HashMap 和 HashSet 是 Java Collection Framework 的兩個重要成員,其中 HashMap 是 Map 接口的常用實現類,HashSet 是 Set 接口的常用實現類。雖然 HashMap 和 HashSet 實現的接口規范不同,但它們底層的 Hash 存儲機制完全一樣,甚至 HashSet 本身就采用 HashMap 來實現的。
實際上,HashSet 和 HashMap 之間有很多相似之處,對於 HashSet 而言,系統采用 Hash 算法決定集合元素的存儲位置,這樣可以保證能快速存、取集合元素;對於 HashMap 而言,系統 key-value 當成一個整體進行處理,系統總是根據 Hash 算法來計算 key-value 的存儲位置,這樣可以保證能快速存、取 Map 的 key-value 對。
在介紹集合存儲之前需要指出一點:雖然集合號稱存儲的是 Java 對象,但實際上並不會真正將 Java 對象放入 Set 集合中,只是在 Set 集合中保留這些對象的引用而言。也就是說:Java 集合實際上是多個引用變量所組成的集合,這些引用變量指向實際的 Java 對象。
就像引用類型的數組一樣,當我們把 Java 對象放入數組之時,並不是真正的把 Java 對象放入數組中,只是把對象的引用放入數組中,每個數組元素都是一個引用變量。
當程序試圖將多個 key-value 放入 HashMap 中時,以如下代碼片段為例:
HashMap<String , Double> map = new HashMap<String , Double>();
map.put("語文" , 80.0);
map.put("數學" , 89.0);
map.put("英語" , 78.2);
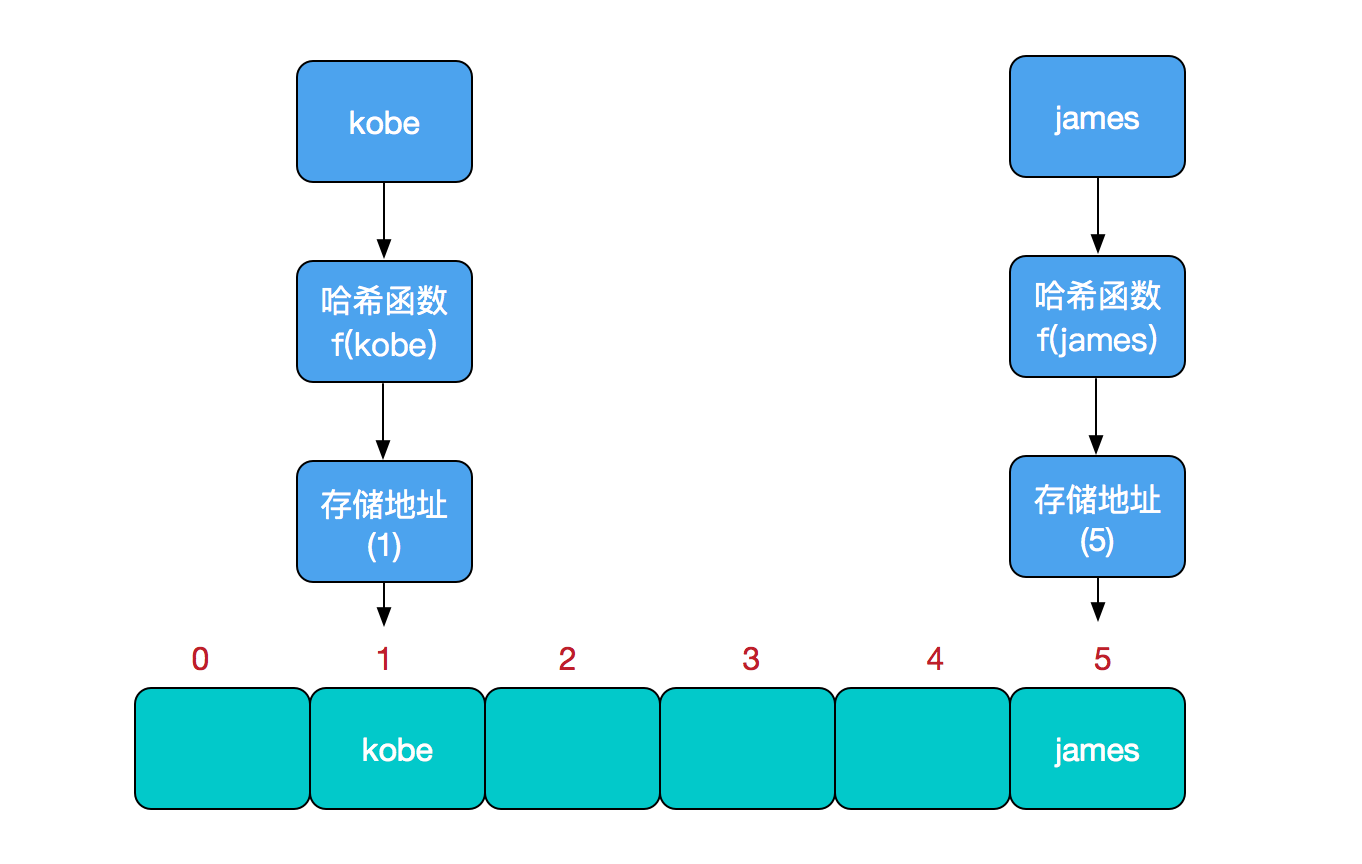
HashMap 采用一種所謂的“Hash 算法”來決定每個元素的存儲位置。
當程序執行 map.put("語文" , 80.0); 時,系統將調用"語文"的 hashCode() 方法得到其 hashCode 值——每個 Java 對象都有 hashCode() 方法,都可通過該方法獲得它的 hashCode 值。得到這個對象的 hashCode 值之後,系統會根據該 hashCode 值來決定該元素的存儲位置。
我們可以看 HashMap 類的 put(K key , V value) 方法的源代碼:
(ps:JDK 源碼
在 JDK 安裝目錄下可以找到一個 src.zip 壓縮文件,該文件裡包含了 Java 基礎類庫的所有源文件。只要讀者有學習興趣,隨時可以打開這份壓縮文件來閱讀 Java 類庫的源代碼,這對提高讀者的編程能力是非常有幫助的。需要指出的是:src.zip 中包含的源代碼並沒有包含像上文中的中文注釋,這些注釋是筆者自己添加進去的。)
public V put(K key, V value)
{
// 如果 key 為 null,調用 putForNullKey 方法進行處理
if (key == null)
return putForNullKey(value);
// 根據 key 的 keyCode 計算 Hash 值
int hash = hash(key.hashCode());
// 搜索指定 hash 值在對應 table 中的索引
int i = indexFor(hash, table.length);
// 如果 i 索引處的 Entry 不為 null,通過循環不斷遍歷 e 元素的下一個元素
for (Entry<K,V> e = table[i]; e != null; e = e.next)
{
Object k;
// 找到指定 key 與需要放入的 key 相等(hash 值相同
// 通過 equals 比較放回 true)
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
{
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果 i 索引處的 Entry 為 null,表明此處還沒有 Entry
modCount++;
// 將 key、value 添加到 i 索引處
addEntry(hash, key, value, i);
return null;
}
上面程序中用到了一個重要的內部接口:Map.Entry,每個 Map.Entry 其實就是一個 key-value 對。從上面程序中可以看出:當系統決定存儲 HashMap 中的 key-value 對時,完全沒有考慮 Entry 中的 value,僅僅只是根據 key 來計算並決定每個 Entry 的存儲位置。這也說明了前面的結論:我們完全可以把 Map 集合中的 value 當成 key 的附屬,當系統決定了 key 的存儲位置之後,value 隨之保存在那裡即可。
上面方法提供了一個根據 hashCode() 返回值來計算 Hash 碼的方法:hash(),這個方法是一個純粹的數學計算,其方法如下:
static int hash(int h)
{
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
對於任意給定的對象,只要它的 hashCode() 返回值相同,那麼程序調用 hash(int h) 方法所計算得到的 Hash 碼值總是相同的。接下來程序會調用 indexFor(int h, int length) 方法來計算該對象應該保存在 table 數組的哪個索引處。indexFor(int h, int length) 方法的代碼如下:
static int indexFor(int h, int length)
{
return h & (length-1);
}
這個方法非常巧妙,它總是通過 h &(table.length -1) 來得到該對象的保存位置——而 HashMap 底層數組的長度總是 2 的 n 次方,這一點可參看後面關於 HashMap 構造器的介紹。
當 length 總是 2 的倍數時,h & (length-1)將是一個非常巧妙的設計:假設 h=5,length=16, 那麼 h & length - 1 將得到 5;如果 h=6,length=16, 那麼 h & length - 1 將得到 6 ……如果 h=15,length=16, 那麼 h & length - 1 將得到 15;但是當 h=16 時 , length=16 時,那麼 h & length - 1 將得到 0 了;當 h=17 時 , length=16 時,那麼 h & length - 1 將得到 1 了……這樣保證計算得到的索引值總是位於 table 數組的索引之內。
根據上面 put 方法的源代碼可以看出,當程序試圖將一個 key-value 對放入 HashMap 中時,程序首先根據該 key 的 hashCode() 返回值決定該 Entry 的存儲位置:如果兩個 Entry 的 key 的 hashCode() 返回值相同,那它們的存儲位置相同。如果這兩個 Entry 的 key 通過 equals 比較返回 true,新添加 Entry 的 value 將覆蓋集合中原有 Entry 的 value,但 key 不會覆蓋。如果這兩個 Entry 的 key 通過 equals 比較返回 false,新添加的 Entry 將與集合中原有 Entry 形成 Entry 鏈,而且新添加的 Entry 位於 Entry 鏈的頭部——具體說明繼續看 addEntry() 方法的說明。
當向 HashMap 中添加 key-value 對,由其 key 的 hashCode() 返回值決定該 key-value 對(就是 Entry 對象)的存儲位置。當兩個 Entry 對象的 key 的 hashCode() 返回值相同時,將由 key 通過 eqauls() 比較值決定是采用覆蓋行為(返回 true),還是產生 Entry 鏈(返回 false)。
上面程序中還調用了 addEntry(hash, key, value, i); 代碼,其中 addEntry 是 HashMap 提供的一個包訪問權限的方法,該方法僅用於添加一個 key-value 對。下面是該方法的代碼:
void addEntry(int hash, K key, V value, int bucketIndex)
{
// 獲取指定 bucketIndex 索引處的 Entry
Entry<K,V> e = table[bucketIndex]; // ①
// 將新創建的 Entry 放入 bucketIndex 索引處,並讓新的 Entry 指向原來的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 對的數量超過了極限
if (size++ >= threshold)
// 把 table 對象的長度擴充到 2 倍。
resize(2 * table.length); // ②
}
上面方法的代碼很簡單,但其中包含了一個非常優雅的設計:系統總是將新添加的 Entry 對象放入 table 數組的 bucketIndex 索引處——如果 bucketIndex 索引處已經有了一個 Entry 對象,那新添加的 Entry 對象指向原有的 Entry 對象(產生一個 Entry 鏈),如果 bucketIndex 索引處沒有 Entry 對象,也就是上面程序①號代碼的 e 變量是 null,也就是新放入的 Entry 對象指向 null,也就是沒有產生 Entry 鏈。
根據上面代碼可以看出,在同一個 bucket 存儲 Entry 鏈的情況下,新放入的 Entry 總是位於 bucket 中,而最早放入該 bucket 中的 Entry 則位於這個 Entry 鏈的最末端。
上面程序中還有這樣兩個變量:
從上面程序中②號代碼可以看出,當 size++ >= threshold 時,HashMap 會自動調用 resize 方法擴充 HashMap 的容量。每擴充一次,HashMap 的容量就增大一倍。
上面程序中使用的 table 其實就是一個普通數組,每個數組都有一個固定的長度,這個數組的長度就是 HashMap 的容量。HashMap 包含如下幾個構造器:
當創建一個 HashMap 時,系統會自動創建一個 table 數組來保存 HashMap 中的 Entry,下面是 HashMap 中一個構造器的代碼:
// 以指定初始化容量、負載因子創建 HashMap
public HashMap(int initialCapacity, float loadFactor)
{
// 初始容量不能為負數
if (initialCapacity < 0)
throw new IllegalArgumentException(
"Illegal initial capacity: " +
initialCapacity);
// 如果初始容量大於最大容量,讓出示容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 負載因子必須大於 0 的數值
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException(
loadFactor);
// 計算出大於 initialCapacity 的最小的 2 的 n 次方值。
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
// 設置容量極限等於容量 * 負載因子
threshold = (int)(capacity * loadFactor);
// 初始化 table 數組
table = new Entry[capacity]; // ①
init();
}
上面代碼中粗體字代碼包含了一個簡潔的代碼實現:找出大於 initialCapacity 的、最小的 2 的 n 次方值,並將其作為 HashMap 的實際容量(由 capacity 變量保存)。例如給定 initialCapacity 為 10,那麼該 HashMap 的實際容量就是 16。
創建 HashMap 時指定的 initialCapacity 並不等於 HashMap 的實際容量,通常來說,HashMap 的實際容量總比 initialCapacity 大一些,除非我們指定的 initialCapacity 參數值恰好是 2 的 n 次方。當然,掌握了 HashMap 容量分配的知識之後,應該在創建 HashMap 時將 initialCapacity 參數值指定為 2 的 n 次方,這樣可以減少系統的計算開銷。
程序①號代碼處可以看到:table 的實質就是一個數組,一個長度為 capacity 的數組。
對於 HashMap 及其子類而言,它們采用 Hash 算法來決定集合中元素的存儲位置。當系統開始初始化 HashMap 時,系統會創建一個長度為 capacity 的 Entry 數組,這個數組裡可以存儲元素的位置被稱為“桶(bucket)”,每個 bucket 都有其指定索引,系統可以根據其索引快速訪問該 bucket 裡存儲的元素。
無論何時,HashMap 的每個“桶”只存儲一個元素(也就是一個 Entry),由於 Entry 對象可以包含一個引用變量(就是 Entry 構造器的的最後一個參數)用於指向下一個 Entry,因此可能出現的情況是:HashMap 的 bucket 中只有一個 Entry,但這個 Entry 指向另一個 Entry ——這就形成了一個 Entry 鏈。如圖 1 所示:
圖 1. HashMap 的存儲示意
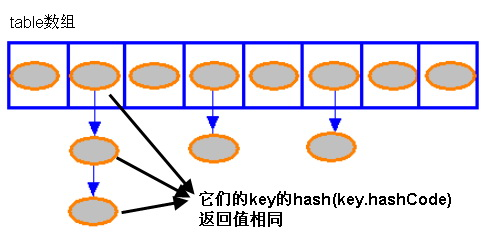
當 HashMap 的每個 bucket 裡存儲的 Entry 只是單個 Entry ——也就是沒有通過指針產生 Entry 鏈時,此時的 HashMap 具有最好的性能:當程序通過 key 取出對應 value 時,系統只要先計算出該 key 的 hashCode() 返回值,在根據該 hashCode 返回值找出該 key 在 table 數組中的索引,然後取出該索引處的 Entry,最後返回該 key 對應的 value 即可。看 HashMap 類的 get(K key) 方法代碼:
public V get(Object key)
{
// 如果 key 是 null,調用 getForNullKey 取出對應的 value
if (key == null)
return getForNullKey();
// 根據該 key 的 hashCode 值計算它的 hash 碼
int hash = hash(key.hashCode());
// 直接取出 table 數組中指定索引處的值,
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
// 搜索該 Entry 鏈的下一個 Entr
e = e.next) // ①
{
Object k;
// 如果該 Entry 的 key 與被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
}
從上面代碼中可以看出,如果 HashMap 的每個 bucket 裡只有一個 Entry 時,HashMap 可以根據索引、快速地取出該 bucket 裡的 Entry;在發生“Hash 沖突”的情況下,單個 bucket 裡存儲的不是一個 Entry,而是一個 Entry 鏈,系統只能必須按順序遍歷每個 Entry,直到找到想搜索的 Entry 為止——如果恰好要搜索的 Entry 位於該 Entry 鏈的最末端(該 Entry 是最早放入該 bucket 中),那系統必須循環到最後才能找到該元素。
歸納起來簡單地說,HashMap 在底層將 key-value 當成一個整體進行處理,這個整體就是一個 Entry 對象。HashMap 底層采用一個 Entry[] 數組來保存所有的 key-value 對,當需要存儲一個 Entry 對象時,會根據 Hash 算法來決定其存儲位置;當需要取出一個 Entry 時,也會根據 Hash 算法找到其存儲位置,直接取出該 Entry。由此可見:HashMap 之所以能快速存、取它所包含的 Entry,完全類似於現實生活中母親從小教我們的:不同的東西要放在不同的位置,需要時才能快速找到它。
當創建 HashMap 時,有一個默認的負載因子(load factor),其默認值為 0.75,這是時間和空間成本上一種折衷:增大負載因子可以減少 Hash 表(就是那個 Entry 數組)所占用的內存空間,但會增加查詢數據的時間開銷,而查詢是最頻繁的的操作(HashMap 的 get() 與 put() 方法都要用到查詢);減小負載因子會提高數據查詢的性能,但會增加 Hash 表所占用的內存空間。
掌握了上面知識之後,我們可以在創建 HashMap 時根據實際需要適當地調整 load factor 的值;如果程序比較關心空間開銷、內存比較緊張,可以適當地增加負載因子;如果程序比較關心時間開銷,內存比較寬裕則可以適當的減少負載因子。通常情況下,程序員無需改變負載因子的值。
如果開始就知道 HashMap 會保存多個 key-value 對,可以在創建時就使用較大的初始化容量,如果 HashMap 中 Entry 的數量一直不會超過極限容量(capacity * load factor),HashMap 就無需調用 resize() 方法重新分配 table 數組,從而保證較好的性能。當然,開始就將初始容量設置太高可能會浪費空間(系統需要創建一個長度為 capacity 的 Entry 數組),因此創建 HashMap 時初始化容量設置也需要小心對待。
對於 HashSet 而言,它是基於 HashMap 實現的,HashSet 底層采用 HashMap 來保存所有元素,因此 HashSet 的實現比較簡單,查看 HashSet 的源代碼,可以看到如下代碼:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
// 使用 HashMap 的 key 保存 HashSet 中所有元素
private transient HashMap<E,Object> map;
// 定義一個虛擬的 Object 對象作為 HashMap 的 value
private static final Object PRESENT = new Object();
...
// 初始化 HashSet,底層會初始化一個 HashMap
public HashSet()
{
map = new HashMap<E,Object>();
}
// 以指定的 initialCapacity、loadFactor 創建 HashSet
// 其實就是以相應的參數創建 HashMap
public HashSet(int initialCapacity, float loadFactor)
{
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity)
{
map = new HashMap<E,Object>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy)
{
map = new LinkedHashMap<E,Object>(initialCapacity
, loadFactor);
}
// 調用 map 的 keySet 來返回所有的 key
public Iterator<E> iterator()
{
return map.keySet().iterator();
}
// 調用 HashMap 的 size() 方法返回 Entry 的數量,就得到該 Set 裡元素的個數
public int size()
{
return map.size();
}
// 調用 HashMap 的 isEmpty() 判斷該 HashSet 是否為空,
// 當 HashMap 為空時,對應的 HashSet 也為空
public boolean isEmpty()
{
return map.isEmpty();
}
// 調用 HashMap 的 containsKey 判斷是否包含指定 key
//HashSet 的所有元素就是通過 HashMap 的 key 來保存的
public boolean contains(Object o)
{
return map.containsKey(o);
}
// 將指定元素放入 HashSet 中,也就是將該元素作為 key 放入 HashMap
public boolean add(E e)
{
return map.put(e, PRESENT) == null;
}
// 調用 HashMap 的 remove 方法刪除指定 Entry,也就刪除了 HashSet 中對應的元素
public boolean remove(Object o)
{
return map.remove(o)==PRESENT;
}
// 調用 Map 的 clear 方法清空所有 Entry,也就清空了 HashSet 中所有元素
public void clear()
{
map.clear();
}
...
}
由上面源程序可以看出,HashSet 的實現其實非常簡單,它只是封裝了一個 HashMap 對象來存儲所有的集合元素,所有放入 HashSet 中的集合元素實際上由 HashMap 的 key 來保存,而 HashMap 的 value 則存儲了一個 PRESENT,它是一個靜態的 Object 對象。
HashSet 的絕大部分方法都是通過調用 HashMap 的方法來實現的,因此 HashSet 和 HashMap 兩個集合在實現本質上是相同的。
由於 HashSet 的 add() 方法添加集合元素時實際上轉變為調用 HashMap 的 put() 方法來添加 key-value 對,當新放入 HashMap 的 Entry 中 key 與集合中原有 Entry 的 key 相同(hashCode() 返回值相等,通過 equals 比較也返回 true),新添加的 Entry 的 value 將覆蓋原來 Entry 的 value,但 key 不會有任何改變,因此如果向 HashSet 中添加一個已經存在的元素,新添加的集合元素(底層由 HashMap 的 key 保存)不會覆蓋已有的集合元素。
掌握上面理論知識之後,接下來看一個示例程序,測試一下自己是否真正掌握了 HashMap 和 HashSet 集合的功能。
class Name
{
private String first;
private String last;
public Name(String first, String last)
{
this.first = first;
this.last = last;
}
public boolean equals(Object o)
{
if (this == o)
{
return true;
}
if (o.getClass() == Name.class)
{
Name n = (Name)o;
return n.first.equals(first)
&& n.last.equals(last);
}
return false;
}
}
public class HashSetTest
{
public static void main(String[] args)
{
Set<Name> s = new HashSet<Name>();
s.add(new Name("abc", "123"));
System.out.println(
s.contains(new Name("abc", "123")));
}
}
上面程序中向 HashSet 裡添加了一個 new Name("abc", "123") 對象之後,立即通過程序判斷該 HashSet 是否包含一個 new Name("abc", "123") 對象。粗看上去,很容易以為該程序會輸出 true。
實際運行上面程序將看到程序輸出 false,這是因為 HashSet 判斷兩個對象相等的標准除了要求通過 equals() 方法比較返回 true 之外,還要求兩個對象的 hashCode() 返回值相等。而上面程序沒有重寫 Name 類的 hashCode() 方法,兩個 Name 對象的 hashCode() 返回值並不相同,因此 HashSet 會把它們當成 2 個對象處理,因此程序返回 false。
由此可見,當我們試圖把某個類的對象當成 HashMap 的 key,或試圖將這個類的對象放入 HashSet 中保存時,重寫該類的 equals(Object obj) 方法和 hashCode() 方法很重要,而且這兩個方法的返回值必須保持一致:當該類的兩個的 hashCode() 返回值相同時,它們通過 equals() 方法比較也應該返回 true。通常來說,所有參與計算 hashCode() 返回值的關鍵屬性,都應該用於作為 equals() 比較的標准。
如下程序就正確重寫了 Name 類的 hashCode() 和 equals() 方法,程序如下:
class Name
{
private String first;
private String last;
public Name(String first, String last)
{
this.first = first;
this.last = last;
}
// 根據 first 判斷兩個 Name 是否相等
public boolean equals(Object o)
{
if (this == o)
{
return true;
}
if (o.getClass() == Name.class)
{
Name n = (Name)o;
return n.first.equals(first);
}
return false;
}
// 根據 first 計算 Name 對象的 hashCode() 返回值
public int hashCode()
{
return first.hashCode();
}
public String toString()
{
return "Name[first=" + first + ", last=" + last + "]";
}
}
public class HashSetTest2
{
public static void main(String[] args)
{
HashSet<Name> set = new HashSet<Name>();
set.add(new Name("abc" , "123"));
set.add(new Name("abc" , "456"));
System.out.println(set);
}
}
上面程序中提供了一個 Name 類,該 Name 類重寫了 equals() 和 toString() 兩個方法,這兩個方法都是根據 Name 類的 first 實例變量來判斷的,當兩個 Name 對象的 first 實例變量相等時,這兩個 Name 對象的 hashCode() 返回值也相同,通過 equals() 比較也會返回 true。
程序主方法先將第一個 Name 對象添加到 HashSet 中,該 Name 對象的 first 實例變量值為"abc",接著程序再次試圖將一個 first 為"abc"的 Name 對象添加到 HashSet 中,很明顯,此時沒法將新的 Name 對象添加到該 HashSet 中,因為此處試圖添加的 Name 對象的 first 也是" abc",HashSet 會判斷此處新增的 Name 對象與原有的 Name 對象相同,因此無法添加進入,程序在①號代碼處輸出 set 集合時將看到該集合裡只包含一個 Name 對象,就是第一個、last 為"123"的 Name 對象。
文章鏈接:
https://www.ibm.com/developerworks/cn/java/j-lo-hash/