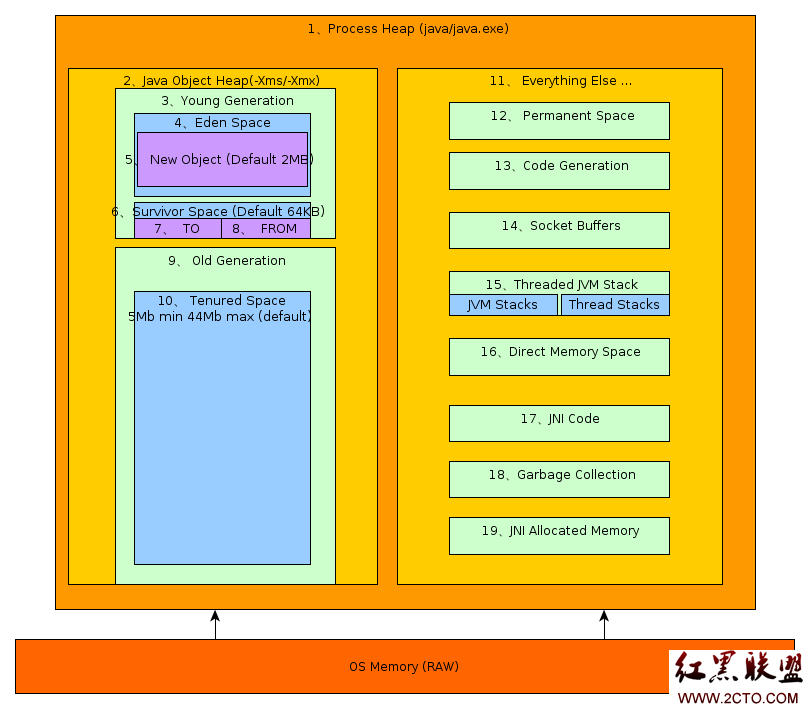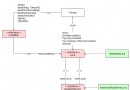
1.JVM內存模型
JVM運行時內存=共享內存區+線程內存區

1).共享內存區
共享內存區=持久帶+堆
持久帶=方法區+其他
堆=Old Space+Young Space
Young Space=Eden+S0+S1

(1)持久帶
JVM用持久帶(Permanent Space)實現方法區,主要存放所有已加載的類信息,方法信息,常量池等等。
可通過-XX:PermSize和-XX:MaxPermSize來指定持久帶初始化值和最大值。
Permanent Space並不等同於方法區,只不過是Hotspot JVM用Permanent Space來實現方法區而已,有些虛擬機沒有Permanent Space而用其他機制來實現方法區。
(2)堆
堆,主要用來存放類的對象實例信息。
堆分為Old Space(又名,Tenured Generation)和Young Space。
Old Space主要存放應用程序中生命周期長的存活對象;
Eden(伊甸園)主要存放新生的對象;
S0和S1是兩個大小相同的內存區域,主要存放每次垃圾回收後Eden存活的對象,作為對象從Eden過渡到Old Space的緩沖地帶(S是指英文單詞Survivor Space)。
堆之所以要劃分區間,是為了方便對象創建和垃圾回收,後面垃圾回收部分會解釋。
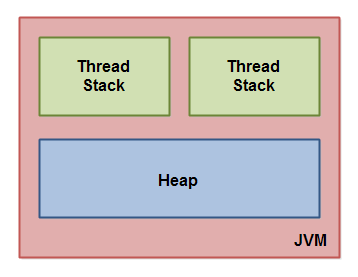
2).線程內存區
線程內存區=單個線程內存+單個線程內存+.......
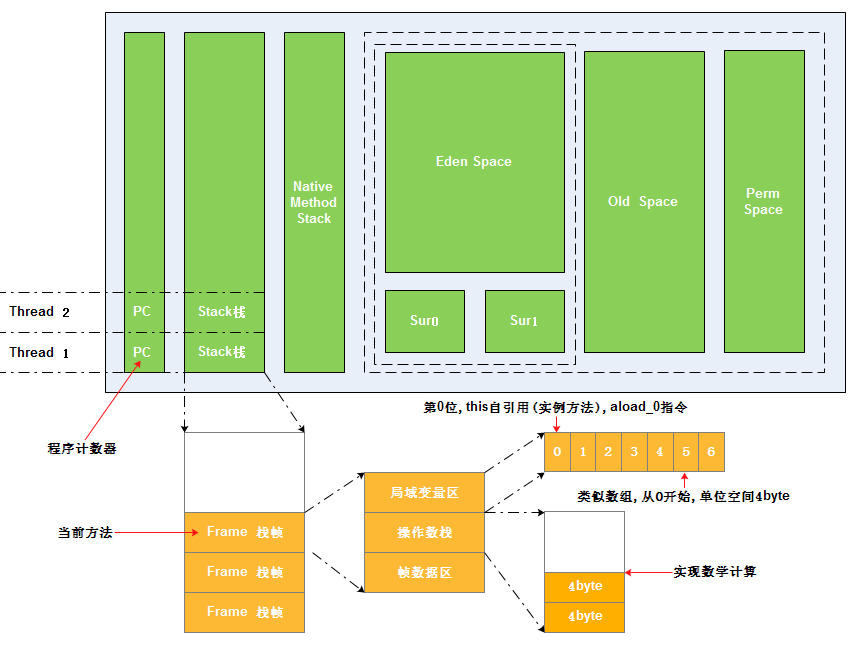
單個線程內存=PC Regster+JVM棧+本地方法棧
JVM棧=棧幀+棧幀+.....
棧幀=局域變量區+操作數區+幀數據區
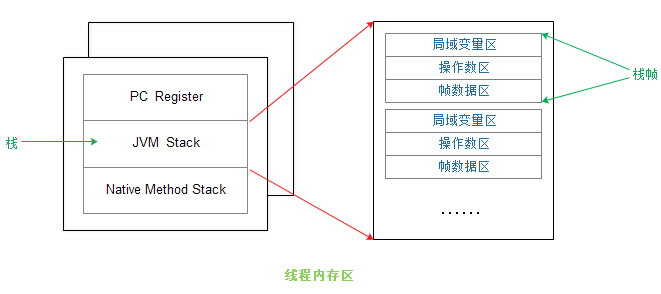
在Java中,一個線程會對應一個JVM棧(JVM Stack),JVM棧裡記錄了線程的運行狀態。
JVM棧以棧幀為單位組成,一個棧幀代表一個方法調用。棧幀由三部分組成:局部變量區、操作數棧、幀數據區。
(1)局部變量區
局部變量區,可以理解為一個以數組形式進行管理的內存區,從0開始計數,每個局部變量的空間是32位的,即4字節。
基本類型byte、char、short、boolean、int、float及對象引用等占一個局部變量空間,類型為short、byte和char的值在存入數組前要被轉換成int值;long、double占兩個局部變量空間,在訪問long和double類型的局部變量時,只需要取第一個變量空間的索引即可,。
例如:
? 1 2 3 4 5 6 7 public static int runClassMethod(int i,long l,float f,double d,Object o,byte b) { return 0; } public int runInstanceMethod(char c,double d,short s,boolean b) { return 0; }對應的局域變量區是:
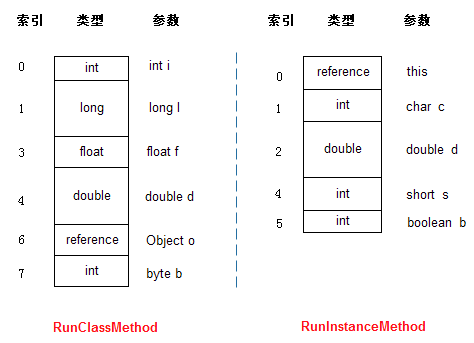
runInstanceMethod的局部變量區第一項是個reference(引用),它指定的就是對象本身的引用,也就是我們常用的this,但是在runClassMethod方法中,沒這個引用,那是因為runClassMethod是個靜態方法。
(2)操作數棧
操作數棧和局部變量區一樣,也被組織成一個以字長為單位的數組。但和前者不同的是,它不是通過索引來訪問的,而是通過入棧和出棧來訪問的。操作數棧是臨時數據的存儲區域。
例如:
? 1 2 3 int a= 100; int b =5; int c = a+b;對應的操作數棧變化為:
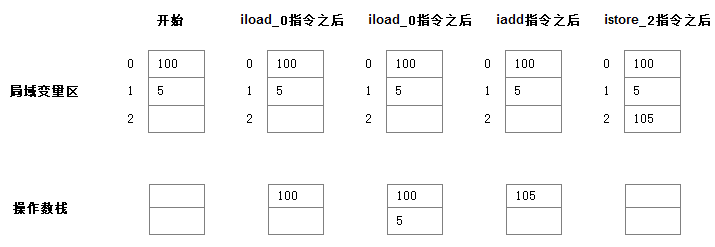
從圖中可以得出:操作數棧其實就是個臨時數據存儲區域,它是通過入棧和出棧來進行操作的。
PS:JVM實現裡,有一種基於棧的指令集(Hotspot,oracle JVM),還有一種基於寄存器的指令集(DalvikVM,安卓 JVM),兩者有什麼區別的呢?
基於棧的指令集有接入簡單、硬件無關性、代碼緊湊、棧上分配無需考慮物理的空間分配等優勢,但是由於相同的操作需要更多的出入棧操作,因此消耗的內存更大。 而基於寄存器的指令集最大的好處就是指令少,速度快,但是操作相對繁瑣。
示例:
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.demo3; public class Test { public static void foo() { int a = 1; int b = 2; int c = (a + b) * 5; } public static void main(String[] args) { foo(); } }基於棧的Hotspot的執行過程如下:
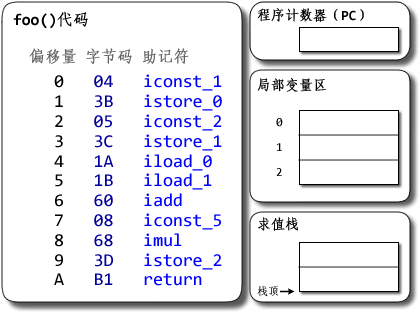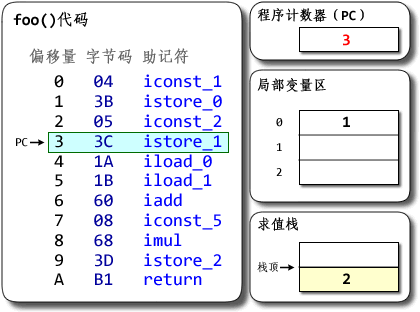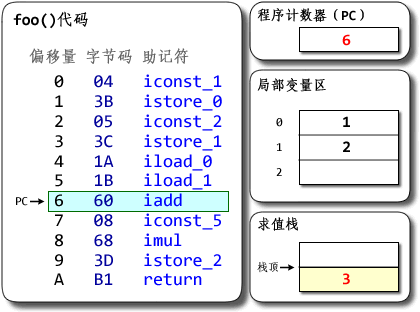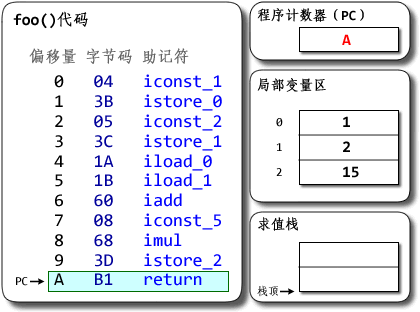
基於寄存器的DalvikVM執行過程如下所示:

上述兩種方式最終通過JVM執行引擎,CPU接收到的匯編指令是:

(3)幀數據區
幀數據區存放了指向常量池的指針地址,當某些指令需要獲得常量池的數據時,通過幀數據區中的指針地址來訪問常量池的數據。此外,幀數據區還存放方法正常返回和異常終止需要的一些數據。
2.垃圾回收機制
1)、為什麼要垃圾回收
JVM自動檢測和釋放不再使用的內存,提高內存利用率。
Java 運行時JVM會執行 GC,這樣程序員不再需要顯式釋放對象。
2)、回收哪些內存區域
因為線程內存區隨著線程的產生和退出而分配和回收,所以垃圾回收主要集中在共享內存區,也就是持久帶(Permanent Space)和堆(Heap)。
3)、如何判斷對象已死 (對象標記)
(1)引用計數法
引用計數法就是通過一個計數器記錄該對象被引用的次數,方法簡單高效,但是解決不了循環引用的問題。比如對象A包含指向對象B的引用,對象B也包含指向對象A的引用,但沒有引用指向A和B,這時當前回收如果采用的是引用計數法,那麼對象A和B的被引用次數都為1,都不會被回收。JVM不是采用這種方法。
(2) 根搜索(可達性分析算法)
根搜索(可達性分析算法)可以解決對象循環引用的問題,基本原理是:通過一個叫“GC ROOT”根對象作為起點,然後根據關聯關系,向下節點搜索,搜索路徑叫引用鏈,也就是常說的引用。從“GC ROOT”根對象找不到任何一條路徑與之相連的對象,就被判定可以回收,相當於這對象找不到家的感覺。
示例圖:
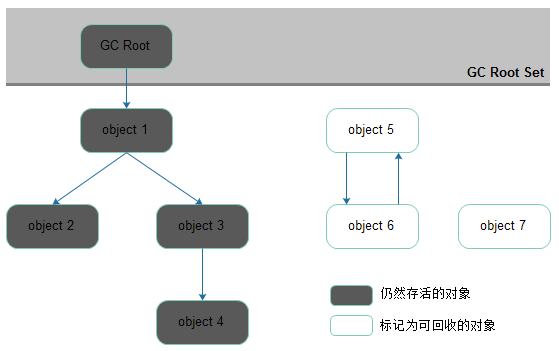
GC會收集那些不是GC root且沒有被GC root引用的對象。一個對象可以屬於多個GC root。
GC root有幾下種:
虛擬機棧(棧幀中的本地變量表)中引用的對象
方法區中類靜態屬性引用的對象
方法區中常量引用的對象
本地方法棧中JNI(native方法)引用的對象
用於JVM特殊目的對象,例如系統類加載器等等
雖然有可達性分析算法來判定對象狀態,但這並不是對象是否被回收的條件,對象回收的條件遠遠比這個復雜。無法通過GC ROOT關聯到的對象,不都是立刻被回收。如果這個對象沒有被關聯到,而且沒有被mark2標記,那麼會進入一個死緩的階段,被第一次標記(mark1),然後被放入一個F-Queue隊列;如果這個對象被mark2標記了,那麼這個對象將會被回收。
F-Queue隊列由一個優先級較低的Finalizer線程去執行,其中的mark1對象等待執行自己的finalize()方法(JVM並不保證等待finalize()方法運行結束,因為finalize() 方法或者執行慢,或者死循環,會影響該隊列其他元素執行)。執行mark1對象的finalize()方法,就會進行第二次標記(mark2)。以後的GC都會按這個邏輯執行“搜索,標記1,標記2”。
這一“標記”過程是後續垃圾回收算法的基礎。
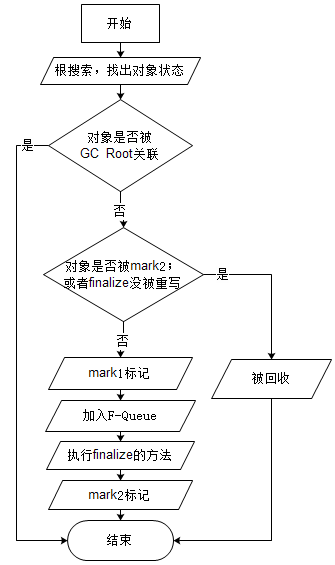
PS:
如果在finalize() 方法體內,再次對本對象進行引用,那麼對象就復活了。
finalize()方法只會被執行一次,所以對象只有一次復活的機會。
3)垃圾回收算法
垃圾回收算法主要有三種:
標記-清除
標記-復制
標記-整理
這三種都有“標記”過程,這個標記過程就是上述的根搜索(可達性分析算法)。後面的“清除”、“復制”和“整理”動作,是具體的對象被回收的實現方式。
(1)標記-清除
通過根搜索(可達性分析算法)標記完成後,直接將標記為垃圾的對象所占內存空間釋放。這種算法的缺點是內存碎片多。
雖然缺點明顯,這種策略卻是後兩種策略的基礎。正因為它的缺點,所以促成了後兩種策略的產生。
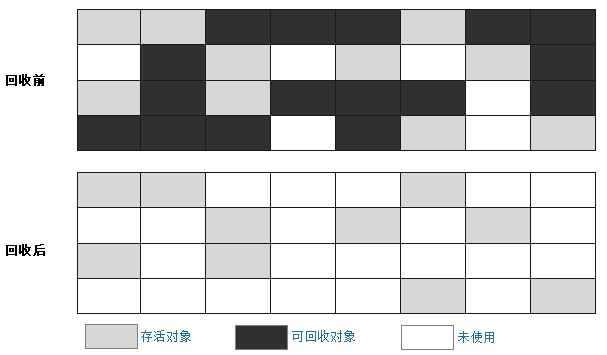
動圖:

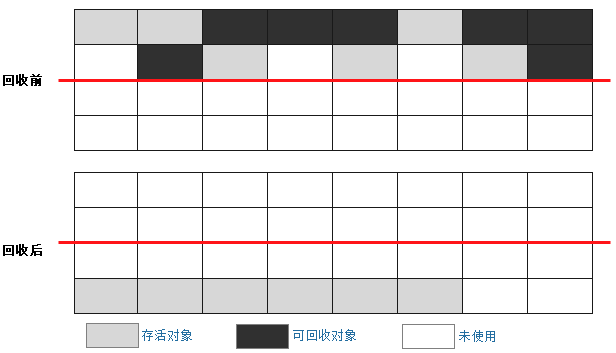
(2)標記-復制
通過根搜索(可達性分析算法)標記完成後,將內存分為兩塊,將一塊內存中保留的對象全部復制到另
一塊空閒內存中。
動圖:

這種算法的缺點是,可用內存變成了一半。怎麼解決這個缺點呢?
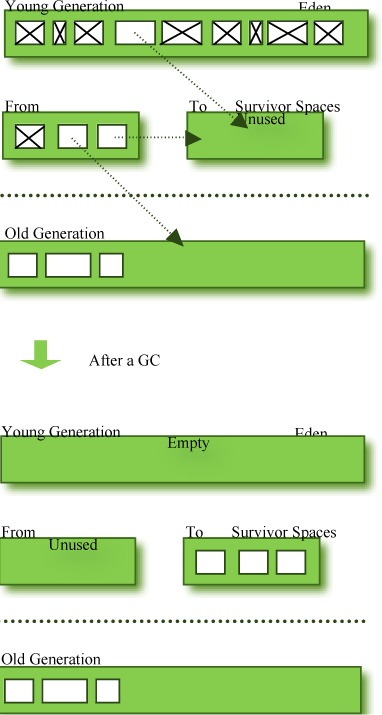
JVM將堆(heap)分成young區和old區。young區包括eden、s0、s1,並且三個區之間的大小有一定比例。例如,按8:1:1分成一塊Eden和兩小塊Survivor區,每次GC時,young區裡,將Eden和S0中存活的對象復制到另一塊空閒的S1中。
young區的垃圾回收是經常要發生的,被稱為Minor GC(次要回收)。一般情況下,當新對象生成,並且在Eden申請空間失敗時,就會觸發Minor GC,對Eden區域進行GC,清除非存活對象,並且把尚且存活的對象移動到Survivor區。然後整理Survivor的兩個區。這種方式的GC是對Young space的Eden區進行,不會影響到Old space。因為大部分對象都是從Eden區開始的,同時Eden區不會分配的很大,所以Eden區的GC會頻繁進行。因而,一般在這裡需要使用速度快、效率高的算法,使Eden去能盡快空閒出來。
Minor GC主要過程:
a、新生成的對象在Eden區完成內存分配;
b、當Eden區滿了,再創建對象,會因為申請不到空間,觸發minorGC,進行young(eden+1survivor)區的垃圾回收。(為什麼是eden+1survivor:兩個survivor中始終有一個survivor是空的,空的那個被標記成To Survivor);
c、minorGC時,Eden不能被回收的對象被放入到空的survivor(也就是放到To Survivor,同時Eden肯定會被清空),另一個survivor(From Survivor)裡不能被GC回收的對象也會被放入這個survivor(To Survivor),始終保證一個survivor是空的。(MinorGC完成之後,To Survivor 和 From Survivor的標記互換);
d、當做第3步的時候,如果發現存放對象的那個survivor滿了,則這些對象被copy到old區,或者survivor區沒有滿,但是有些對象已經足夠Old(通過XX:MaxTenuringThreshold參數來設置),也被放入Old區。(對象在Survivor區中每熬過一次Minor GC,年齡就增加1歲,當它的年齡增加到一定程度(默認為15歲)時,就會晉升到老年代中)
(3)標記-整理
old space也可以標記-復制策略嗎?當然不行!
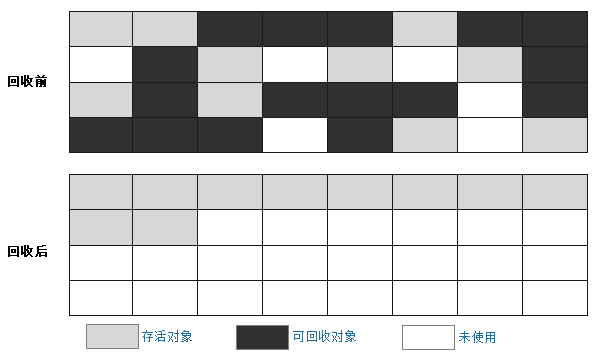
young space中的對象大部分都是生命周期較短的對象,每次GC後,所剩下的活對象數量不是很大。而old space中的對象大部分都是生命周期特別長的對象,即使GC後,仍然會剩下大量的活對象。如果仍然采用復制動作,回收效率會變得非常低。
根據old space的特點,可以采用整理動作。整理時,先清除掉應該清除的對象,然後把存活對象“壓縮”到堆的一端,按順序排放。
動圖:

Old space(+Permanent Space)的垃圾回收是偶爾發生的,被稱為Full GC(主要回收)。Full GC因為需要對整個堆進行回收,包括Young、Old和Perm,所以比Minor GC要慢,因此應該盡可能減少Full GC的次數。在對JVM調優的過程中,很大一部分工作就是對於FullGC的調節。
有如下原因可能導致Full GC:
年老代(Tenured)被寫滿
持久代(Perm)被寫滿
System.gc()被顯示調用
上一次GC之後Heap的各域分配策略動態變化
4)、垃圾收集器
垃圾收集算法是內存回收的理論基礎,而垃圾收集器就是內存回收的具體實現。
堆(Heap)分代被目前大部分JVM所采用。它的核心思想是根據對象存活的生命周期將內存劃分為若干個不同的區域。一般情況下將堆區劃分為old space和Young space,old space的特點是每次垃圾收集時只有少量對象需要被回收,而Young space的特點是每次垃圾回收時都有大量的對象需要被回收,那麼就可以根據不同代的特點采取最適合的收集算法。
目前大部分垃圾收集器對於Young space都采取“標記-復制”算法。而由於Old space的特點是每次回收都只回收少量對象,一般使用的是“標記-整理”算法。
(1)Young Space上的GC實現:
Serial(串行): Serial收集器是最基本最古老的收集器,它是一個單線程收集器,並且在它進行垃圾收集時,必須暫停所有用戶線程。Serial收集器是針對新生代的收集器,采用的是“標記-復制”算法。它的優點是實現簡單高效,但是缺點是會給用戶帶來停頓。這個收集器類型僅應用於單核CPU桌面電腦。使用serial收集器會顯著降低應用程序的性能。
ParNew(並行): ParNew收集器是Serial收集器的多線程版本,使用多個線程進行垃圾收集。
Parallel Scavenge(並行): Parallel Scavenge收集器是一個新生代的多線程收集器(並行收集器),它在回收期間不需要暫停其他用戶線程,其采用的是“標記-復制”算法,該收集器與前兩個收集器有所不同,它主要是為了達到一個可控的吞吐量。
(2)Old Space上的GC實現:
Serial Old(串行):Serial收集器的Old Space版本,采用的是“標記-整理”算法。這個收集器類型僅應用於單核CPU桌面電腦。使用serial收集器會顯著降低應用程序的性能。
Parallel Old(並行):Parallel Old是Parallel Scavenge收集器的Old Space版本(並行收集器),使用多線程和“標記-整理”算法。
CMS(並發):CMS(Current Mark Sweep)收集器是一種以獲取最短回收停頓時間為目標的收集器,它是一種並發收集器,采用的是"標記-清除"算法。
(3).G1
G1(Garbage First)收集器是JDK1.7提供的一個新收集器,G1收集器基於“標記-整理”算法實現,也就是說不會產生內存碎片。還有一個特點之前的收集器進行收集的范圍都是整個新生代或老年代,而G1將整個Java堆(包括新生代,老年代)。
3.JVM參數
1).堆
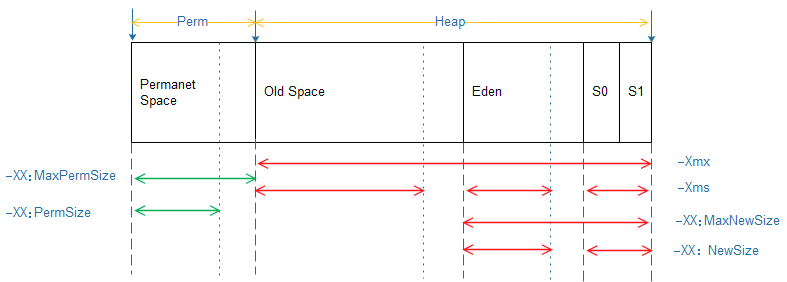
-Xmx:最大堆內存,如:-Xmx512m
-Xms:初始時堆內存,如:-Xms256m
-XX:MaxNewSize:最大年輕區內存
-XX:NewSize:初始時年輕區內存.通常為 Xmx 的 1/3 或 1/4。新生代 = Eden + 2 個 Survivor 空間。實際可用空間為 = Eden + 1 個 Survivor,即 90%
-XX:MaxPermSize:最大持久帶內存
-XX:PermSize:初始時持久帶內存
-XX:+PrintGCDetails。打印 GC 信息
-XX:NewRatio 新生代與老年代的比例,如 –XX:NewRatio=2,則新生代占整個堆空間的1/3,老年代占2/3
-XX:SurvivorRatio 新生代中 Eden 與 Survivor 的比值。默認值為 8。即 Eden 占新生代空間的 8/10,另外兩個 Survivor 各占 1/10
2).棧
-xss:設置每個線程的堆棧大小. JDK1.5+ 每個線程堆棧大小為 1M,一般來說如果棧不是很深的話, 1M 是絕對夠用了的。
3).垃圾回收
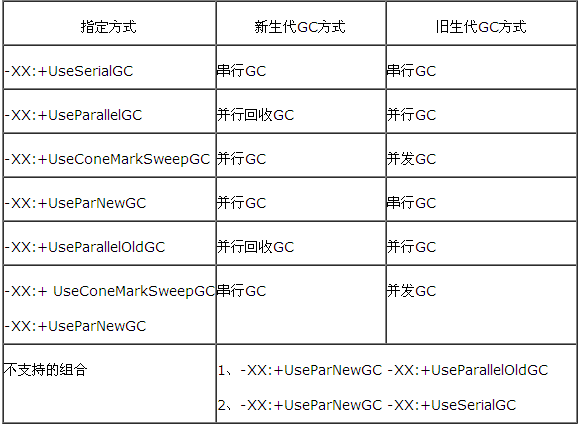
4).JVM client模式和server模式
Java_home/bin/java命令有一個-server和-client參數,該參數標識了JVM以server模式或client模式啟動。
JVM Server模式與client模式啟動,最主要的差別在於:-Server模式啟動時,速度較慢,但是一旦運行起來後,性能將會有很大的提升。當虛擬機運行在-client模式的時候,使用的是一個代號為C1的輕量級編譯器, 而-server模式啟動的虛擬機采用相對重量級,代號為C2的編譯器. C2比C1編譯器編譯的相對徹底,,服務起來之後,性能更高。
(1)查看當前JVM默認啟動模式
java -version 可以直接查看出默認使用的是client還是 server。


(2)JVM默認啟動模式自動偵測
從JDK 5開始,如果沒有顯式地用-client或者-server參數,那麼JVM啟動時,會根據機器配置和JDK的版本,自動判斷該用哪種模式。

the definition of a server-class machine is one with at least 2 CPUs and at least 2GB of physical memory.
windows平台,64位版本的JDK,沒有提供-client模式,直接使用server模式。
(3).通過配置文件,改變JVM啟動模式
兩種模式的切換可以通過更改配置(jvm.cfg配置文件)來實現:
32位的JVM配置文件在JAVA_HOME/jre/lib/i386/jvm.cfg,
64位的JVM配置文件在JAVA_HOME/jre/lib/amd64/jvm.cfg, 目前64位只支持server模式。
例如:
32位版本的JDK 5的jvm.cfg文件內容:
? 1 2 3 4 5 6 -client KNOWN -server KNOWN -hotspot ALIASED_TO -client -classic WARN -native ERROR -green ERROR64位版本的JDK 7的jvm.cfg文件內容:
? 1 2 3 4 5 6 -server KNOWN -client IGNORE -hotspot ALIASED_TO -server -classic WARN -native ERROR -green ERROR
4.堆 VS 棧
JVM棧是運行時的單位,而JVM堆是存儲的單位。
JVM棧代表了處理邏輯,而JVM堆代表了數據。
JVM堆中存的是對象。JVM棧中存的是基本數據類型和JVM堆中對象的引用。
JVM堆是所有線程共享,JVM棧是線程獨有。
PS:Java中的參數傳遞是傳值呢?還是傳址?
我們都知道:C 語言中函數參數的傳遞有:值傳遞,地址傳遞,引用傳遞這三種形式。但是在Java裡,方法的參數傳遞方式只有一種:值傳遞。所謂值傳遞,就是將實際參數值的副本(復制品)傳入方法內,而參數本身不會受到任何影響。
要說明這個問題,先要明確兩點:
1.引用在Java中是一種數據類型,跟基本類型int等等同一地位。
2.程序運行永遠都是在JVM棧中進行的,因而參數傳遞時,只存在傳遞基本類型和對象引用的問題。不會直接傳對象本身。
在運行JVM棧中,基本類型和引用的處理是一樣的,都是傳值。如果是傳引用的方法調用,可以理解為“傳引用值”的傳值調用,即“引用值”被做了一個復制品,然後賦值給參數,引用的處理跟基本類型是完全一樣的。但是當進入被調用方法時,被傳遞的這個引用值,被程序解釋(或者查找)到JVM堆中的對象,這個時候才對應到真正的對象。如果此時進行修改,修改的是引用對應的對象,而不是引用本身,即:修改的是JVM堆中的數據。所以這個修改是可以保持的了。
例如:
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.demo3; public class DataWrap { public int a; public int b; } package com.demo3; public class ReferenceTransferTest { public static void swap(DataWrap dw) { int tmp = dw.a; dw.a = dw.b; dw.b = tmp; } public static void main(String[] args) { DataWrap dw = new DataWrap(); dw.a = 6; dw.b = 9; swap(dw); } }對應的內存圖:
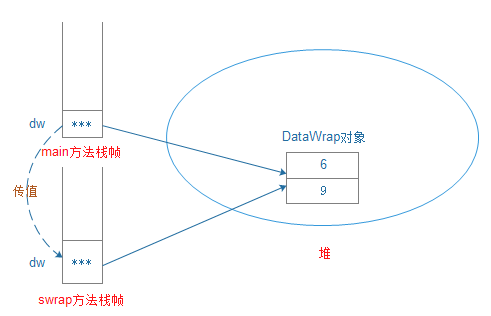
附: