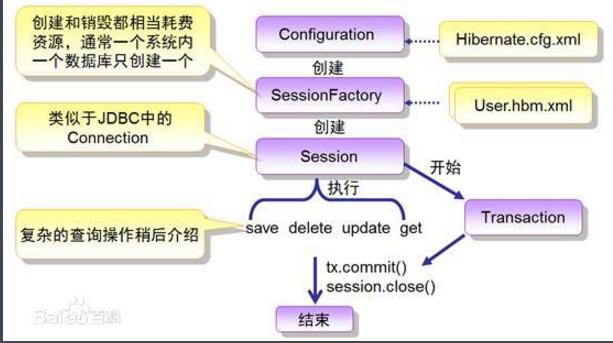
公眾號HelloJava刊出一篇《MySQL Statement cancellation timer 故障排查分享》,作者的某服務的線上機器報 502(502是 nginx 做後端健康檢查時不能連接到 server 時拋出的提示),他用 jstack -l 打印線程堆棧,發現了大量可疑的“MySQL Statementcancellation timer”,進一步探究原因,原來是業務應用將數據庫更新操作和雲存儲傳圖操作放在同一個事務。當雲存儲發生異常時,由於缺少雲存儲操作的快速失敗,並且缺少對整體事務的超時控制,導致整個應用被夯住,進而 502。
作者文中還談及他排查過程中注意到 MySQL-Connector-Java 的一個 bug,在 5.1.27 版本以前 MySQL Statement cancellation timer 會導致 Perm 區 Leak,內存洩漏後進而業務應用異常。
我們恰巧遇到過這個坑。鑒於這個坑的排查過程和測試驗證還挺有趣,我貼一下去年我們的 RCA 報告:
RCA:JDBC驅動自身問題引發的FullGC
鄭昀 基於田志全和端木洪濤的分析報告 2015/6/30
關鍵詞:Java,JDBC,升級,MySQL驅動,頻繁數據查詢,mysql-5.1.34,mysql-5.0.7

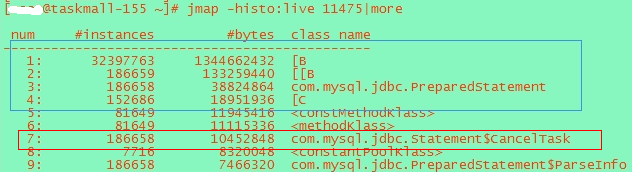
 圖2 155 jmap
圖2 155 jmap
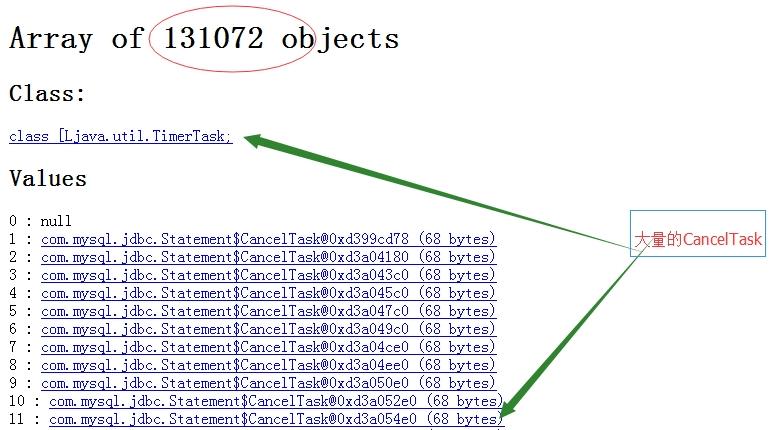
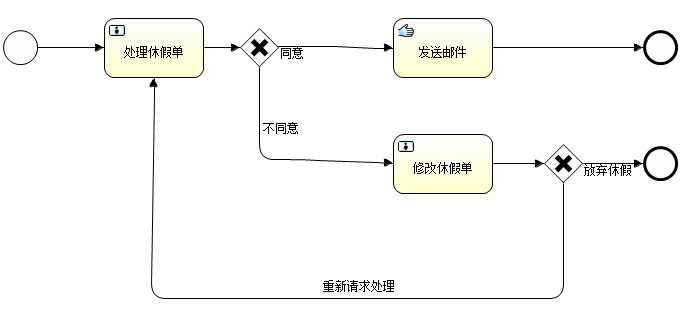
 圖3 大量的CancelTask
為什麼會有這麼多的任務呢?
這是 mysql 的一個定時任務,主要用於查詢超時處理。即,系統在執行一個 sql 查詢時,jdbc 會給你一個超時時間。為了保證超時時間後,能夠關閉 statement,會打開一個保護關閉的定時任務。如果超時情況下,sql 還沒響應執行,cancel task 就會執行關閉任務。注,ibatis 的默認超時時間為3秒(<setting name="defaultStatementTimeout" value="3000" />)。
圖3 大量的CancelTask
為什麼會有這麼多的任務呢?
這是 mysql 的一個定時任務,主要用於查詢超時處理。即,系統在執行一個 sql 查詢時,jdbc 會給你一個超時時間。為了保證超時時間後,能夠關閉 statement,會打開一個保護關閉的定時任務。如果超時情況下,sql 還沒響應執行,cancel task 就會執行關閉任務。注,ibatis 的默認超時時間為3秒(<setting name="defaultStatementTimeout" value="3000" />)。
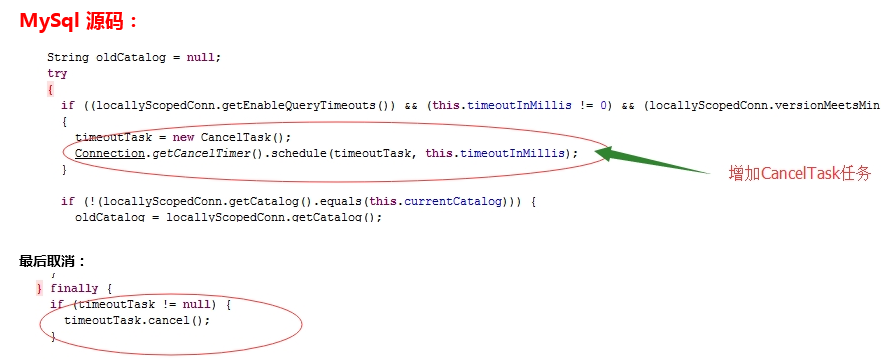
 圖4 mysql源碼
其實,cancel() 方法只是對狀態做了一個標記而已:
圖4 mysql源碼
其實,cancel() 方法只是對狀態做了一個標記而已:
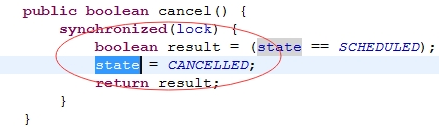
 圖5 mysql源碼
只有在調度任務時,發現狀態為取消,才會真正移除該任務:
圖5 mysql源碼
只有在調度任務時,發現狀態為取消,才會真正移除該任務:
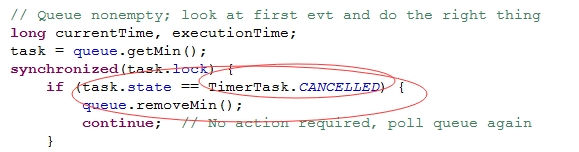
 圖6 mysql源碼
於是,在某些情況下,CancelTask 會大量累積,從而嚴重影響 JVM 內存,最終引發 FullGC!
圖6 mysql源碼
於是,在某些情況下,CancelTask 會大量累積,從而嚴重影響 JVM 內存,最終引發 FullGC!
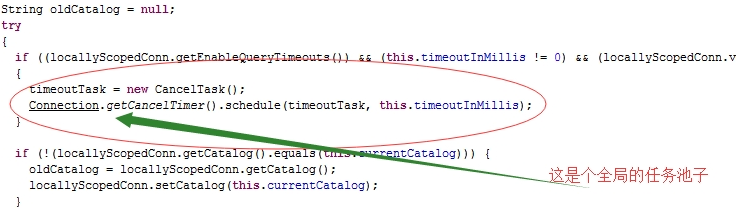
 圖7 mysql源碼
而在 mysql-connector-java-5.1.34-bin.jar 中:
圖7 mysql源碼
而在 mysql-connector-java-5.1.34-bin.jar 中:
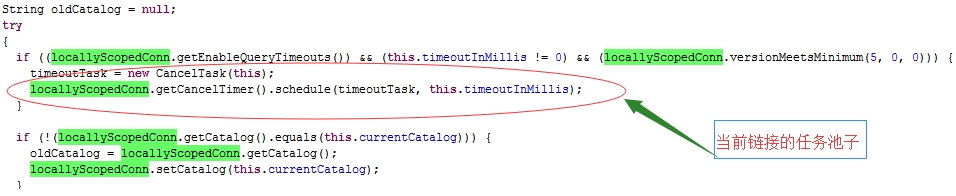
 圖8 mysql源碼
端木洪濤經過針對性的壓力測試,確實證實了這個現象可以重現。測試報告如下所示:
圖8 mysql源碼
端木洪濤經過針對性的壓力測試,確實證實了這個現象可以重現。測試報告如下所示:
測試時間:2015年4月29日
使用taskmall聯調環境做測試。
協調器:10.8.210.168
分發器:10.9.210.151、10.9.210.152
執行器:10.9.210.154
分發器配置如下:
151使用mysql-5.1.34驅動,152使用mysql-5.0.7驅動。其中分發器兩機器為2核8G配置,統一resin4 JVM配置:
<jvm-arg>-Xmx1024M</jvm-arg>
<jvm-arg>-Xms1024M</jvm-arg>
<jvm-arg>-Xmn512M</jvm-arg>
<jvm-arg>-XX:SurvivorRatio=6</jvm-arg>
<jvm-arg>-Xss1024k</jvm-arg>
<jvm-arg>-XX:PermSize=256M</jvm-arg>
<jvm-arg>-XX:MaxPermSize=256M</jvm-arg>
基礎准備:
1、往數據庫中壓入5180條隊列數據,(其中151機器分的2614條,152機器分得2566條);
2、改造執行器,使其只接受數據不處理數據。則5180條數據對分發器來說一直都是有效數據;
3、改造分發器,設置ibatis參數:cacheModelsEnabled="true"、defaultStatementTimeout="3000"。每150ms加載一次數據;
(分發器起16個線程對應16個cobar分庫,每個線程分頁加載分庫中的有效數據,每頁200條數據。)
4、jvisualvm遠程監控151、152機器。
測試結果如下:
一、15分鐘後監控結果如下
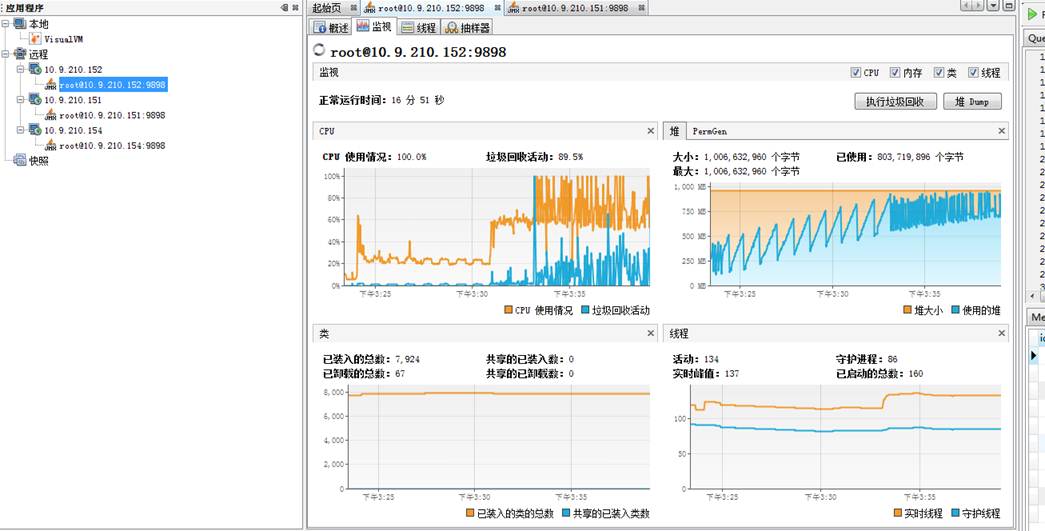
從圖上看出152機器從cpu占用、堆大小在逐漸升高,查看gc日志發現152已經開始出現FullGC。
152機器已快掛:
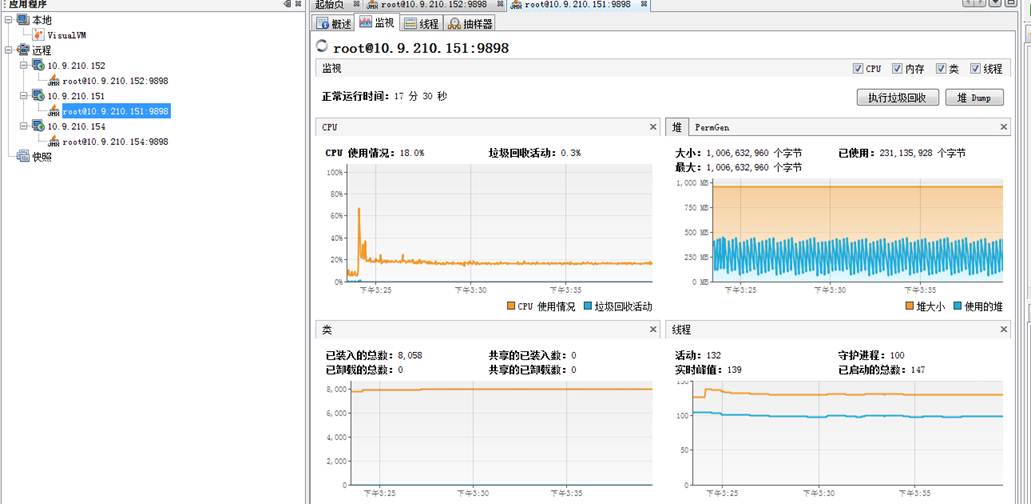
151機器則一切正常:
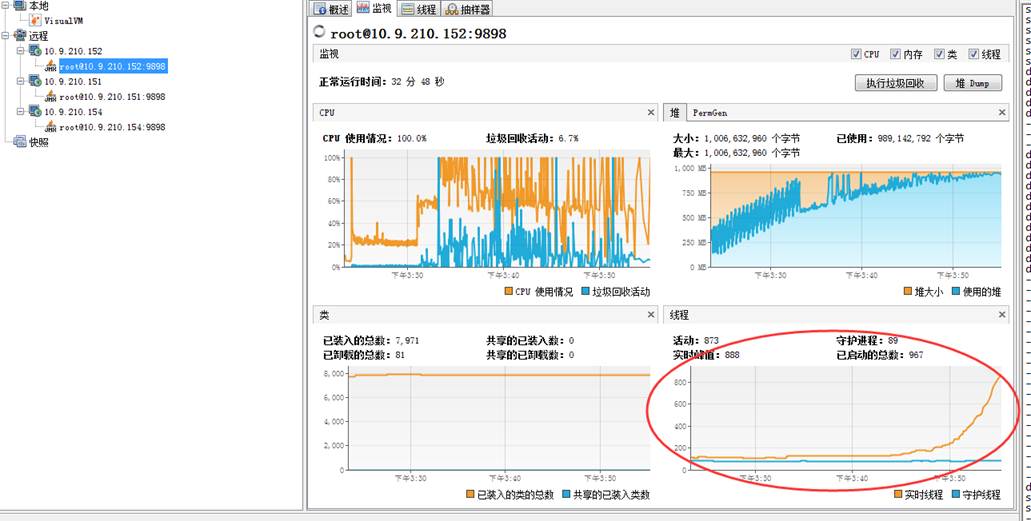
二、32分鐘後監控結果如下
此時除了cpu占用、堆飙高外,152的線程數也遠遠高於151。此時的152已經頻繁FullGC了。
152機器:
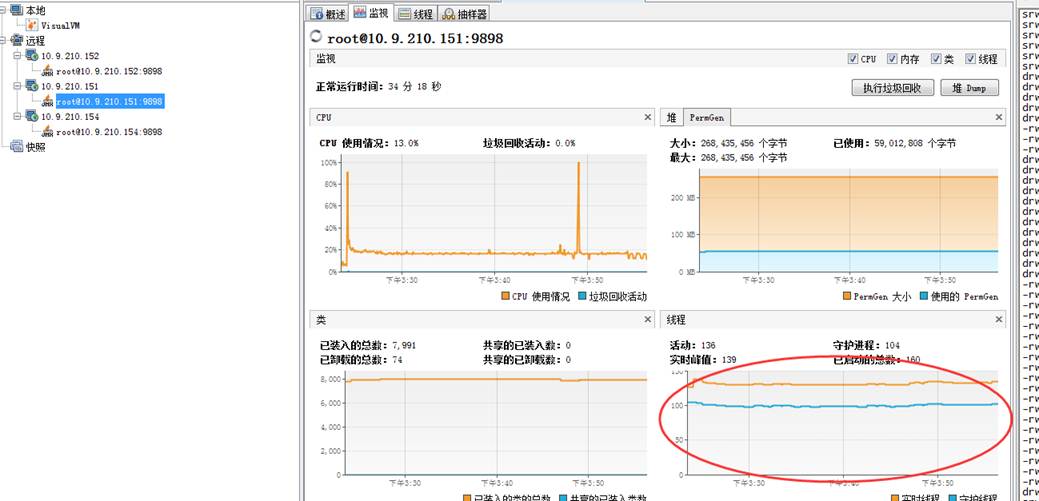
151機器則:
統計堆內存中活著對象數據:
152機器出現大量的Byte數據以及PreparedStatement,以及CancelTask。
1)但是在151機器上前47位的占用排行上找不到CancelTask。
2)在byte數據量上,152機器達到了600M,而151機器只有幾十M。
測試結論:
頻繁的大數據查詢場景下,mysql-5.1.34 驅動的性能處理遠優於 mysql-5.0.7 驅動。
-EOF- 歡迎訂閱我的微信訂閱號『老兵筆記』,請掃描二維碼關注: 轉載時請注明“轉載自旁觀者-博客園”或者給出本文的原始鏈接。
轉載時請注明“轉載自旁觀者-博客園”或者給出本文的原始鏈接。