docker的跨主機解決方案weave----遇到的坑(1)
在weave的1.2版本之後,考慮到原先sleeve模式的網絡性能很差,增加了fastdp的模式,該模式是weave啟動時默認模式,在fastdp模式中使用了kernel中的openvswitch.ko模塊,在做報文封裝時使用內核中的vxlan。最近遇到一個問題,在使用qemu-kvm虛擬的雲主機上,如果安裝的是centos7.0,並且內核版本為kernel-3.10.123,會造成virtio_net虛擬網卡無法發送數據包,導致整個虛擬機的網絡中斷的問題。
造成網絡斷開的原因是因為觸發了內核的一個bug,內核bug的鏈接地址為:https://git.kernel.org/cgit/linux/kernel/git/stable/linux-stable.git/commit/?id=8a0cafc9a8131cc545dc9924aed38f7176ee4ad7
- diff --git a/net/ipv4/ip_output.c b/net/ipv4/ip_output.c
- index dd637fc..05686c4 100644
- --- a/net/ipv4/ip_output.c
- +++ b/net/ipv4/ip_output.c
- @@ -843,7 +843,8 @@ static int __ip_append_data(struct sock *sk,
- cork->length += length;
- if (((length > mtu) || (skb && skb_is_gso(skb))) &&
- (sk->sk_protocol == IPPROTO_UDP) &&
- - (rt->dst.dev->features & NETIF_F_UFO) && !rt->dst.header_len) {
- + (rt->dst.dev->features & NETIF_F_UFO) && !rt->dst.header_len &&
- + (sk->sk_type == SOCK_DGRAM)) {
- err = ip_ufo_append_data(sk, queue, getfrag, from, length,
- hh_len, fragheaderlen, transhdrlen,
- maxfraglen, flags);
- diff --git a/net/ipv6/ip6_output.c b/net/ipv6/ip6_output.c
- index 12f7ef0..d7907ec 100644
- --- a/net/ipv6/ip6_output.c
- +++ b/net/ipv6/ip6_output.c
- @@ -1294,7 +1294,8 @@ emsgsize:
- if (((length > mtu) ||
- (skb && skb_is_gso(skb))) &&
- (sk->sk_protocol == IPPROTO_UDP) &&
- - (rt->dst.dev->features & NETIF_F_UFO)) {
- + (rt->dst.dev->features & NETIF_F_UFO) &&
- + (sk->sk_type == SOCK_DGRAM)) {
- err = ip6_ufo_append_data(sk, getfrag, from, length,
- hh_len, fragheaderlen,
- transhdrlen, mtu, flags, rt);
有兩種方式可以解決該問題:1)升級大於等於3.13的內核 2)關閉虛擬機網卡的ufo特性
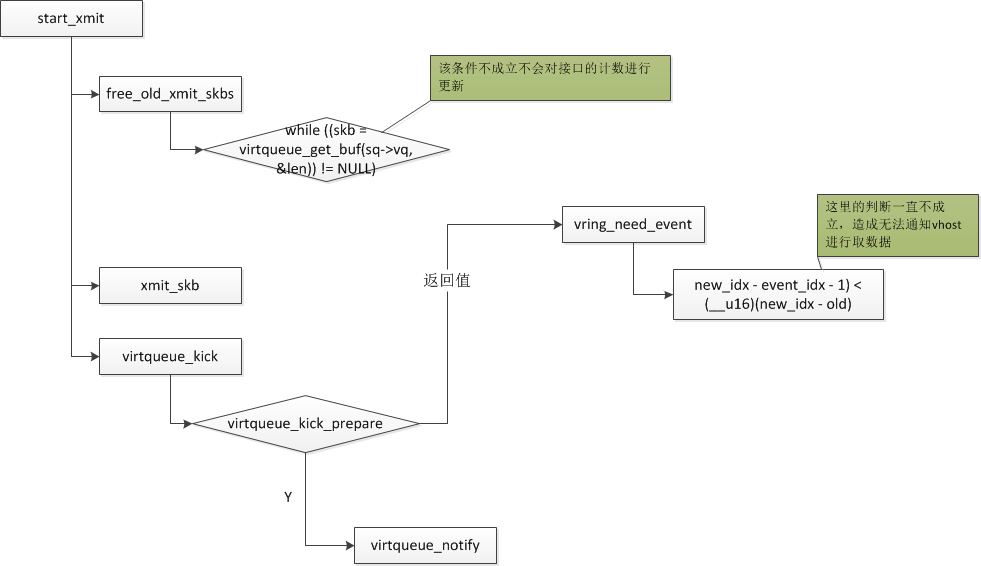
Weave會發送一個60000字節的UDP數據包進行PMTU的探測,而且Weave發送使用的是raw socket,因此觸發了內核bug,導致了virtio_net使用的內存被污染,表現的現象就是無法通知到宿主機上vhost取數據,在接口上看到發送報文的計數始終不會增加。該問題不是只有weave才能觸發,使用普通的應用程序只要在建立socket時,使用是raw socket,並且在發送數據時,發送的數據大於接口的MTU值,接口的UFO功能是打開的,都極有可能觸發該問題。
centos7.1的kernel-3.10.229內核已經修復了該問題。下圖是WEAVE使用fastdp模式的數據流程圖:
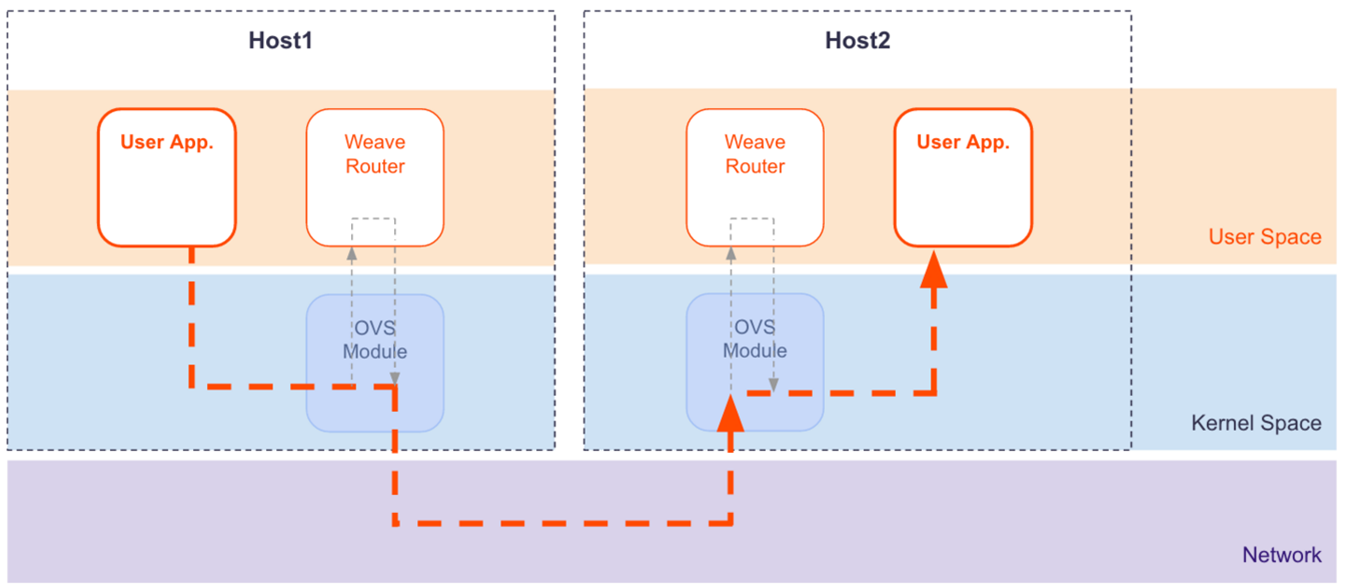
底層virtio_net中的處理流程: