系:
由於 A happens- before B,happens- before 的定義會要求:A 操作執行的結果要對B可見,且 A 操作的執行順序排在B操作之前。 但是從程序語義的角度來說,對A和B做重排序即不會改變程序的執行結果,也還能提高程序的執行性能(允許這種重排序減少了對編譯器和處理器優化的束縛)。也就是說,上面這3個 happens- before 關系中,雖然2和3是必需要的,但1是不必要的。因此,JMM 把 happens- before 要求禁止的重排序分為了下面兩類:
JMM 對這兩種不同性質的重排序,采取了不同的策略:
下面是JMM的設計示意圖:
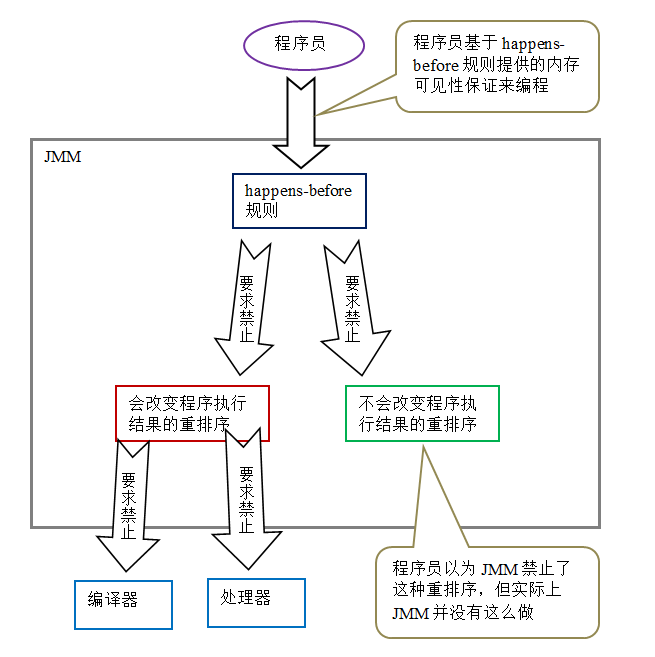
從上圖可以看出兩點:
Java 程序的內存可見性保證按程序類型可以分為下列三類:
下圖展示了這三類程序在 JMM 中與在順序一致性內存模型中的執行結果的異同:
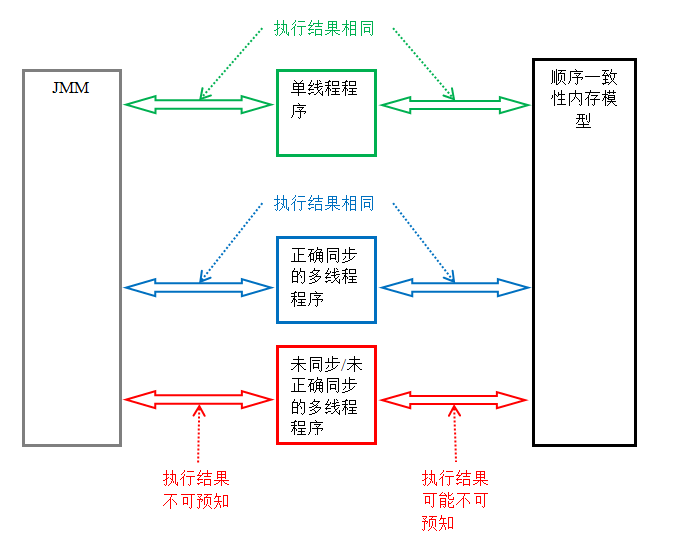
只要多線程程序是正確同步的,JMM 保證該程序在任意的處理器平台上的執行結果,與該程序在順序一致性內存模型中的執行結果一致。
JSR-133 對 JDK5 之前的舊內存模型的修補主要有兩個: