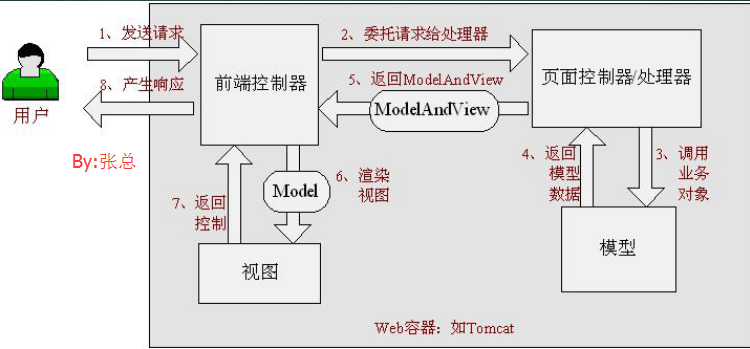
JDK(Java Development Kit)
是Java開發工具包,是Sun Microsystems針對Java開發員的產品。
JDK中包含JRE,在JDK的安裝目錄下有一個名為jre的目錄,裡面有兩個文件夾bin和lib,在這裡可以認為bin裡的就是jvm,lib中則是jvm工作所需要的類庫,而jvm和 lib和起來就稱為jre。
JDK是整個JAVA的核心,包括了Java運行環境JRE(Java Runtime Envirnment)、一堆Java工具(javac/java/jdb等)和Java基礎的類庫(即Java API 包括rt.jar)。
①SE(J2SE),standard edition,標准版,是我們通常用的一個版本,從JDK 5.0開始,改名為Java SE。
②EE(J2EE),enterprise edition,企業版,使用這種JDK開發J2EE應用程序,從JDK 5.0開始,改名為Java EE。
③ME(J2ME),micro edition,主要用於移動設備、嵌入式設備上的java應用程序,從JDK 5.0開始,改名為Java ME。
JDK=JRE+JVM+其它 運行Java程序一般都要求用戶的電腦安裝JRE環境(Java Runtime Environment);沒有jre,java程序無法運行;而沒有java程序,jre就沒有用武之地。
JRE(Java Runtime Environment)
是java程序的運行環境,面向Java程序的使用者,而不是開發者。
JRE是運行Java程序所必須環境的集合,包含JVM標准實現及Java核心類庫。它包括Java虛擬機、Java平台核心類和支持文件。以windows機器上來看,虛擬機文件就是
CLASSPATH環境變量保存的是一些目錄和jar文件的地址,這些路徑是為了java程序在編譯和運行時搜索類而用的;其寫法與path變量是一致的,前後用分號分開,如果是jar文件,那麼寫明jar文件的絕對路徑。
JDK中的java 和 javac命令提供了“-cp”或著“-classpath”選項為java程序動態的指定類搜索路徑,它們的使用方法非常簡單,只需要把相應的文件目錄或jar文件路徑跟在相應的選項後即可,如下:
javac -cp D:\java\work\log4j.jar HelloWorld.java
java -cp D:\java\work\log4j.jar HelloWorld
或者
javac -classpath D:\java\work\log4j.jar HelloWorld.java
java -classpath D:\java\work\log4j.jar HelloWorld
jar文件是Java程序打包以後的格式文件,它一般保存的有class文件、配置文件、mainifest.mf文件。jar文件的主要意圖就是方便程序的發布和部署,JDK提供了一個jar工具命令,可以用它來對java程序進行打包。
jar {c t x u f} {v m e 0 M i} {-C 目錄} 文件名...
eg:
jar cf hello.jar HelloWorld.class
其中{c t x u}這四個參數必須選一個,文件名也是必須的,{v m e 0 M i}是可選的。
-c: 創建一個jar包 -t: 顯示jar包中的內容列表 -x: 解壓jar包 -u: 添加文件到jar包 -f: 指定jar包的文件名 -v: 生成詳細的報告並輸出至標准設備 -m: 指定mainifest.mf文件,mainifest.mf文件可以對jar包及其內容做一些設置 -e: -0: 產生jar包時不對其中的內容做壓縮處理 -M: 不產生所有文件的清單文件,並會忽略掉-m的設置 -i: 為指定的jar文件創建索引文件 -C: 表示先轉到相應的目錄下再執行jar命令“static”關鍵字表明一個成員變量或者是成員方法可以在沒有所屬的類的實例變量的情況下被訪問。Java中static方法不能被覆蓋,因為方法覆蓋是基於運行時動態綁定的,而static方法是編譯時靜態綁定的。static方法跟類的任何實例都不相關,所以概念上不適用。
static變量在Java中是屬於類的,它在所有的實例中的值是一樣的。當類被Java虛擬機載入的時候,會對static變量進行初始化。如果你的代碼嘗試不用實例來訪問非static的變量,編譯器會報錯,因為這些變量還沒有被創建出來,還沒有跟任何實例關聯上。
Java語言支持的8中基本數據類型是:
byte short int long float double boolean char自動裝箱是Java編譯器在基本數據類型和對應的對象包裝類型之間做的一個轉化。比如:把int轉化成Integer,double轉化成double,等等。反之就是自動拆箱。
Java中的方法重載發生在同一個類裡面兩個或者是多個方法的方法名相同但是參數不同的情況。與此相對,方法覆蓋是說子類重新定義了父類的方法。方法覆蓋必須有相同的方法名,參數列表和返回類型。覆蓋者可能不會限制它所覆蓋的方法的訪問。
當新對象被創建的時候,構造函數會被調用。每一個類都有構造函數。在程序員沒有給類提供構造函數的情況下,Java編譯器會為這個類創建一個默認的構造函數。
Java中構造函數重載和方法重載很相似。可以為一個類創建多個構造函數。每一個構造函數必須有它自己唯一的參數列表。
Java不支持像C++中那樣的復制構造函數,這個不同點是因為如果你不自己寫構造函數的情況下,Java不會創建默認的復制構造函數。
不支持,Java不支持多繼承。每個類都只能繼承一個類,但是可以實現多個接口。
進程是執行著的應用程序,而線程是進程內部的一個執行序列。一個進程可以有多個線程。線程又叫做輕量級進程。
有三種方式可以用來創建線程:
繼承Thread類 實現Runnable接口 應用程序可以使用Executor框架來創建線程池實現Runnable接口這種方式更受歡迎,因為這不需要繼承Thread類。在應用設計中已經繼承了別的對象的情況下,這需要多繼承(而Java不支持多繼承),只能實現接口。同時,線程池也是非常高效的,很容易實現和使用。
線程在執行過程中,可以處於下面幾種狀態:
就緒(Runnable):線程准備運行,不一定立馬就能開始執行。 運行中(Running):進程正在執行線程的代碼。 等待中(Waiting):線程處於阻塞的狀態,等待外部的處理結束。 睡眠中(Sleeping):線程被強制睡眠。 I/O阻塞(Blocked on I/O):等待I/O操作完成。 同步阻塞(Blocked on Synchronization):等待獲取鎖。 死亡(Dead):線程完成了執行。在Java語言中,每一個對象有一把鎖。線程可以使用synchronized關鍵字來獲取對象上的鎖。synchronized關鍵字可應用在方法級別(粗粒度鎖)或者是代碼塊級別(細粒度鎖)。
監視器和鎖在Java虛擬機中是一塊使用的。監視器監視一塊同步代碼塊,確保一次只有一個線程執行同步代碼塊。每一個監視器都和一個對象引用相關聯。線程在獲取鎖之前不允許執行同步代碼。
使用多線程的時候,一種非常簡單的避免死鎖的方式就是:指定獲取鎖的順序,並強制線程按照指定的順序獲取鎖。因此,如果所有的線程都是以同樣的順序加鎖和釋放鎖,就不會出現死鎖了。
Java集合類提供了一套設計良好的支持對一組對象進行操作的接口和類。Java集合類裡面最基本的接口有:
Collection:代表一組對象,每一個對象都是它的子元素。 Set:不包含重復元素的Collection。 List:有順序的collection,並且可以包含重復元素。 Map:可以把鍵(key)映射到值(value)的對象,鍵不能重復。集合類接口指定了一組叫做元素的對象。集合類接口的每一種具體的實現類都可以選擇以它自己的方式對元素進行保存和排序。有的集合類允許重復的鍵,有些不允許。
Iterator接口提供了很多對集合元素進行迭代的方法。每一個集合類都包含了可以返回迭代器實例的迭代方法。迭代器可以在迭代的過程中刪除底層集合的元素。
下面列出了他們的區別:
Iterator可用來遍歷Set和List集合,但是ListIterator只能用來遍歷List。 Iterator對集合只能是前向遍歷,ListIterator既可以前向也可以後向。 ListIterator實現了Iterator接口,並包含其他的功能,比如:增加元素,替換元素,獲取前一個和後一個元素的索引,等等。Iterator的安全失敗是基於對底層集合做拷貝,因此,它不受源集合上修改的影響。java.util包下面的所有的集合類都是快速失敗的,而java.util.concurrent包下面的所有的類都是安全失敗的。快速失敗的迭代器會拋出ConcurrentModificationException異常,而安全失敗的迭代器永遠不會拋出這樣的異常。
Java中的HashMap是以鍵值對(key-value)的形式存儲元素的。HashMap需要一個hash函數,它使用hashCode()和equals()方法來向集合/從集合添加和檢索元素。當調用put()方法的時候,HashMap會計算key的hash值,然後把鍵值對存儲在集合中合適的索引上。如果key已經存在了,value會被更新成新值。HashMap的一些重要的特性是它的容量(capacity),負載因子(load factor)和擴容極限(threshold resizing)。
Java中的HashMap使用hashCode()和equals()方法來確定鍵值對的索引,當根據鍵獲取值的時候也會用到這兩個方法。如果沒有正確的實現這兩個方法,兩個不同的鍵可能會有相同的hash值,因此,可能會被集合認為是相等的。而且,這兩個方法也用來發現重復元素。所以這兩個方法的實現對HashMap的精確性和正確性是至關重要的。
HashMap和Hashtable都實現了Map接口,因此很多特性非常相似。但是,他們有以下不同點:
HashMap允許鍵和值是null,而Hashtable不允許鍵或者值是null。 Hashtable是同步的,而HashMap不是。因此,HashMap更適合於單線程環境,而Hashtable適合於多線程環境。 HashMap提供了可供應用迭代的鍵的集合,因此,HashMap是快速失敗的。另一方面,Hashtable提供了對鍵的列舉(Enumeration)。 一般認為Hashtable是一個遺留的類。下面列出了Array和ArrayList的不同點:
Array可以包含基本類型和對象類型,ArrayList只能包含對象類型。 Array大小是固定的,ArrayList的大小是動態變化的。 ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。 對於基本類型數據,集合使用自動裝箱來減少編碼工作量。但是,當處理固定大小的基本數據類型的時候,這種方式相對比較慢。ArrayList和LinkedList都實現了List接口,他們有以下的不同點:
ArrayList是基於索引的數據接口,它的底層是數組。它可以以O(1)時間復雜度對元素進行隨機訪問。與此對應,LinkedList是以元素列表的形式存儲它的數據,每一個元素都和它的前一個和後一個元素鏈接在一起,在這種情況下,查找某個元素的時間復雜度是O(n)。 相對於ArrayList,LinkedList的插入,添加,刪除操作速度更快,因為當元素被添加到集合任意位置的時候,不需要像數組那樣重新計算大小或者是更新索引。 LinkedList比ArrayList更占內存,因為LinkedList為每一個節點存儲了兩個引用,一個指向前一個元素,一個指向下一個元素。Java提供了只包含一個compareTo()方法的Comparable接口。這個方法可以個給兩個對象排序。具體來說,它返回負數,0,正數來表明輸入對象小於,等於,大於已經存在的對象。Java提供了包含compare()和equals()兩個方法的Comparator接口。compare()方法用來給兩個輸入參數排序,返回負數,0,正數表明第一個參數是小於,等於,大於第二個參數。equals()方法需要一個對象作為參數,它用來決定輸入參數是否和comparator相等。只有當輸入參數也是一個comparator並且輸入參數和當前comparator的排序結果是相同的時候,這個方法才返回true。
PriorityQueue是一個基於優先級堆的無界隊列,它的元素是按照自然順序(natural order)排序的。在創建的時候,我們可以給它提供一個負責給元素排序的比較器。PriorityQueue不允許null值,因為他們沒有自然順序,或者說他們沒有任何的相關聯的比較器。最後,PriorityQueue不是線程安全的,入隊和出隊的時間復雜度是O(log(n))。
大O符號描述了當數據結構裡面的元素增加的時候,算法的規模或者是性能在最壞的場景下有多麼好。大O符號也可用來描述其他的行為,比如:內存消耗。因為集合類實際上是數據結構,我們一般使用大O符號基於時間,內存和性能來選擇最好的實現。大O符號可以對大量數據的性能給出一個很好的說明。
有序數組最大的好處在於查找的時間復雜度是O(log n),而無序數組是O(n)。有序數組的缺點是插入操作的時間復雜度是O(n),因為值大的元素需要往後移動來給新元素騰位置。相反,無序數組的插入時間復雜度是常量O(1)。
根據應用的需要正確選擇要使用的集合的類型對性能非常重要,比如:假如元素的大小是固定的,而且能事先知道,我們就應該用Array而不是ArrayList。
有些集合類允許指定初始容量。因此,如果我們能估計出存儲的元素的數目,我們可以設置初始容量來避免重新計算hash值或者是擴容。 為了類型安全,可讀性和健壯性的原因總是要使用泛型。同時,使用泛型還可以避免運行時的ClassCastException。 使用JDK提供的不變類(immutable class)作為Map的鍵可以避免為我們自己的類實hash-Code()和equals()方法。 編程的時候接口優於實現。 底層的集合實際上是空的情況下,返回長度是0的集合或者是數組,不要返回null。Enumeration速度是Iterator的2倍,同時占用更少的內存。但是,Iterator遠遠比Enumeration安全,因為其他線程不能夠修改正在被iterator遍歷的集合裡面的對象。同時,Iterator允許調用者刪除底層集合裡面的元素,這對Enumeration來說是不可能的。
垃圾回收的目的是識別並且丟棄應用不再使用的對象來釋放和重用資源。
這兩個方法用來提示JVM要進行垃圾回收。但是,立即開始還是延遲進行垃圾回收是取決於JVM的。
在釋放對象占用的內存之前,垃圾收集器會調用對象的finalize()方法。一般建議在該方法中釋放對象持有的資源。
不會,在下一個垃圾回收周期中,這個對象將是可被回收的。
JVM的堆是運行時數據區,所有類的實例和數組都是在堆上分配內存。它在JVM啟動的時候被創建。對象所占的堆內存是由自動內存管理系統也就是垃圾收集器回收。
堆內存是由存活和死亡的對象組成的。存活的對象是應用可以訪問的,不會被垃圾回收。死亡的對象是應用不可訪問尚且還沒有被垃圾收集器回收掉的對象。一直到垃圾收集器把這些對象回收掉之前,他們會一直占據堆內存空間。
吞吐量收集器使用並行版本的新生代垃圾收集器,它用於中等規模和大規模數據的應用程序。而串行收集器對大多數的小應用(在現代處理器上需要大概100M左右的內存)就足夠了。
當對象對當前使用這個對象的應用程序變得不可觸及的時候,這個對象就可以被回收了。
垃圾回收不會發生在永久代,如果永久代滿了或者是超過了臨界值,會觸發完全垃圾回收(Full GC)。如果你仔細查看垃圾收集器的輸出信息,就會發現永久代也是被回收的。這就是為什麼正確的永久代大小對避免Full GC是非常重要的原因。