一:Hive本質是是什麼
1:hive是分布式又是數據倉庫,同時又是查詢引擎,Spark SQL只是取代的HIVE的查詢引擎這一部分,企業一般使用Hive+spark SQL進行開發
2:hive的主要工作
1> 把HQL翻譯長map-reduce的代碼,並且有可能產生很多mapreduce的job
2> 把生產的Mapreduce代碼及相關資源打包成jar並發布到Hadoop的集群當中並進行運行
3:hive架構
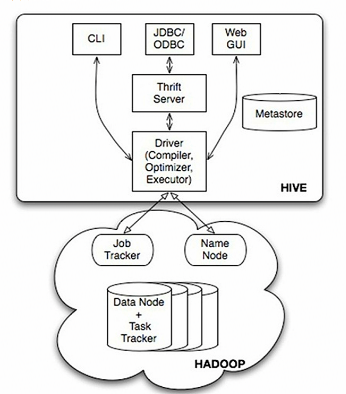
4:hive默認情況下用derby存儲元數據,所以在生產環境下一般會采用多用戶的數據庫進行元數據的存儲,並可以讀寫分離和備份,一般使用主節點寫,從節點讀,一般使用mysql
5:hive數據倉庫數據的具體存儲


二:SparkSQL 和DataFrame
1:處理一切存儲介質和各種格式的數據(可以擴展sparksql來讀取更多類型的數據)
2:Spark SQL把數據倉庫的計算速度推向了新的高度(Tungsten成熟之後會更厲害)
3:Spark SQL 推出的Dataframe可以讓數據倉庫直接使用機器學習,圖計算等復雜算法
4:HIVE+Spark SQL+DataFrame:
i> Hive:負責廉價的數據倉庫存儲
ii>Spark Sql:負責高速的計算
iii> DataFrame:負責復雜的數據挖掘
三: DataFrame與RDD
1:DataFrame是一個分布式的table
2:RDD和DataFrame的根本差異
1.RDD是以Record為單位的,
2.DataFrame包含了每一個Record的Metadata信息,也就是說DataFrame的的優化是基於列的優化,RDD是基於行的優化