鎖是 java 並發編程中最重要的同步機制。鎖除了讓臨界區互斥執行外,還可以讓釋放鎖的線程向獲取同一個鎖的線程發送消息。下面是鎖釋放-獲取的示例代碼:
class MonitorExample {
int a = 0;
public synchronized void writer() { //1
a++; //2
} //3
public synchronized void reader() { //4
int i = a; //5
……
} //6
}
假設線程 A 執行 writer() 方法,隨後線程 B 執行 reader() 方法。根據 happens before 規則,這個過程包含的 happens before 關系可以分為兩類:
上述 happens before 關系的圖形化表現形式如下:
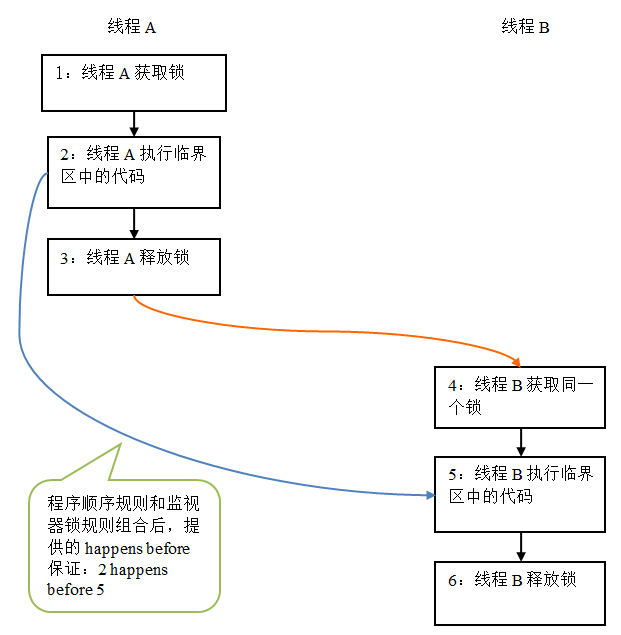
在上圖中,每一個箭頭鏈接的兩個節點,代表了一個 happens before 關系。黑色箭頭表示程序順序規則;橙色箭頭表示監視器鎖規則;藍色箭頭表示組合這些規則後提供的 happens before保證。
上圖表示在線程A釋放了鎖之後,隨後線程B獲取同一個鎖。在上圖中,2 happens before 5。因此,線程A在釋放鎖之前所有可見的共享變量,在線程B獲取同一個鎖之後,將立刻變得對B線程可見。
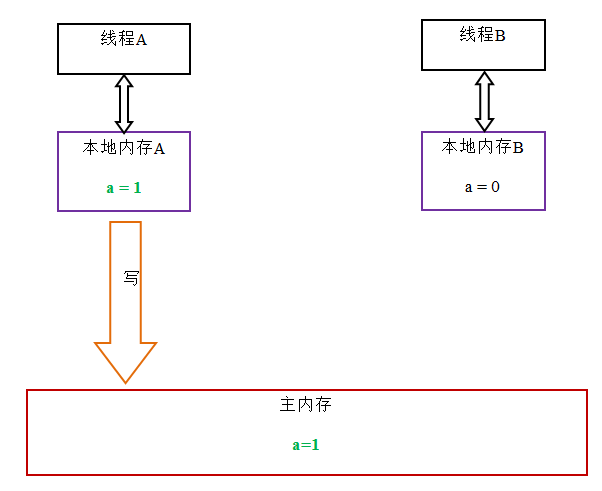
當線程釋放鎖時,JMM 會把該線程對應的本地內存中的共享變量刷新到主內存中。以上面的MonitorExample 程序為例,A線程釋放鎖後,共享數據的狀態示意圖如下:
當線程獲取鎖時,JMM 會把該線程對應的本地內存置為無效。從而使得被監視器保護的臨界區代碼必須要從主內存中去讀取共享變量。下面是鎖獲取的狀態示意圖:
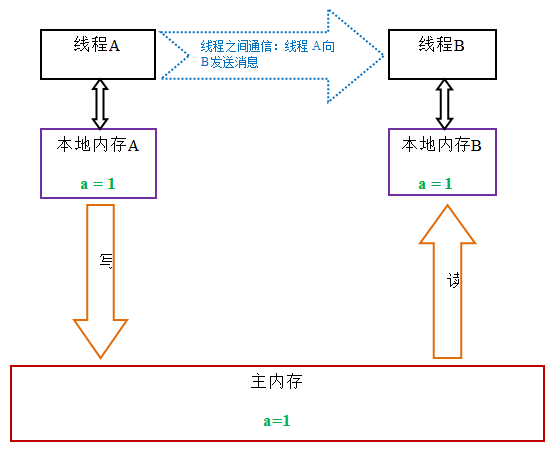
對比鎖釋放-獲取的內存語義與 volatile 寫-讀的內存語義,可以看出:鎖釋放與 volatile 寫有相同的內存語義;鎖獲取與 volatile 讀有相同的內存語義。
下面對鎖釋放和鎖獲取的內存語義做個總結:
本文將借助 ReentrantLock 的源代碼,來分析鎖內存語義的具體實現機制。
請看下面的示例代碼:
class ReentrantLockExample {
int a = 0;
ReentrantLock lock = new ReentrantLock();
public void writer() {
lock.lock(); //獲取鎖
try {
a++;
} finally {
lock.unlock(); //釋放鎖
}
}
public void reader () {
lock.lock(); //獲取鎖
try {
int i = a;
……
} finally {
lock.unlock(); //釋放鎖
}
}
}
在 ReentrantLock 中,調用 lock() 方法獲取鎖;調用 unlock() 方法釋放鎖。
ReentrantLock 的實現依賴於 java 同步器框架 AbstractQueuedSynchronizer(本文簡稱之為AQS)。AQS 使用一個整型的 volatile 變量(命名為 state)來維護同步狀態,馬上我們會看到,這個 volatile 變量是 ReentrantLock 內存語義實現的關鍵。 下面是ReentrantLock 的類圖(僅畫出與本文相關的部分):
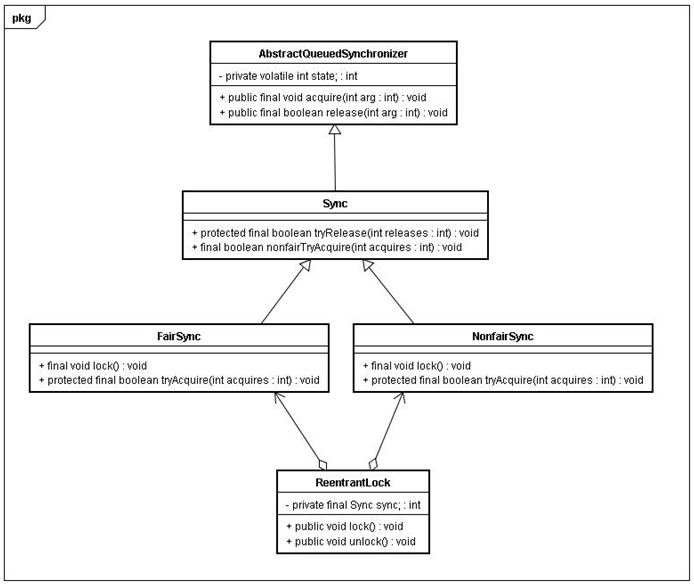
ReentrantLock 分為公平鎖和非公平鎖,我們首先分析公平鎖。
使用公平鎖時,加鎖方法 lock() 的方法調用軌跡如下:
在第4步真正開始加鎖,下面是該方法的源代碼:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState(); //獲取鎖的開始,首先讀volatile變量state
if (c == 0) {
if (isFirst(current) &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
從上面源代碼中我們可以看出,加鎖方法首先讀 volatile 變量 state。
在使用公平鎖時,解鎖方法 unlock() 的方法調用軌跡如下:
在第3步真正開始釋放鎖,下面是該方法的源代碼:
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c); //釋放鎖的最後,寫volatile變量state
return free;
}
從上面的源代碼我們可以看出,在釋放鎖的最後寫 volatile 變量 state。
公平鎖在釋放鎖的最後寫 volatile 變量 state;在獲取鎖時首先讀這個 volatile 變量。根據 volatile 的 happens-before 規則,釋放鎖的線程在寫 volatile 變量之前可見的共享變量,在獲取鎖的線程讀取同一個 volatile 變量後將立即變的對獲取鎖的線程可見。
現在我們分析非公平鎖的內存語義的實現。
非公平鎖的釋放和公平鎖完全一樣,所以這裡僅僅分析非公平鎖的獲取。
使用非公平鎖時,加鎖方法 lock() 的方法調用軌跡如下:
在第3步真正開始加鎖,下面是該方法的源代碼:
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
該方法以原子操作的方式更新 state 變量,本文把 java 的 compareAndSet() 方法調用簡稱為 CAS。JDK 文檔對該方法的說明如下:如果當前狀態值等於預期值,則以原子方式將同步狀態設置為給定的更新值。此操作具有 volatile 讀和寫的內存語義。
這裡我們分別從編譯器和處理器的角度來分析,CAS 如何同時具有 volatile 讀和 volatile 寫的內存語義。
前文我們提到過,編譯器不會對 volatile 讀與 volatile 讀後面的任意內存操作重排序;編譯器不會對 volatile 寫與 volatile 寫前面的任意內存操作重排序。組合這兩個條件,意味著為了同時實現 volatile 讀和 volatile 寫的內存語義,編譯器不能對 CAS 與 CAS 前面和後面的任意內存操作重排序。
下面我們來分析在常見的 intel x86 處理器中,CAS 是如何同時具有 volatile 讀和 volatile 寫的內存語義的。
下面是 sun.misc.Unsafe 類的 compareAndSwapInt() 方法的源代碼:
public final native boolean compareAndSwapInt(Object o, long offset,
int expected,
int x); 可以看到這是個本地方法調用。這個本地方法在 openjdk 中依次調用的 C++ 代碼為:unsafe.cpp,atomic.cpp 和 atomicwindowsx86.inline.hpp。這個本地方法的最終實現在 openjdk 的如下位置:openjdk-7-fcs-src-b147-27jun2011\openjdk\hotspot\src\oscpu\windowsx86\vm\ atomicwindowsx86.inline.hpp(對應於 windows 操作系統,X86 處理器)。下面是對應於 intel x86 處理器的源代碼的片段:
// Adding a lock prefix to an instruction on MP machine
// VC++ doesn't like the lock prefix to be on a single line
// so we can't insert a label after the lock prefix.
// By emitting a lock prefix, we can define a label after it.
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \
__asm je L0 \
__asm _emit 0xF0 \
__asm L0:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
如上面源代碼所示,程序會根據當前處理器的類型來決定是否為 cmpxchg 指令添加 lock 前綴。如果程序是在多處理器上運行,就為 cmpxchg 指令加上 lock 前綴(lock cmpxchg)。反之,如果程序是在單處理器上運行,就省略 lock 前綴(單處理器自身會維護單處理器內的順序一致性,不需要 lock 前綴提供的內存屏障效果)。
intel 的手冊對 lock 前綴的說明如下:
上面的第2點和第3點所具有的內存屏障效果,足以同時實現 volatile 讀和 volatile 寫的內存語義。
經過上面的這些分析,現在我們終於能明白為什麼 JDK 文檔說 CAS 同時具有 volatile 讀和volatile 寫的內存語義了。
現在對公平鎖和非公平鎖的內存語義做個總結:
從本文對 ReentrantLock 的分析可以看出,鎖釋放-獲取的內存語義的實現至少有下面兩種方式:
由於 java 的 CAS 同時具有 volatile 讀和 volatile 寫的內存語義,因此 Java 線程之間的通信現在有了下面四種方式:
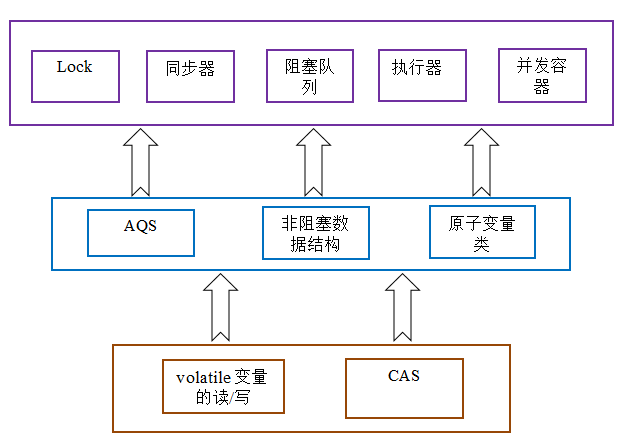
Java 的 CAS 會使用現代處理器上提供的高效機器級別原子指令,這些原子指令以原子方式對內存執行讀-改-寫操作,這是在多處理器中實現同步的關鍵(從本質上來說,能夠支持原子性讀-改-寫指令的計算機器,是順序計算圖靈機的異步等價機器,因此任何現代的多處理器都會去支持某種能對內存執行原子性讀-改-寫操作的原子指令)。同時,volatile 變量的讀/寫和 CAS 可以實現線程之間的通信。把這些特性整合在一起,就形成了整個 concurrent 包得以實現的基石。如果我們仔細分析 concurrent 包的源代碼實現,會發現一個通用化的實現模式:
AQS,非阻塞數據結構和原子變量類(java.util.concurrent.atomic 包中的類),這些 concurrent 包中的基礎類都是使用這種模式來實現的,而 concurrent 包中的高層類又是依賴於這些基礎類來實現的。從整體來看,concurrent 包的實現示意圖如下: