從前我們的Java代碼因為一些原因使用了HashMap這個東西,但是當時的程序是單線程的,一切都沒有問題。後來,我們的程序性能有問題,所以需要變成多線程的,於是,變成多線程後到了線上,發現程序經常占了100%的CPU,查看堆棧,你會發現程序都Hang在了HashMap.get()這個方法上了,重啟程序後問題消失。但是過段時間又會來。而且,這個問題在測試環境裡可能很難重現。
我們簡單的看一下我們自己的代碼,我們就知道HashMap被多個線程操作。而Java的文檔說HashMap是非線程安全的,應該用ConcurrentHashMap。但是在這裡我們可以來研究一下原因。簡單代碼如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125package com.king.hashmap;
import java.util.HashMap;
public class TestLock {
private HashMap map = new HashMap();
public TestLock() {
Thread t1 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.put(new Integer(i), i);
}
System.out.println("t1 over");
}
};
Thread t2 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.put(new Integer(i), i);
}
System.out.println("t2 over");
}
};
Thread t3 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.put(new Integer(i), i);
}
System.out.println("t3 over");
}
};
Thread t4 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.put(new Integer(i), i);
}
System.out.println("t4 over");
}
};
Thread t5 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.put(new Integer(i), i);
}
System.out.println("t5 over");
}
};
Thread t6 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.get(new Integer(i));
}
System.out.println("t6 over");
}
};
Thread t7 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.get(new Integer(i));
}
System.out.println("t7 over");
}
};
Thread t8 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.get(new Integer(i));
}
System.out.println("t8 over");
}
};
Thread t9 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.get(new Integer(i));
}
System.out.println("t9 over");
}
};
Thread t10 = new Thread() {
public void run() {
for (int i = 0; i < 50000; i++) {
map.get(new Integer(i));
}
System.out.println("t10 over");
}
};
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
t7.start();
t8.start();
t9.start();
t10.start();
}
public static void main(String[] args) {
new TestLock();
}
}
就是啟了10個線程,不斷的往一個非線程安全的HashMap中put內容/get內容,put的內容很簡單,key和value都是從0自增的整數(這個put的內容做的並不好,以致於後來干擾了我分析問題的思路)。對HashMap做並發寫操作,我原以為只不過會產生髒數據的情況,但反復運行這個程序,會出現線程t1、t2被hang住的情況,多數情況下是一個線程被hang住另一個成功結束,偶爾會10個線程都被hang住。
產生這個死循環的根源在於對一個未保護的共享變量 — 一個”HashMap”數據結構的操作。當在所有操作的方法上加了”synchronized”後,一切恢復了正常。這算jvm的bug嗎?應該說不是的,這個現象很早以前就報告出來了。Sun的工程師並不認為這是bug,而是建議在這樣的場景下應采用”ConcurrentHashMap”,
CPU利用率過高一般是因為出現了出現了死循環,導致部分線程一直運行,占用cpu時間。問題原因就是HashMap是非線程安全的,多個線程put的時候造成了某個key值Entry key List的死循環,問題就這麼產生了。
當另外一個線程get 這個Entry List 死循環的key的時候,這個get也會一直執行。最後結果是越來越多的線程死循環,最後導致服務器dang掉。我們一般認為HashMap重復插入某個值的時候,會覆蓋之前的值,這個沒錯。但是對於多線程訪問的時候,由於其內部實現機制(在多線程環境且未作同步的情況下,對同一個HashMap做put操作可能導致兩個或以上線程同時做rehash動作,就可能導致循環鍵表出現,一旦出現線程將無法終止,持續占用CPU,導致CPU使用率居高不下),就可能出現安全問題了。
使用jstack工具dump出問題的那台服務器的棧信息。死循環的話,首先查找RUNNABLE的線程,找到問題代碼如下:
java.lang.Thread.State:RUNNABLE
at java.util.HashMap.get(HashMap.java:303)
at com.sohu.twap.service.logic.TransformTweeter.doTransformTweetT5(TransformTweeter.java:183)
共出現了23次。
java.lang.Thread.State:RUNNABLE
at java.util.HashMap.put(HashMap.java:374)
at com.sohu.twap.service.logic.TransformTweeter.transformT5(TransformTweeter.java:816)
共出現了3次。
注意:不合理使用HashMap導致出現的是死循環而不是死鎖。
主要問題出在addEntry方法的new Entry (hash, key, value, e),如果兩個線程都同時取得了e,則他們下一個元素都是e,然後賦值給table元素的時候有一個成功有一個丟失。
在transfer方法中代碼如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry e = src[j];
if (e != null) {
src[j] = null;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
在這個方法裡,將舊數組賦值給src,遍歷src,當src的元素非null時,就將src中的該元素置null,即將舊數組中的元素置null了,也就是這一句:
1 2if (e != null) {
src[j] = null;
此時若有get方法訪問這個key,它取得的還是舊數組,當然就取不到其對應的value了。
總結:HashMap未同步時在並發程序中會產生許多微妙的問題,難以從表層找到原因。所以使用HashMap出現了違反直覺的現象,那麼可能就是並發導致的了。
我需要簡單地說一下HashMap這個經典的數據結構。
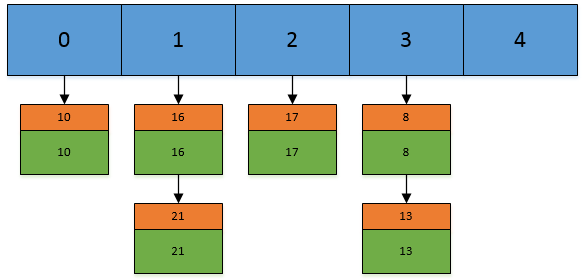
HashMap通常會用一個指針數組(假設為table[])來做分散所有的key,當一個key被加入時,會通過Hash算法通過key算出這個數組的下標i,然後就把這個 插到table[i]中,如果有兩個不同的key被算在了同一個i,那麼就叫沖突,又叫碰撞,這樣會在table[i]上形成一個鏈表。
我們知道,如果table[]的尺寸很小,比如只有2個,如果要放進10個keys的話,那麼碰撞非常頻繁,於是一個O(1)的查找算法,就變成了鏈表遍歷,性能變成了O(n),這是Hash表的缺陷。
所以,Hash表的尺寸和容量非常的重要。一般來說,Hash表這個容器當有數據要插入時,都會檢查容量有沒有超過設定的thredhold,如果超過,需要增大Hash表的尺寸,但是這樣一來,整個Hash表裡的元素都需要被重算一遍。這叫rehash,這個成本相當的大。
下面,我們來看一下Java的HashMap的源代碼。Put一個Key,Value對到Hash表中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果該key已被插入,則替換掉舊的value (鏈接操作)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//該key不存在,需要增加一個結點
addEntry(hash, key, value, i);
return null;
}
檢查容量是否超標:
1 2 3 4 5 6 7 8void addEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看當前的size是否超過了我們設定的阈值threshold,如果超過,需要resize
if (size++ >= threshold)
resize(2 * table.length);
}
新建一個更大尺寸的hash表,然後把數據從老的Hash表中遷移到新的Hash表中。
1 2 3 4 5 6 7 8 9 10 11 12void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//創建一個新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//將Old Hash Table上的數據遷移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
遷移的源代碼,注意高亮處:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面這段代碼的意思是:
// 從OldTable裡摘一個元素出來,然後放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
好了,這個代碼算是比較正常的。而且沒有什麼問題。
畫了個圖做了個演示。
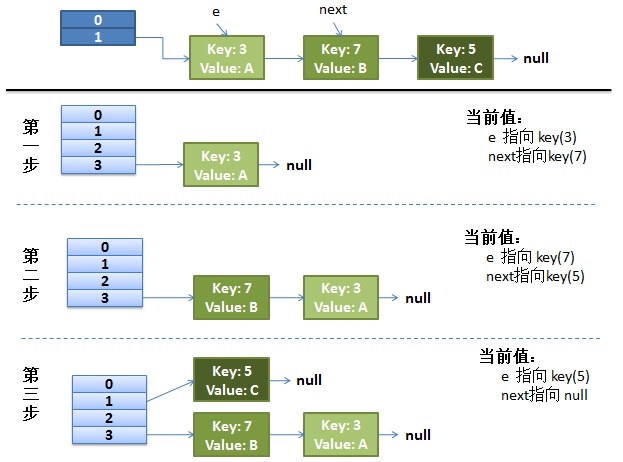
(1)假設我們有兩個線程。我用紅色和淺藍色標注了一下。我們再回頭看一下我們的 transfer代碼中的這個細節:
1 2 3 4 5 6 7do {
Entry<K,V> next = e.next; // <--假設線程一執行到這裡就被調度掛起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
而我們的線程二執行完成了。於是我們有下面的這個樣子。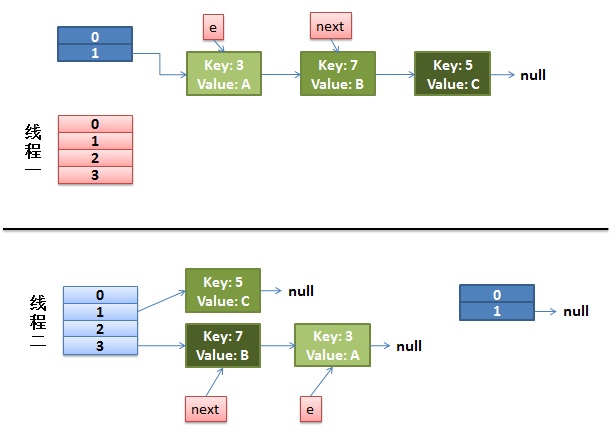
注意:因為Thread1的 e 指向了key(3),而next指向了key(7),其在線程二rehash後,指向了線程二重組後的鏈表。我們可以看到鏈表的順序被反轉後。
(2)線程一被調度回來執行。
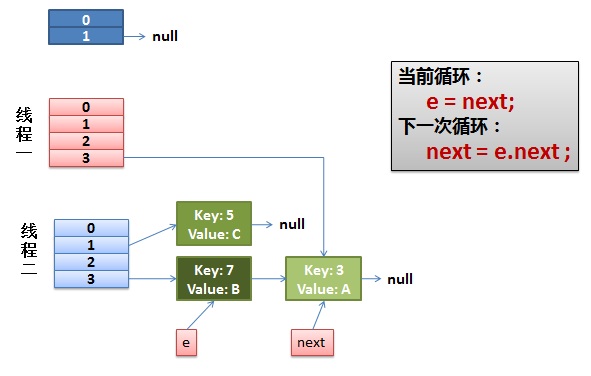
(3)一切安好。
線程一接著工作。把key(7)摘下來,放到newTable[i]的第一個,然後把e和next往下移。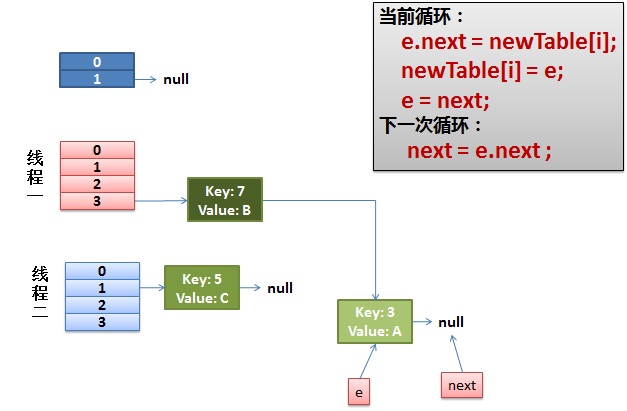
(4)環形鏈接出現。
e.next = newTable[i] 導致 key(3).next 指向了 key(7)。注意:此時的key(7).next 已經指向了key(3), 環形鏈表就這樣出現了。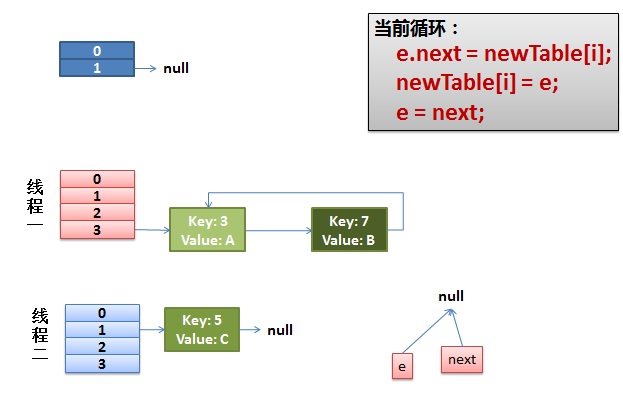
於是,當我們的線程一調用到,HashTable.get(11)時,悲劇就出現了——Infinite Loop。
Hashtable 是同步的,但由迭代器返回的 Iterator 和由所有 Hashtable 的“collection 視圖方法”返回的 Collection 的 listIterator 方法都是快速失敗的:在創建 Iterator 之後,如果從結構上對 Hashtable 進行修改,除非通過 Iterator 自身的移除或添加方法,否則在任何時間以任何方式對其進行修改,Iterator 都將拋出 ConcurrentModificationException。因此,面對並發的修改,Iterator 很快就會完全失敗,而不冒在將來某個不確定的時間發生任意不確定行為的風險。由 Hashtable 的鍵和值方法返回的 Enumeration 不是快速失敗的。
注意,迭代器的快速失敗行為無法得到保證,因為一般來說,不可能對是否出現不同步並發修改做出任何硬性保證。快速失敗迭代器會盡最大努力拋出 ConcurrentModificationException。因此,為提高這類迭代器的正確性而編寫一個依賴於此異常的程序是錯誤做法:迭代器的快速失敗行為應該僅用於檢測程序錯誤。
返回由指定映射支持的同步(線程安全的)映射。為了保證按順序訪問,必須通過返回的映射完成對底層映射的所有訪問。在返回的映射或其任意 collection 視圖上進行迭代時,強制用戶手工在返回的映射上進行同步:
1 2 3 4 5 6 7 8 9Map m = Collections.synchronizedMap(new HashMap());
...
Set s = m.keySet(); // Needn't be in synchronized block
...
synchronized(m) { // Synchronizing on m, not s!
Iterator i = s.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}
不遵從此建議將導致無法確定的行為。如果指定映射是可序列化的,則返回的映射也將是可序列化的。
支持檢索的完全並發和更新的所期望可調整並發的哈希表。此類遵守與 Hashtable 相同的功能規范,並且包括對應於 Hashtable 的每個方法的方法版本。不過,盡管所有操作都是線程安全的,但檢索操作不必鎖定,並且不支持以某種防止所有訪問的方式鎖定整個表。此類可以通過程序完全與 Hashtable 進行互操作,這取決於其線程安全,而與其同步細節無關。
檢索操作(包括 get)通常不會受阻塞,因此,可能與更新操作交迭(包括 put 和 remove)。檢索會影響最近完成的更新操作的結果。對於一些聚合操作,比如 putAll 和 clear,並發檢索可能只影響某些條目的插入和移除。類似地,在創建迭代器/枚舉時或自此之後,Iterators 和 Enumerations 返回在某一時間點上影響哈希表狀態的元素。它們不會拋出 ConcurrentModificationException。不過,迭代器被設計成每次僅由一個線程使用。
QQ技術交流群290551701 http://cxy.liuzhihengseo.com/539.html