文件種類是豐富多彩的,XML作為眾多文件類型的一種,經常被用於數據存儲和傳輸。所以XML在現今應用程序中是非常流行的。本文主要講Java解析和生成XML。用於不同平台、不同設備間的數據共享通信。
XML文件的表現:以“.xml”為文件擴展名的文件;
存儲結構:樹形結構;
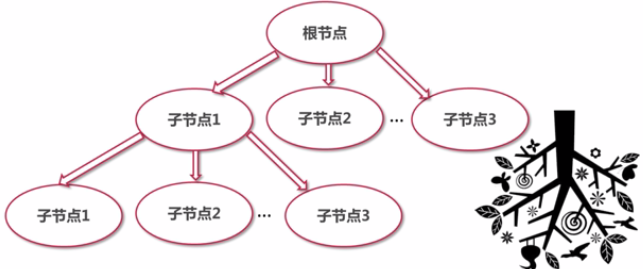
節點名稱區分大小寫。
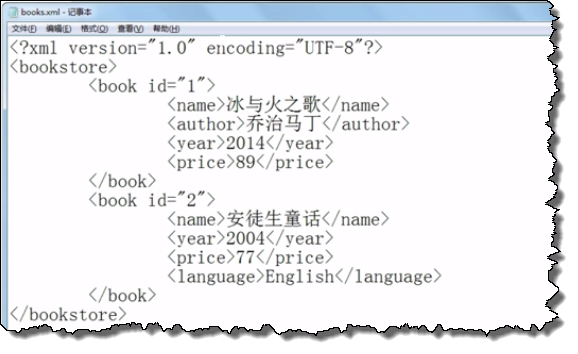
1、<book id="1"></book> id為屬性, <book><id>1</id></book> id為節點
2、xml文件開頭要加上版本信息和編碼方式<?xml version="1.0" encoding="UTF-8"?>
比如:
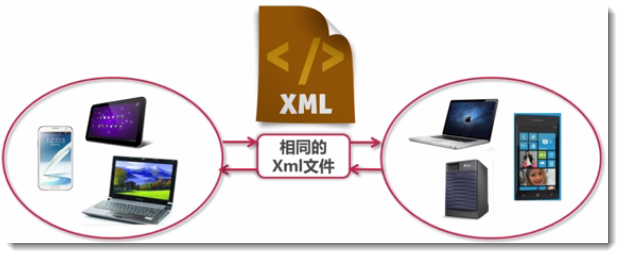
思考1:不同應用程序之間的通信?

思考2:不同平台間的通信?

思考3:不同平台間的數據共享?

答案就是我們要學習的XML文件。我們可以使用相同的xml把不同的文件聯系起來
❤ 在Java程序中如何獲取XML文件的內容

解析的目的:獲取節點名、節點值、屬性名、屬性值;
四種解析方式:DOM、SAX、DOM4J、JDOM
DOM、SAX :java 官方方式,不需要下載jar包
DOM4J、JDOM :第三方,需要網上下載jar包
示例:解析XML文件,目標是解析XML文件後,Java程序能夠得到xml文件的所有數據
思考:如何在Java程序中保留xml數據的結構?
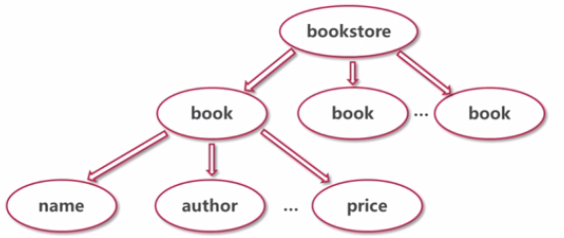
如何保留節點之間的層級關系?
注意常用的節點類型:

下面介紹DOM方式解析XML:
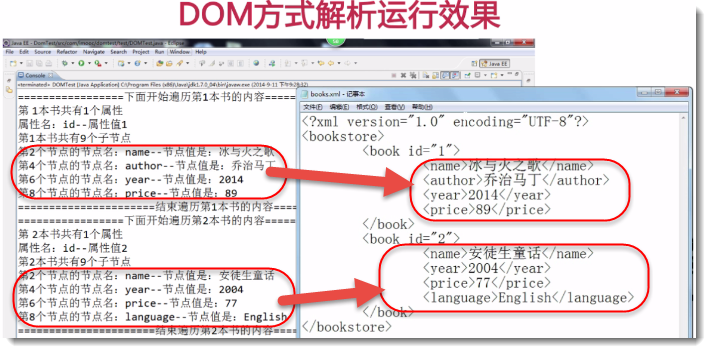
功能說明:


代碼示例:
1 package com.study.domtest;
2
3 import java.io.IOException;
4
5 import javax.xml.parsers.DocumentBuilder;
6 import javax.xml.parsers.DocumentBuilderFactory;
7 import javax.xml.parsers.ParserConfigurationException;
8
9 import org.w3c.dom.Document;
10 import org.w3c.dom.NamedNodeMap;
11 import org.w3c.dom.Node;
12 import org.w3c.dom.NodeList;
13 import org.xml.sax.SAXException;
14
15 /**
16 * DOM方式解析xml
17 */
18 public class DOMTest {
19
20 public static void main(String[] args) {
21 //1、創建一個DocumentBuilderFactory的對象
22 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
23 //2、創建一個DocumentBuilder的對象
24 try {
25 //創建DocumentBuilder對象
26 DocumentBuilder db = dbf.newDocumentBuilder();
27 //3、通過DocumentBuilder對象的parser方法加載books.xml文件到當前項目下
28 /*注意導入Document對象時,要導入org.w3c.dom.Document包下的*/
29 Document document = db.parse("books.xml");//傳入文件名可以是相對路徑也可以是絕對路徑
30 //獲取所有book節點的集合
31 NodeList bookList = document.getElementsByTagName("book");
32 //通過nodelist的getLength()方法可以獲取bookList的長度
33 System.out.println("一共有" + bookList.getLength() + "本書");
34 //遍歷每一個book節點
35 for (int i = 0; i < bookList.getLength(); i++) {
36 System.out.println("=================下面開始遍歷第" + (i + 1) + "本書的內容=================");
37 //❤未知節點屬性的個數和屬性名時:
38 //通過 item(i)方法 獲取一個book節點,nodelist的索引值從0開始
39 Node book = bookList.item(i);
40 //獲取book節點的所有屬性集合
41 NamedNodeMap attrs = book.getAttributes();
42 System.out.println("第 " + (i + 1) + "本書共有" + attrs.getLength() + "個屬性");
43 //遍歷book的屬性
44 for (int j = 0; j < attrs.getLength(); j++) {
45 //通過item(index)方法獲取book節點的某一個屬性
46 Node attr = attrs.item(j);
47 //獲取屬性名
48 System.out.print("屬性名:" + attr.getNodeName());
49 //獲取屬性值
50 System.out.println("--屬性值" + attr.getNodeValue());
51 }
52 //❤已知book節點有且只有1個id屬性:
53 /*
54 //前提:已經知道book節點有且只能有1個id屬性
55 //將book節點進行強制類型轉換,轉換成Element類型
56 Element book1 = (Element) bookList.item(i);
57 //通過getAttribute("id")方法獲取屬性值
58 String attrValue = book1.getAttribute("id");
59 System.out.println("id屬性的屬性值為" + attrValue);
60 */
61
62 //解析book節點的子節點
63 NodeList childNodes = book.getChildNodes();
64 //遍歷childNodes獲取每個節點的節點名和節點值
65 System.out.println("第" + (i+1) + "本書共有" + childNodes.getLength() + "個子節點");
66 for (int k = 0; k < childNodes.getLength(); k++) {
67 //區分出text類型的node以及element類型的node
68 if(childNodes.item(k).getNodeType() == Node.ELEMENT_NODE){
69 //獲取了element類型節點的節點名
70 System.out.print("第" + (k + 1) + "個節點的節點名:" + childNodes.item(k).getNodeName());
71 //獲取了element類型節點的節點值
72 System.out.println("--節點值是:" + childNodes.item(k).getFirstChild().getNodeValue());
73 // System.out.println("--節點值是:" + childNodes.item(k).getTextContent());
74 }
75 }
76 System.out.println("======================結束遍歷第" + (i + 1) + "本書的內容=================");
77 }
78
79 } catch (ParserConfigurationException e) {
80 e.printStackTrace();
81 } catch (SAXException e) {
82 e.printStackTrace();
83 } catch (IOException e) {
84 e.printStackTrace();
85 }
86 }
87
88 }
SAX是SIMPLE API FOR XML的縮寫,與DOM比較而言,SAX是一種輕量型的方法。
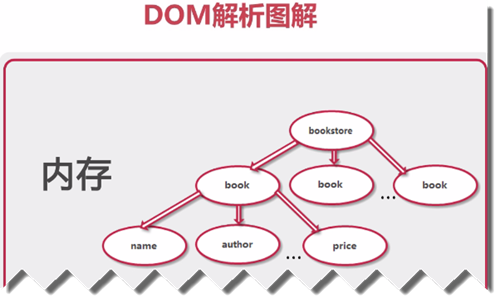
Dom解析會將整個xml文件加載到內存中,然後再逐個解析
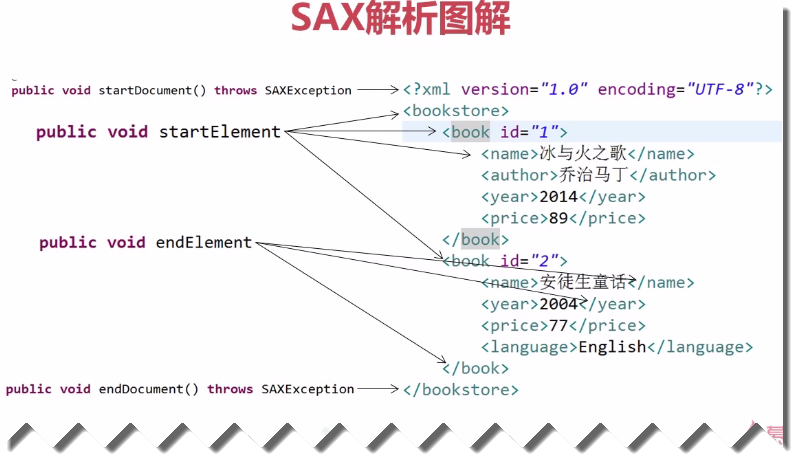
Sax解析是通過Handler處理類逐個依次解析每個節點
在處理DOM的時候,我們需要讀入整個的XML文檔,然後在內存中創建DOM樹,生成DOM樹上的每個NODE對象。當文檔比較小的時候,這不會造成什麼問題,但是一旦文檔大起來,處理DOM就會變得相當費時費力。特別是其對於內存的需求,也將是成倍的增長,以至於在某些應用中使用DOM是一件很不劃算的事。這時候,一個較好的替代解決方法就是SAX。 SAX在概念上與DOM完全不同。首先,不同於DOM的文檔驅動,它是事件驅動的,也就是說,它並不需要讀入整個文檔,而文檔的讀入過程也就是SAX的解析過程。所謂事件驅動,是指一種基於回調(callback)機制的程序運行方法。在XMLReader接受XML文檔,在讀入XML文檔的過程中就進行解析,也就是說讀入文檔的過程和解析的過程是同時進行的,這和DOM區別很大。
❤


代碼示例:Book實體類
1 package com.study.saxtest.entity;
2
3 /**
4 * 用Book實體類代表XML文件中的"<book>...</book>"中整個元素
5 * 在遇到<book>標簽,證明我們要存儲新的book時需要創建Book對象
6 */
7 public class Book {
8 private String id;
9 private String name;
10 private String author;
11 private String year;
12 private String price;
13 private String language;
14 public String getId() {
15 return id;
16 }
17 public void setId(String id) {
18 this.id = id;
19 }
20 public String getName() {
21 return name;
22 }
23 public void setName(String name) {
24 this.name = name;
25 }
26 public String getAuthor() {
27 return author;
28 }
29 public void setAuthor(String author) {
30 this.author = author;
31 }
32 public String getYear() {
33 return year;
34 }
35 public void setYear(String year) {
36 this.year = year;
37 }
38 public String getPrice() {
39 return price;
40 }
41 public void setPrice(String price) {
42 this.price = price;
43 }
44 public String getLanguage() {
45 return language;
46 }
47 public void setLanguage(String language) {
48 this.language = language;
49 }
50 }
SAXParserHandler類:
1 package com.study.saxtest.handler;
2
3 import java.util.ArrayList;
4
5 import org.xml.sax.Attributes;
6 import org.xml.sax.SAXException;
7 import org.xml.sax.helpers.DefaultHandler;
8
9 import com.study.saxtest.entity.Book;
10
11 public class SAXParserHandler extends DefaultHandler{
12 /*注意DefaultHandler是org.xml.sax.helpers包下的*/
13
14 int bookIndex = 0;//設置全局變量,用來記錄是第幾本書
15
16 String value = null;
17 Book book = null;
18 private ArrayList<Book> bookList = new ArrayList<Book>();//保存book對象
19
20 public ArrayList<Book> getBookList() {
21 return bookList;
22 }
23
24 /**
25 * 用來標識解析開始
26 */
27 @Override
28 public void startDocument() throws SAXException {
29 super.startDocument();
30 System.out.println("SAX解析開始");
31
32 }
33
34 /**
35 * 用來標識解析結束
36 */
37 @Override
38 public void endDocument() throws SAXException {
39 super.endDocument();
40 System.out.println("SAX解析結束");
41 }
42
43 /**
44 * 用來遍歷xml文件的開始標簽
45 * 解析xml元素
46 */
47 @Override
48 public void startElement(String uri, String localName, String qName,Attributes attributes) throws SAXException {
49 //調用DefaultHandler類的startElement方法
50 super.startElement(uri, localName, qName, attributes);
51 if (qName.equals("book")) {
52 bookIndex++;
53 //創建一個book對象
54 /*Book*/ book = new Book();
55 //開始解析book元素的屬性
56 System.out.println("======================開始遍歷第"+bookIndex+"本書的內容=================");
57 /* //❤已知節點的屬性名時:比如已知id屬性,根據屬性名稱獲取屬性值
58 String value = attributes.getValue("id");
59 System.out.print("book的屬性值是:"+value);*/
60 //❤未知節點的屬性名時,獲取屬性名和屬性值
61 int num=attributes.getLength();
62 for(int i=0;i<num;i++){
63 System.out.print("book元素的第"+(i+1)+"個屬性名是:"+attributes.getQName(i));
64 System.out.println("---屬性值是:"+attributes.getValue(i));
65 if (attributes.getQName(i).equals("id")) {//往book對象中塞值
66 book.setId(attributes.getValue(i));
67 }
68 }
69 }else if (!qName.equals("book") && !qName.equals("bookstore")) {
70 System.out.print("節點名是:" + qName + "---");//此時qName獲取的是節點名(標簽)
71 }
72 }
73
74 /**
75 * 用來遍歷xml文件的結束標簽
76 */
77 @Override
78 public void endElement(String uri, String localName, String qName) throws SAXException {
79 //調用DefaultHandler類的endElement方法
80 super.endElement(uri, localName, qName);
81 //判斷是否針對一本書已經遍歷結束
82 if (qName.equals("book")) {
83 bookList.add(book);//在清空book對象之前先保存
84 book = null;//把book清空,方便解析下一個book節點
85 System.out.println("======================結束遍歷第"+bookIndex+"本書的內容=================");
86 }else if (qName.equals("name")) {
87 book.setName(value);
88 }
89 else if (qName.equals("author")) {
90 book.setAuthor(value);
91 }
92 else if (qName.equals("year")) {
93 book.setYear(value);
94 }
95 else if (qName.equals("price")) {
96 book.setPrice(value);
97 }
98 else if (qName.equals("language")) {
99 book.setLanguage(value);
100 }
101 }
102
103 /**
104 * 獲取文本
105 * 重寫charaters()方法時,
106 * String(byte[] bytes,int offset,int length)的構造方法進行數組的傳遞
107 * 去除解析時多余空格
108 */
109 @Override
110 public void characters(char[] ch, int start, int length)throws SAXException {
111 /**
112 * ch 代表節點中的所有內容,即每次遇到一個標簽調用characters方法時,數組ch實際都是整個XML文檔的內容
113 * 如何每次去調用characters方法時我們都可以獲取不同的節點屬性?這時就必須結合start(開始節點)和length(長度)
114 */
115 super.characters(ch, start, length);
116 /*String */value = new String(ch, start, length);//value獲取的是文本(開始和結束標簽之間的文本)
117 // System.out.println(value);//輸出時會多出兩個空格,是因為xml文件中空格與換行字符被看成為一個文本節點
118 if(!value.trim().equals("")){//如果value去掉空格後不是空字符串
119 System.out.println("節點值是:" + value);
120 }
121 }
122
123 /**
124 * qName獲取的是節點名(標簽)
125 * value獲取的是文本(開始和結束標簽之間的文本)
126 * 思考:qName和value分別在兩個方法中,如何將這兩個方法中的參數整合到一起?
127 * 分析:要在兩個方法中用同一個變量,就設置成全局變量,可以賦初值為null。
128 * 可以把characters()方法中的value作成一個全局變量
129 *
130 * 然後在endElement()方法中對book對象進行塞值。記得要把Book對象設置為全局變量,變量共享
131 */
132 }
測試類:SAXTest
1 package com.study.saxtest.test;
2
3 import java.io.IOException;
4
5 import javax.xml.parsers.ParserConfigurationException;
6 import javax.xml.parsers.SAXParser;
7 import javax.xml.parsers.SAXParserFactory;
8
9 import org.xml.sax.SAXException;
10
11 import com.study.saxtest.entity.Book;
12 import com.study.saxtest.handler.SAXParserHandler;
13
14 /**
15 * sax方式解析XML
16 */
17 public class SAXTest {
18
19 public static void main(String[] args) {
20 //1.獲取一個SAXParserFactory的實例對象
21 SAXParserFactory factory = SAXParserFactory.newInstance();
22 //2.通過factory的newSAXParser()方法獲取一個SAXParser類的對象。
23 try {
24 SAXParser parser = factory.newSAXParser();
25 //創建SAXParserHandler對象
26 SAXParserHandler handler = new SAXParserHandler();
27 parser.parse("books.xml", handler);
28 System.out.println("~~~~~共有"+handler.getBookList().size()+"本書");
29 for (Book book : handler.getBookList()) {
30 System.out.println(book.getId());
31 System.out.println(book.getName());
32 System.out.println(book.getAuthor());
33 System.out.println(book.getYear());
34 System.out.println(book.getPrice());
35 System.out.println(book.getLanguage());
36 System.out.println("----finish----");
37 }
38 } catch (ParserConfigurationException e) {
39 e.printStackTrace();
40 } catch (SAXException e) {
41 e.printStackTrace();
42 } catch (IOException e) {
43 e.printStackTrace();
44 }
45 }
46
47 }
運行結果:

# JDOM 方式解析 XML
JDOM 開始解析前的准備工作:
JDOM是第三方提供的解析XML方法,需要jdom-2.0.5.jar包
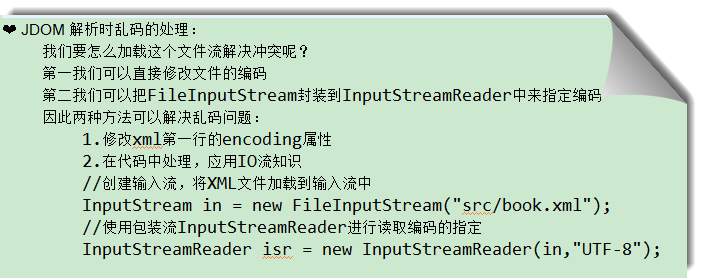
示例代碼:
1 package com.study.jdomtest1.test;
2
3 import java.io.FileInputStream;
4 import java.io.FileNotFoundException;
5 import java.io.IOException;
6 import java.io.InputStream;
7 import java.io.InputStreamReader;
8 import java.util.ArrayList;
9 import java.util.List;
10
11 import org.jdom2.Attribute;
12 import org.jdom2.Document;
13 import org.jdom2.Element;
14 import org.jdom2.JDOMException;
15 import org.jdom2.input.SAXBuilder;
16
17 import com.study.jdomtest1.entity.Book;
18
19 /**
20 * JDOM 解析XML
21 */
22 public class JDOMTest {
23 private static ArrayList<Book> booksList = new ArrayList<Book>();
24
25 public static void main(String[] args) {
26 // 進行對books.xml文件的JDOM解析
27 //❤准備工作
28 // 1.創建一個SAXBuilder的對象
29 SAXBuilder saxBuilder = new SAXBuilder();//注意SAXBuilder是org.jdom2.input包下的
30 InputStream in;
31 try {
32 // 2.創建一個輸入流,將xml文件加載到輸入流中
33 in=new FileInputStream("books.xml");//如果將xml文件放在src/res包下,此時應該輸入“src/res/books.xml”
34 InputStreamReader isr = new InputStreamReader(in, "UTF-8");//使用包裝流InputStreamReader進行讀取編碼的指定,防止亂碼
35 // 3.通過saxBuilder的build方法,將輸入流加載到saxBuilder中
36 Document document = saxBuilder.build(isr);
37 // 4.通過document對象獲取xml文件的根節點
38 Element rootElement = document.getRootElement();
39 // 5.獲取根節點下的子節點的List集合
40 List<Element> bookList = rootElement.getChildren();
41 //❤ 繼續解析,采用for循環對bookList進行遍歷
42 for (Element book : bookList) {
43 Book bookEntity = new Book();
44 System.out.println("======開始解析第" + (bookList.indexOf(book) + 1) + "書======");//indexOf()返回的是index的位置,是從0開始
45 // 解析book的屬性集合
46 List<Attribute> attrList = book.getAttributes();//適用於未知屬性情況下
47 /*//知道節點下屬性名稱時,獲取節點值
48 book.getAttributeValue("id");*/
49 // 遍歷attrList(針對不清楚book節點下屬性的名字及數量)
50 for (Attribute attr : attrList) {
51 /**注:JDom中,Attribute的getName和getValue方法獲取到的都是實際的名稱和值,
52 * 不會出現SAX和DOM中的空格和換行的情況*/
53 // 獲取屬性名
54 String attrName = attr.getName();
55 // 獲取屬性值
56 String attrValue = attr.getValue();
57 System.out.println("屬性名:" + attrName + "----屬性值:" + attrValue);
58 if (attrName.equals("id")) {
59 bookEntity.setId(attrValue);
60 }
61 }
62
63 //❤對book節點的子節點的節點名以及節點值的遍歷
64 List<Element> bookChilds = book.getChildren();
65 for (Element child : bookChilds) {
66 System.out.println("節點名:" + child.getName() + "----節點值:" + child.getValue());
67 if (child.getName().equals("name")) {
68 bookEntity.setName(child.getValue());
69 }
70 else if (child.getName().equals("author")) {
71 bookEntity.setAuthor(child.getValue());
72 }
73 else if (child.getName().equals("year")) {
74 bookEntity.setYear(child.getValue());
75 }
76 else if (child.getName().equals("price")) {
77 bookEntity.setPrice(child.getValue());
78 }
79 else if (child.getName().equals("language")) {
80 bookEntity.setLanguage(child.getValue());
81 }
82
83 }
84 System.out.println("======結束解析第" + (bookList.indexOf(book) + 1) + "書======");
85 booksList.add(bookEntity);
86 bookEntity = null;
87 //測試數據
88 System.out.println(booksList.size());
89 System.out.println(booksList.get(0).getId());
90 System.out.println(booksList.get(0).getName());
91
92 }
93 } catch (FileNotFoundException e) {
94 e.printStackTrace();
95 } catch (JDOMException e) {
96 e.printStackTrace();
97 } catch (IOException e) {
98 e.printStackTrace();
99 }
100 }
101
102 }
注意:
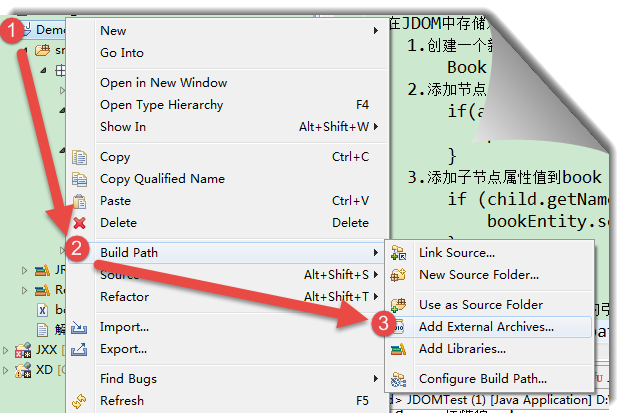
❤關於 JDOM 使用過程中 JAR 包的引用 :
方式1:通過右擊項目-->build path-->add external archives...-->然後選擇本地文件的jar包
這種方式並不能將jar包真正導入到項目源碼中,當把項目導出放在另外的機器上,這個jar包並不會隨著project一同被導出。
如圖:
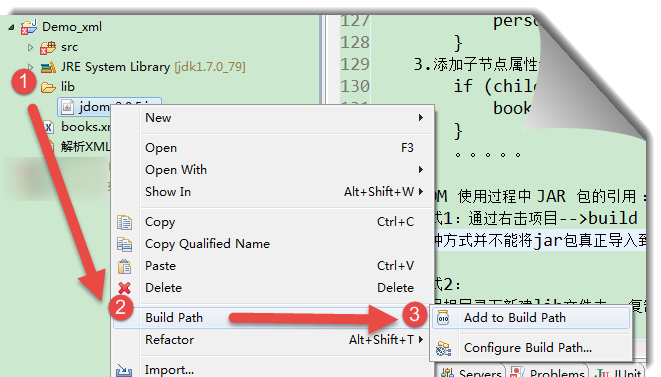
方式2:項目根目錄下新建lib文件夾——復制、粘帖jar包——右擊jar包選擇“build path構建路徑”——“add to build path添加至構建路徑”即可
如圖:
# DOM4J 方式解析 XML
DOM4J 是第三方提供的解析XML方法,需要dom4j-1.6.1.jar包
示例:
1 package com.study.dom4jtest;
2
3 import java.io.File;
4 import java.util.Iterator;
5 import java.util.List;
6
7 import org.dom4j.Attribute;
8 import org.dom4j.Document;
9 import org.dom4j.DocumentException;
10 import org.dom4j.Element;
11 import org.dom4j.io.SAXReader;
12
13 /**
14 * DOM4J 方式解析XML
15 */
16 public class DOM4JTest {
17
18 public static void main(String[] args) {
19 // 解析books.xml文件
20 // 創建SAXReader的對象reader
21 SAXReader reader = new SAXReader();
22 try {
23 // 通過reader對象的read方法加載books.xml文件,獲取docuemnt對象。
24 Document document = reader.read(new File("books.xml"));
25 // 通過document對象獲取根節點bookstore
26 Element bookStore = document.getRootElement();
27 // 通過element對象的elementIterator方法獲取迭代器
28 Iterator it = bookStore.elementIterator();
29 // 遍歷迭代器,獲取根節點中的信息(書籍)
30 while (it.hasNext()) {
31 System.out.println("=====開始遍歷某一本書=====");
32 Element book = (Element) it.next();
33 // 獲取book的屬性名以及 屬性值
34 List<Attribute> bookAttrs = book.attributes();
35 for (Attribute attr : bookAttrs) {
36 System.out.println("屬性名:" + attr.getName() + "--屬性值:" + attr.getValue());
37 }
38 //解析子節點的信息
39 Iterator itt = book.elementIterator();
40 while (itt.hasNext()) {
41 Element bookChild = (Element) itt.next();
42 System.out.println("節點名:" + bookChild.getName() + "--節點值:" + bookChild.getStringValue());
43 }
44 System.out.println("=====結束遍歷某一本書=====");
45 }
46
47 } catch (DocumentException e) {
48 e.printStackTrace();
49 }
50 }
51
52 }
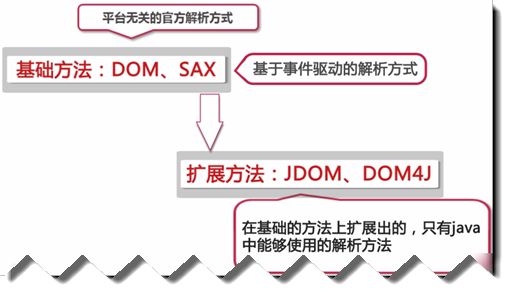
基礎方法:DOM(平台無關的官方解析方式)、SAX(基於事件驅動的解析方式)
擴展方法:JDOM、DOM4J(在基礎的方法上擴展出的,只有在java中能夠使用的解析方法)



##解析速度的分析
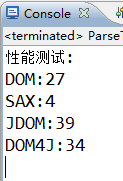
XML四種解析方式性能測試:
SAX>DOM>DOM4J>JDOM
JUnit是Java提供的一種進行單元測試的自動化工具。測試方法可以寫在任意類中的任意位置。使用JUnit可以沒有main()入口進行測試。
DOM4J在靈活性和對復雜xml的支持上都要強於DOM
DOM4J的應用范圍非常的廣,例如在三大框架的Hibernate中是使用DOM4J的方式解析文件的。
DOM是w3c組織提供的一個官方解析方式,在一定程度上是有所應用的。
當XML文件比較大的時候,會發現DOM4J比較好用
1.JUnit:Java提供的單元測試;@Test注解;采用JUnit不需要程序入口main方法
2.性能測試結果:幾kB的xml文件;建議使用DOM4J解析
DOM-33ms
SAX-6ms
JDOM-69ms
DOM4J-45ms
工程右鍵build path --Add library--JUnit單元測試 --version:JUnit4
DOM:33,SAX:6
JDOM:69;DOM4J:45
DOM 有可能溢出
多使用DOM4J