每次回到宿捨想看部電影才發現很長時間沒有去bt站淘種子了, 然而天天去站上找適合自己類型的電影又是一件費時又費力的事兒, 所以周末花時間寫了一個可配置的爬子, 能夠根據不同人的不同需求去自動下載種子文件, 並且能夠避免不同分類中的重復電影
後期還會加入下載隊列的功能, 在檢測宿捨無人用網的時候開啟bt下載, 有人接入wifi就暫停
項目地址: https://github.com/hwding/btDigger , 眾人拾柴火焰高, 歡迎共同制作...
(爬子依賴'bt天堂'這個種子站)
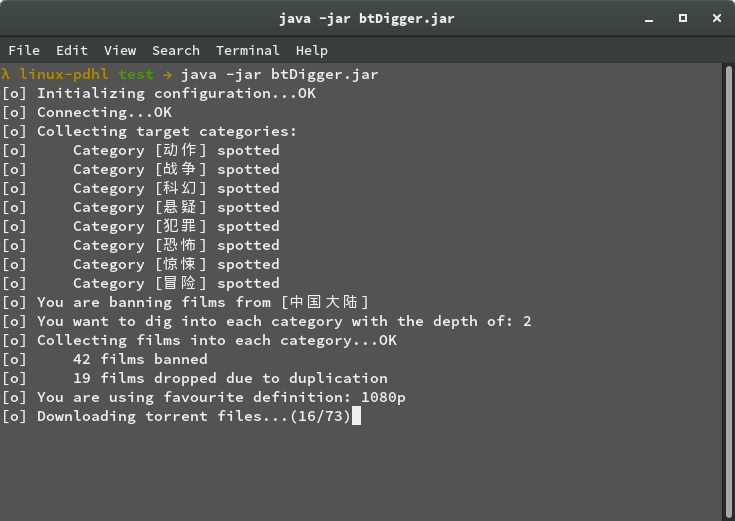
運行起來是這個樣子的
開始分析這個爬子的制作過程
首先我想讓它具有以下靈活性, 請看config.json:
{
"regions-banned":[
"中國大陸"
],
"depth":"2",
"definition":"1080p",
"categories":[
"動作",
"戰爭",
"科幻",
"懸疑",
"犯罪",
"恐怖",
"驚悚",
"冒險"
]
}
能夠屏蔽大陸地區的電影, 每個分類的頁面挖掘深度為2, 優先下載1080p的種子, 並且指定 "動作","戰爭","科幻"... 這幾類
在程序啟動後首先讀入配置文件並解析, 解析器采用單例模式以方便在其它類中載入配置
main方法中: ConfigLoader.getInstance();
ConfigLoader類:
1 import org.json.JSONArray;
2 import org.json.JSONObject;
3 import java.io.*;
4 import java.util.ArrayList;
5
6 class ConfigLoader {
7 private static ConfigLoader configLoader = null;
8 private static final String FILE_NAME = "config.json";
9 private static ArrayList<String> regions_banned = new ArrayList<>();
10 private static ArrayList<String> categories = new ArrayList<>();
11 private static int depth;
12 private static String definition;
13
14 private ConfigLoader() {
15 String jsonString = extractJSON();
16 JSONObject jsonObject = new JSONObject(jsonString);
17 JSONArray regions_banned_array = jsonObject.getJSONArray("regions-banned");
18 JSONArray categories_array = jsonObject.getJSONArray("categories");
19 for (Object each : regions_banned_array)
20 regions_banned.add((String) each);
21 for (Object each : categories_array)
22 categories.add((String) each);
23 depth = Integer.parseInt(jsonObject.getString("depth"));
24 definition = jsonObject.getString("definition");
25 }
26
27 static synchronized ConfigLoader getInstance() {
28 if (configLoader==null)
29 configLoader = new ConfigLoader();
30 return configLoader;
31 }
32
33 ArrayList<String> getRegions_banned() {
34 return regions_banned;
35 }
36
37 ArrayList<String> getCategories() {
38 return categories;
39 }
40
41 int getDepth() {
42 return depth;
43 }
44
45 String getDefinition() {
46 return definition;
47 }
48
49 private String extractJSON() {
50 File file = new File(FILE_NAME);
51 String jsonString = "";
52 String temp;
53 try {
54 BufferedReader bufferedReader = new BufferedReader(
55 new InputStreamReader(
56 new FileInputStream(file), "UTF-8"));
57 while ((temp = bufferedReader.readLine()) != null)
58 jsonString+=temp;
59 } catch (FileNotFoundException e) {
60 System.out.println("\n[x] Configuration file not found");
61 System.exit(0);
62 } catch (IOException e) {
63 System.out.println("\n[x] An error occurred when trying to read the configuration file");
64 System.exit(0);
65 }
66 return jsonString;
67 }
68 }
這裡就是簡單地將文件中的屬性賦給對應的類成員變量
然後main方法會啟動頁面解析器: PageParser.getInstance();
頁面解析器在初始化成功後會自動根據配置進行解析
首先檢查能否連接'bt天堂'網站
然後開始在首頁中查找我們需要的電影分類的次級鏈接地址, 在網頁源代碼中是這樣的存在
2 <div class="Btitle"><a href="/category.php?/%e5%8a%a8%e4%bd%9c/" title="動作電影">動作</a></div> 3 <div class="Btitle"><a href="/category.php?/%e6%88%98%e4%ba%89/" title="戰爭電影">戰爭</a></div> 4 <div class="Btitle"><a href="/category.php?/%e5%89%a7%e6%83%85/" title="劇情電影">劇情</a></div> 5 <div class="Btitle"><a href="/category.php?/%e7%88%b1%e6%83%85/" title="愛情電影">愛情</a></div> 6 <div class="Btitle"><a href="/category.php?/%e7%a7%91%e5%b9%bb/" title="科幻電影">科幻</a></div> 7 <div class="Btitle"><a href="/category.php?/%e6%82%ac%e7%96%91/" title="懸疑電影">懸疑</a></div> 8 <div class="Btitle"><a href="/category.php?/%e5%ae%b6%e5%ba%ad/" title="家庭電影">家庭</a></div> 9 <div class="Btitle"><a href="/category.php?/%e7%8a%af%e7%bd%aa/" title="犯罪電影">犯罪</a></div> 10 <div class="Btitle"><a href="/category.php?/%e6%81%90%e6%80%96/" title="恐怖電影">恐怖</a></div> 11 <div class="Btitle"><a href="/category.php?/%e5%8a%a8%e7%94%bb/" title="動畫電影">動畫</a></div> 12 <div class="Btitle"><a href="/category.php?/%e5%96%9c%e5%89%a7" title="喜劇電影">喜劇</a></div> 13 <div class="Btitle"><a href="/category.php?/%e6%83%8a%e6%82%9a" title="驚悚電影">驚悚</a></div> 14 <div class="Btitle"><a href="/category.php?/%e5%86%92%e9%99%a9" title="冒險電影">冒險</a></div>
所以我們只需要收集名為class屬性為Btitle的標簽, 並將標簽的內容與我們的目標分類數組中的每一項一一比對即可
然後再將其中的href屬性的值保存起來用於訪問各個分類
1 Elements bTitles = document.select("div[class=\"Btitle\"]");
2 for (Element each : bTitles) {
3 Element thisCategory = each.select("a").first();
4 ArrayList<String> categories = configLoader.getCategories();
5 if (!categories.contains(thisCategory.text()))
6 continue;
7 targetCategoriesSubURLs.add(thisCategory.attr("href"));
8 System.out.println("[o] \tCategory ["+thisCategory.text()+"] spotted");
完成分類鏈接的收集之後, 開始收集各個分類之中的電影: parseCategoryPage();
這一步的工作就是屏蔽不想要的電影(此配置屏蔽中國大陸地區電影)並且丟棄不同分類下的同一個電影
parseCategoryPage()方法如下

注意這裡會先收集分類頁面底部的頁數導航欄, 並且用一個循環去根據指定的深度訪問頁面
此處深度為2, 所以會訪問第一頁和第二頁
分類頁面底部的頁數導航欄在網頁源代碼中是這樣的
1 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/1/'>首頁</a></li> 2 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/-1/'>上一頁</a></li> 3 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/1/'>1</a></li> 4 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/2/'>2</a></li> 5 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/3/'>3</a></li> 6 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/4/'>4</a></li> 7 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/5/'>5</a></li> 8 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/6/'>6</a></li> 9 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/7/'>7</a></li> 10 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/8/'>8</a></li> 11 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/9/'>9</a></li> 12 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/10/'>10</a></li> 13 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/11/'>11</a></li> 14 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/1/'>下一頁</a></li> 15 <li><a href='/category.php?/%E7%8A%AF%E7%BD%AA/102/'>末頁</a></li>
解析的方法同上
完成並收集了符合要求的電影的頁面鏈接之後, 我們將開始進入到每一個電影的詳情頁並找到最好的種子去下載
這裡會調用 parseFilmPage() 方法
每個電影詳情頁會有種子列表, 提供不同清晰度(720p, 1080p, BluRay 720p, BluRay 1080p等), 為了不犧牲清晰度也不讓硬盤爆滿, 配置文件中指定最喜愛的清晰度為1080p
種子列表在網頁源代碼中如下, 解析方式同上上...
1 <div class="tinfo"> 2 <a href="/download.php?n=%E6%B4%9B%E5%9F%8E%E5%B1%A0%E6%89%8Bbt%E7%A7%8D%E5%AD%90%E4%B8%8B%E8%BD%BD.720p%E9%AB%98%E6%B8%85.torrent&temp=yes&id=27808&uhash=b57db4fed7d35c8d0924033f" title="【720p高清】洛城屠手 /L.A. Slasher .2015.1.02GBBT種子下載" target="_blank"><p class="torrent"><img border="0" src="/style/torrent.gif" alt="">【720p高清】洛城屠手<i>/L.A. Slasher</i>.2015.<em>1.02GB</em>.torrent</p></a> 3 <ul class="btTree treeview"><li><span class="file"><font color="#999">本torrent文件由BT天堂(www.BTtiantang.com)提供!</font></span></li><li><span class="video">L.A.Slasher.2015.720p.BluRay.H264.AAC-RARBG.mp4<small>1.02GB</small></span></li><li><span class="file">L.A.Slasher.2015.720p.BluRay.H264.AAC-RARBG.nfo<small>3.97KB</small></span></li><li><span class="video">RARBG.mp4<small>992.93KB</small></span></li></ul> 4 </div> 5 <div class="tinfo"> 6 <a href="/download.php?n=%E6%B4%9B%E5%9F%8E%E5%B1%A0%E6%89%8Bbt%E7%A7%8D%E5%AD%90%E4%B8%8B%E8%BD%BD.1080p%E9%AB%98%E6%B8%85.torrent&temp=yes&id=27808&uhash=04645321cb7afdbdee192d1d" title="【1080p高清】洛城屠手 /L.A. Slasher .2015.1.61GBBT種子下載" target="_blank"><p class="torrent"><img border="0" src="/style/torrent.gif" alt="">【1080p高清】洛城屠手<i>/L.A. Slasher</i>.2015.<em>1.61GB</em>.torrent</p></a> 7 <ul class="btTree treeview"><li><span class="file"><font color="#999">本torrent文件由BT天堂(www.BTtiantang.com)提供!</font></span></li><li><span class="video">L.A.Slasher.2015.1080p.BluRay.H264.AAC-RARBG.mp4<small>1.61GB</small></span></li><li><span class="file">L.A.Slasher.2015.1080p.BluRay.H264.AAC-RARBG.nfo<small>3.97KB</small></span></li><li><span class="video">RARBG.mp4<small>992.93KB</small></span></li></ul> 8 </div>
這裡僅僅提供了720p和1080p兩種清晰度的種子, 在多種清晰度的情況下, 爬子發現1080p的就會直接跳出對種子列表的遍歷, 否則就去下載最高清的那個
1 for (Element eachBtFileLink : btFileLinks) {
2 Element info = eachBtFileLink.select("span[class=\"video\"]").first();
3 if (info.text().contains(configLoader.getDefinition())) {
4 targetBtFileLinkSuffix = eachBtFileLink.select("a").first().attr("href");
5 break;
6 }
7 targetBtFileLinkSuffix = eachBtFileLink.select("a").first().attr("href");
8 }
每發現一個目標種子就緊接著去訪問它的下載頁面
通過攔截POST請求和查看頁面源代碼, 我們發現每個種子的下載頁面都有arcid和uhash兩個屬性, POST的時候必須寫入這兩個東西才行
首先收集頁面中這兩個屬性的值
1 String arcid = null;
2 String uhash = null;
3 boolean hasArcid = false;
4 boolean hasUhash = false;
5 while ((temp = bufferedReader.readLine()) != null) {
6 if (temp.contains("var _arcid")) {
7 arcid = temp.substring(temp.indexOf("\"")+1, temp.lastIndexOf("\""));
8 hasArcid = true;
9 }
10 if (temp.contains("var _uhash")) {
11 uhash = temp.substring(temp.indexOf("\"")+1, temp.lastIndexOf("\""));
12 hasUhash = true;
13 }
14 }
如果兩個屬性值都拿到了就可以提交POST請求去下載種子文件啦
1 if (hasArcid && hasUhash) {
2 URL requestUrl = new URL(REQUEST_URL);
3 HttpURLConnection httpUrlConnection = (HttpURLConnection) requestUrl.openConnection();
4 httpUrlConnection.setInstanceFollowRedirects(false);
5 httpUrlConnection.setDoOutput(true);
6 httpUrlConnection.setRequestMethod("POST");
7 String OUTPUT_DATA =
8 "action=download" +
9 "&id=" +
10 arcid +
11 "&uhash=" +
12 uhash;
13 OutputStreamWriter outputStreamWriter = new OutputStreamWriter(
14 httpUrlConnection.getOutputStream());
15 outputStreamWriter.write(OUTPUT_DATA);
16 outputStreamWriter.flush();
17 outputStreamWriter.close();
18 System.out.print("\r");
19 System.out.print("[o] Downloading torrent files...("+i+"/"+validFilmSubURLs.size()+")");
20 File file = new File(uhash+".torrent");
21 InputStream inputStream = httpUrlConnection.getInputStream();
22 FileOutputStream fileOutputStream = new FileOutputStream(file);
23 byte[] buffer = new byte[1024];
24 int length;
25 while ((length = inputStream.read(buffer)) != -1) {
26 fileOutputStream.write(buffer, 0, length);
27 fileOutputStream.flush();
28 }
29 fileOutputStream.close();
30 httpUrlConnection.disconnect();
31 }
到此為止種子收集的模塊就初具雛形