我們在處理文件、浏覽網頁、編寫程序時,時不時會碰到亂碼的情況。亂碼幾乎總是令人心煩,讓人困惑。希望通過本節和下節文章,你可以自信從容地面對亂碼,恢復亂碼。
談亂碼,我們就要談數據的二進制表示,我們已經在前兩節談過整數和小數的二進制表示,接下了我們將討論字符和文本的二進制表示。
由於內容比較多,我們將分兩節來介紹。本節主要介紹各種編碼,亂碼產生的原因,以及簡單亂碼的恢復。下節我們介紹復雜亂碼的恢復。
編碼和亂碼聽起來比較復雜,文章也比較長,但其實並不復雜,請耐心閱讀,讓我們逐步來探討。
ASCII
世界上雖然有各種各樣的字符,但計算機發明之初沒有考慮那麼多,基本上只考慮了美國的需求,美國大概只需要128個字符,美國就規定了這128個字符的二進制表示方法。
這個方法是一個標准,稱為ASCII編碼,全稱是American Standard Code for Information Interchange,美國信息互換標准代碼。
128個字符用7個位剛好可以表示,計算機存儲的最小單位是byte,即8位,ASCII碼中最高位設置為0,用剩下的7位表示字符。這7位可以看做數字0到127,ASCII碼規定了從0到127個,每個數字代表什麼含義。
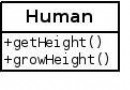
我們先來看數字32到126的含義,如下圖所示,除了中文之外,我們平常用的字符基本都涵蓋了,鍵盤上的字符大部分也都涵蓋了。
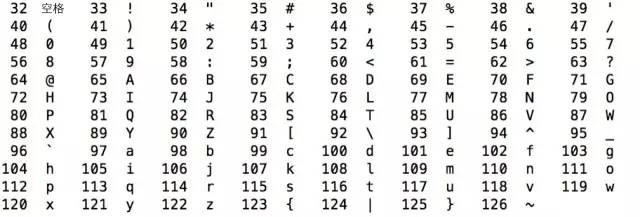
數字32到126表示的這些字符都是可打印字符,0到31和127表示一些不可以打印的字符,這些字符一般用於控制目的,這些字符中大部分都是不常用的,下表列出了其中相對常用的字符。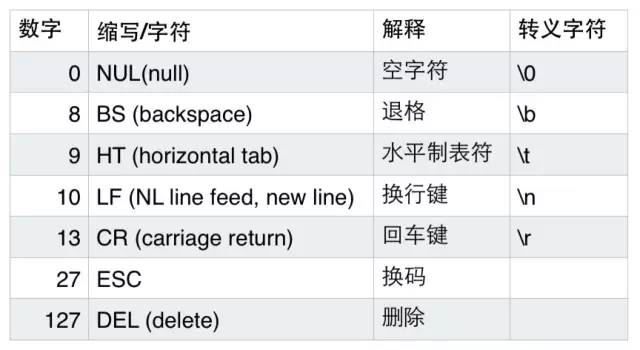
Ascii 碼對美國是夠用了,但對別的國家而言卻是不夠的,於是,各個國家的各種計算機廠商就發明了各種各種的編碼方式以表示自己國家的字符,為了保持與Ascii 碼的兼容性,一般都是將最高位設置為1。也就是說,當最高位為0時,表示Ascii碼,當為1時就是各個國家自己的字符。
在這些擴展的編碼中,在西歐國家中流行的是ISO 8859-1和Windows-1252,在中國是GB2312,GBK,GB18030和Big5,我們逐個來看下這些編碼。
ISO 8859-1
ISO 8859-1又稱Latin-1,它也是使用一個字節表示一個字符,其中0到127與Ascii一樣,128到255規定了不同的含義。
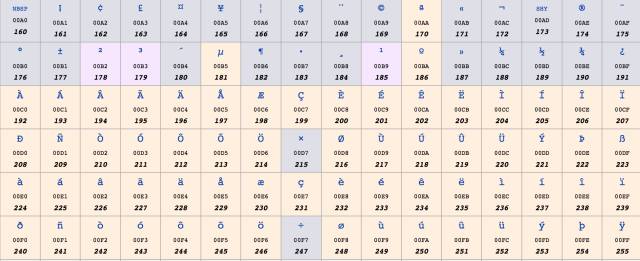
在128到255中,128到159表示一些控制字符,這些字符也不常用,就不介紹了。160到255表示一些西歐字符,如下圖所示:
Windows-1252
ISO 8859-1雖然號稱是標准,用於西歐國家,但它連歐元(€) 這個符號都沒有,因為歐元比較晚,而標准比較早。實際使用中更為廣泛的是Windows-1252編碼,這個編碼與ISO8859-1基本是一樣的,區別 只在於數字128到159,Windows-1252使用其中的一些數字表示可打印字符,這些數字表示的含義,如下圖所示:

這個編碼中加入了歐元符號以及一些其他常用的字符。基本上可以認為,ISO 8859-1已被Windows-1252取代,在很多應用程序中,即使文件聲明它采用的是ISO 8859-1編碼,解析的時候依然被當做Windows-1252編碼。
HTML5
甚至明確規定,如果文件聲明的是ISO 8859-1編碼,它應該被看做Windows-1252編碼。為什麼要這樣呢?因為大部分人搞不清楚ISO
8859-1和Windows-1252的區別,當他說ISO
8859-1的時候,其實他實際指的是Windows-1252,所以標准干脆就這麼強制了。
GB2312
美國和西歐字符用一個字節就夠了,但中文顯然是不夠的。中文第一個標准是GB2312。
GB2312標准主要針對的是簡體中文常見字符,包括約7000個漢字,不包括一些罕用詞,不包括繁體字。
GB2312固定使用兩個字節表示漢字,在這兩個字節中,最高位都是1,如果是0,就認為是Ascii字符。在這兩個字節中,其中高位字節范圍是0xA1-0xF7,低位字節范圍是0xA1-0xFE。
比如,"老馬"的GB2312編碼是(16進制表示):
老 馬 C0 CF C2 EDGBK
GBK建立在GB2312的基礎上,向下兼容GB2312,也就是說,GB2312編碼的字符和二進制表示,在GBK編碼裡是完全一樣的。
GBK增加了一萬四千多個漢字,共計約21000漢字,其中包括繁體字。
GBK同樣使用固定的兩個字節表示,其中高位字節范圍是0x81-0xFE,低位字節范圍是0x40-0x7E和0x80-0xFE。
需要注意的是,低位字節是從0x40也就是64開始的,也就是說,低位字節最高位可能為0。那怎麼知道它是漢字的一部分,還是一個Ascii字符呢?
其實很簡單,因為漢字是用固定兩個字節表示的,在解析二進制流的時候,如果第一個字節的最高位為1,那麼就將下一個字節讀進來一起解析為一個漢字,而不用考慮它的最高位,解析完後,跳到第三個字節繼續解析。
GB18030
GB18030向下兼容GBK,增加了五萬五千多個字符,共七萬六千多個字符。包括了很多少數民族字符,以及中日韓統一字符。
用兩個字節已經表示不了GB18030中的所有字符,GB18030使用變長編碼,有的字符是兩個字節,有的是四個字節。
在兩字節編碼中,字節表示范圍與GBK一樣。在四字節編碼中,第一個字節的值從0x81到0xFE,第二個字節的值從0x30到0x39,第三個字節的值從0x81到0xFE,第四個字節的值從0x30到0x39。
解析二進制時,如何知道是兩個字節還是四個字節表示一個字符呢?看第二個字節的范圍,如果是0x30到0x39就是四個字節表示,因為兩個字節編碼中第二字節都比這個大。
Big5
Big5是針對繁體中文的,廣泛用於台灣香港等地。
Big5包括1萬3千多個繁體字,和GB2312類似,一個字符同樣固定使用兩個字節表示。在這兩個字節中,高位字節范圍是0x81-0xFE,低位字節范圍是0x40-0x7E和0xA1-0xFE。
編碼匯總
我們簡單匯總一下上面的內容。
Ascii碼是基礎,一個字節表示,最高位設為0,其他7位表示128個字符。其他編碼都是兼容Ascii的,最高位使用1來進行區分。
西歐主要使用Windows-1252,使用一個字節,增加了額外128個字符。
中文大陸地區的三個主要編碼GB2312,GBK,GB18030,有時間先後關系,表示的字符數越來越多,且後面的兼容前面的,GB2312和GBK都是用兩個字節表示,而GB18030則使用兩個或四個字節表示。
香港台灣地區的主要編碼是Big5。
如果文本裡的字符都是Ascii碼字符,那麼采用以上所說的任一編碼方式都是一一樣的。
但如果有高位為1的字符,除了GB2312/GBK/GB18030外,其他編碼都是不兼容的,比如,Windows-1252和中文的各種編碼是不兼容的,即使Big5和GB18030都能表示繁體字,其表示方式也是不一樣的,而這就會出現所謂的亂碼。
初識亂碼
一個法國人,采用Windows-1252編碼寫了個文件,發送給了一個中國人,中國人使用GB18030來解析這個字符,看到的就是亂碼,我們舉個例子:
法 國人發送的是 "Pékin",Windows-1252的二進制是(采用16進制):50 E9 6B 69 6E,第二個字節E9對應é,其他都是Ascii碼,中國人收到的也是這個二進制,但是他把它看做成了GB18030編碼,GB18030中E9 6B對應的是字符"閗i",於是他看到的就是:"P閗in",這看來就是一個亂碼。
反之也是一樣的,一個GB18030編碼的文件如果被看做Windows-1252也是亂碼。
這 種情況下,之所以看起來是亂碼,是因為看待或者說解析數據的方式錯了。糾正的方式,只要使用正確的編碼方式進行解讀就可以了。很多文件編輯器,如 EditPlus, NotePad++, UltraEdit都有切換查看編碼方式的功能,浏覽器也都有切換查看編碼方式的功能,如Firefox,在菜單 "查看"->"文字編碼"中。
切換查看編碼的方式,並沒有改變數據的二進制本身,而只是改變了解析數據的方式,從而改變了數據看起來的樣子。(稍後我們會提到編碼轉換,它正好相反)。
很多時候,做這樣一個編碼查看方式的切換,就可以解決亂碼的問題。但有的時候,這樣是不夠的,我們稍後提到。
Unicode
以上我們介紹了中文和西歐的字符與編碼,但世界上還有很多別的國家的字符,每個國家的各種計算機廠商都對自己常用的字符進行編碼,在編碼的時候基本忽略了別的國家的字符和編碼,甚至忽略了同一國家的其他計算機廠商,這樣造成的結果就是,出現了太多的編碼,且互相不兼容。
世界上所有的字符能不能統一編碼呢?可以,這就是Unicode。
Unicode 做了一件事,就是給世界上所有字符都分配了一個唯一的數字編號,這個編號范圍從0x000000到0x10FFFF,包括110多萬。但大部分常用字符都 在0x0000到0xFFFF之間,即65536個數字之內。每個字符都有一個Unicode編號,這個編號一般寫成16進制,在前面加U+。大部分中文 的編號范圍在U+4E00到U+9FA5,例如,"馬"的Unicode是U+9A6C。
Unicode就做了這麼 一件事,就是給所有字符分配了唯一數字編號。它並沒有規定這個編號怎麼對應到二進制表示,這是與上面介紹的其他編碼不同的,其他編碼都既規定了能表示哪些 字符,又規定了每個字符對應的二進制是什麼,而Unicode本身只規定了每個字符的數字編號是多少。
那編號怎麼對應到二進制表示呢?有多種方案,主要有UTF-32, UTF-16和UTF-8。
UTF-32
這個最簡單,就是字符編號的整數二進制形式,四個字節。
但有個細節,就是字節的排列順序,如果第一個字節是整數二進制中的最高位,最後一個字節是整數二進制中的最低位,那這種字節序就叫“大端”(Big Endian, BE),否則,正好相反的情況,就叫“小端”(Little Endian, LE)。對應的編碼方式分別是UTF-32BE和UTF-32LE。
可以看出,每個字符都用四個字節表示,非常浪費空間,實際采用的也比較少。
UTF-16
UTF-16使用變長字節表示:
區分是兩個字節還是四個字節表示一個符號就看前兩個字節的編號范圍,如果是U+D800到U+DBFF,就是四個字節,否則就是兩個字節。
UTF-16也有和UTF-32一樣的字節序問題,如果高位存放在前面就叫大端(BE),編碼就叫UTF-16BE,否則就叫小端,編碼就叫UTF-16LE。
UTF-16常用於系統內部編碼,UTF-16比UTF-32節省了很多空間,但是任何一個字符都至少需要兩個字節表示,對於美國和西歐國家而言,還是很浪費的。
UTF-8
UTF-8就是使用變長字節表示,每個字符使用的字節個數與其Unicode編號的大小有關,編號小的使用的字節就少,編號大的使用的字節就多,使用的字節個數從1到4個不等。
具體來說,各個Unicode編號范圍對應的二進制格式如下圖所示:
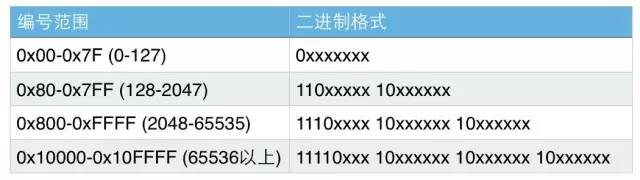
圖中的x表示可以用的二進制位,而每個字節開頭的1或0是固定的。
小於128的,編碼與Ascii碼一樣,最高位為0。其他編號的第一個字節有特殊含義,最高位有幾個連續的1表示一共用幾個字節表示,而其他字節都以10開頭。
對於一個Unicode編號,具體怎麼編碼呢?首先將其看做整數,轉化為二進制形式(去掉高位的0),然後將二進制位從右向左依次填入到對應的二進制格式x中,填完後,如果對應的二進制格式還有沒填的x,則設為0。
我們來看個例子,'馬'的Unicode編號是:0x9A6C,整數編號是39532,其對應的UTF-8二進制格式是:
1110xxxx 10xxxxxx 10xxxxxx
整數編號39532的二進制格式是 1001 101001 101100
將這個二進制位從右到左依次填入二進制格式中,結果就是其UTF-8編碼:
11101001 10101001 10101100
16進制表示為:0xE9A9AC
和UTF-32/UTF-16不同,UTF-8是兼容Ascii的,對大部分中文而言,一個中文字符需要用三個字節表示。
Uncode編碼小結
Unicode給世界上所有字符都規定了一個統一的編號,編號范圍達到110多萬,但大部分字符都在65536以內。Unicode本身沒有規定怎麼把這個編號對應到二進制形式。
UTF- 32/UTF-16/UTF-8都在做一件事,就是把Unicode編號對應到二進制形式,其對應方法不同而已。UTF-32使用4個字節,UTF-16 大部分是兩個字節,少部分是四個字節,它們都不兼容Ascii編碼,都有字節順序的問題。UTF-8使用1到4個字節表示,兼容Ascii編碼,英文字符 使用1個字節,中文字符大多用3個字節。
編碼轉換
有了Unicode之後,每一個字符就有了多種不兼容的編碼方式,比如說"馬"這個字符,它的各種編碼方式對應的16進制是:
GB18030 C2 ED Unicode編號 9A 6C UTF-8 E9 A9 AC UTF-16LE 6C 9A這幾種格式之間可以借助Unicode編號進行編碼轉換。可以簡化認為,每種編碼都有一個映射表,存儲其特有的字符編碼和Unicode編號之間的對應關系,這個映射表是一個簡化的說法,實際上可能是一個映射或轉換方法。
編碼轉換的具體過程可以是,比如說,一個字符從A編碼轉到B編碼,先找到字符的A編碼格式,通過A的映射表找到其Unicode編號,然後通過Unicode編號再查B的映射表,找到字符的B編碼格式。
舉例來說,"馬"從GB18030轉到UTF-8,先查GB18030->Unicode編號表,得到其編號是9A 6C,然後查Uncode編號->UTF-8表,得到其UTF-8編碼:E9 A9 AC。
與前文提到的切換查看編碼方式正好相反,編碼轉換改變了數據的二進制格式,但並沒有改變字符看上去的樣子。
再看亂碼
在前文中,我們提到亂碼出現的一個重要原因是解析二進制的方式不對,通過切換查看編碼的方式就可以解決亂碼。
但如果怎麼改變查看方式都不對的話,那很有可能就不僅僅是解析二進制的方式不對,而是文本在錯誤解析的基礎上還進行了編碼轉換。
我們舉個例子來說明:
這種情況是亂碼產生的主要原因。
這種情況其實很常見,計算機程序為了便於統一處理,經常會將所有編碼轉換為一種方式,比如UTF-8, 在轉換的時候,需要知道原來的編碼是什麼,但可能會搞錯,而一旦搞錯,並進行了轉換,就會出現這種亂碼。
這種情況下,無論怎麼切換查看編碼方式,都是不行的。
那有沒有辦法恢復呢?如果有,怎麼恢復呢?
----------------
未完待續,查看最新文章,敬請關注微信公眾號“老馬說編程”(掃描下方二維碼),深入淺出,老馬和你一起探索Java編程及計算機技術的本質。原創文章,保留所有版權。