HashMap對於做Java的小伙伴來說太熟悉了。估計你們每天都在使用它。它為什麼叫做HashMap?它的內部是怎麼實現的呢?為什麼我們使用的時候很多情況都是用String作為它的key呢?帶著這些疑問讓我們來了解HashMap!
HashMap是一個用”KEY”-“VALUE”來實現數據存儲的類。你可以用一個”key”去存儲數據。當你想獲得數據的時候,你可以通過”key”去得到數據。所以你可以把HashMap當作一個字典。 那麼HashMap的名字從何而來呢?其實HashMap的由來是基於Hasing技術(Hasing),Hasing就是將很大的字符串或者任何對象轉換成一個用來代表它們的很小的值,這些更短的值就可以很方便的用來方便索引、加快搜索。
在講解HashMap的存儲過程之前還需要提到一個知識點
我們都知道在Java中每個對象都有一個hashcode()方法用來返回該對象的 hash值。HashMap中將會用到對象的hashcode方法來獲取對象的hash值。
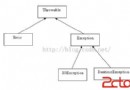
圖1展示了HashMap的類結構關系。
HashMap繼承了AbstractMap,並且支持序列化和反序列化。由於實現了Clonable接口,也就支持clone()方法來復制一個對象。今天主要說HashMap的內部實現,這裡就不對序列化和clone做講解了。
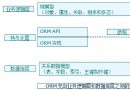
上面的圖很清晰的說明了HashMap內部的實現原理。就好比一個籃子,籃子裡裝了很多蘋果,蘋果裡包含了自己的信息和另外一個蘋果的引用
1、和上圖顯示的一樣,HashMap內部包含了一個Entry類型的數組table, table裡的每一個數據都是一個Entry對象。
2、再來看table裡面存儲的Entry類型,Entry類裡包含了hashcode變量,key,value 和另外一個Entry對象。為什麼要有一個Entry對象呢?其實如果你看過linkedList的源碼,你可能會知道這就是一個鏈表結構。通過我找到你,你再找到他。不過這裡的Entry並不是LinkedList,它是單獨為HashMap服務的一個內部單鏈表結構的類。
3、那麼Entry是一個單鏈表結構的意義又是什麼呢?在我們了解了HashMap的存儲過程之後,你就會很清楚了,接著讓我們來看HashMap怎麼工作的。
下面分析一段代碼的HashMap存儲過程。(這裡只是作為演示的例子,並沒有真實的去取到了Hash值,如果你有需要可以通過Debug來得到key的Hash值)
HashMap hashMap = new HashMap();//line1
hashMap.put("one","hello1");//line2
hashMap.put("two","hello2");//line3
hashMap.put("three","hello3");//line4
hashMap.put("four","hello4");//line5
hashMap.put("five","hello5");//line6
hashMap.put("six","hello6");//line7
hashMap.put("seven","hello7");//line8
put操作的偽代碼可以表示如下:
public V put(K key, V value){
int hash = hash(key);
int i = indexFor(hash, table.length);
//在table[i]的地方添加一個包含hash,key,value信息的Entry類。
}
下面我們來看上面代碼的過程
1、line1創建了一個HashMap,所以我們來看構造函數
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}空構造函數調用了它自己的另一個構造函數,注釋說明了構建了一個初始容量的空HashMap,那我們就來看它另外一個構造函數。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
void init() {
}
上面的代碼只是簡單的給loadFactor(其實是數組不夠用來擴容的)和threshold(內部數組的初始化容量),init()是一個空方法。所以現在數組table還是一個空數組。
/**
* An empty table instance to share when the table is not inflated.
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
2、接下來到了line2的地方, hashMap.put(“one”,”hello1”);在這裡先提一下put方法源碼:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);//如果是空的,加載
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);獲取hash值
int i = indexFor(hash, table.length);生成索引
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//遍歷已存在的Entry,如果要存入的key和hash值都一樣就覆蓋。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//添加一個節點
addEntry(hash, key, value, i);
return null;
}
源碼很簡單,先判斷table如果是空的,就初始化數組table,接著如果key是null就單獨處理。否則的話就得到key的hash值再生成索引,這裡用了indexFor()方法生成索引是因為:hash值一般都很大,是不適合我們的數組的。來看indexFor方法
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}就是一個&操作,這樣返回的值比較小適合我們的數組。
繼續 line2put操作,因為開始table是空數組,所以會進入 inflateTable(threshold)方法,其實這個方法就是出實話數組容量,初始化長度是16,這個長度是在開始的構造方法賦值的。
所以,現在空數組變成了長度16的數組了,就像下圖一樣。
接著由於我們的key不為null,到了獲取hash值和索引,這裡假設int hash = hash(key)和int i = indexFor(hash, table.length)生成的索引i為hash=2306996,i = 4;那麼就會在table索引為4的位置新建一個Entry,對應的代碼是addEntry(hash, key, value, i);到此結果如下圖:
新建的Entry內部的變量分別是,hash,key,value,和指向下一節點的next Entry。
3、繼續來看line3,line3和line2一樣,而且數組不為空直接hash(key)和index。所以直接看圖了
4、到了line4,這裡line4情況有點特殊,我們假設line4裡key生成的hashcode產生的index也為4,比如hash(“three”) 的值 63281940
hash&(15)產生的index為4。這種情況由於之前的位置已經有Entry了,所以遍歷Entry如果key和hashcode都相同,就直接替換,否則新添加一個Entry,來看一下對應源碼
public V put(K key, V value) {
...//一些代碼
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//for循環裡判斷如果hash和key都一樣直接替換。
modCount++;
addEntry(hash, key, value, i);//沒有重復的話就addEntry
return null;
}
上面代碼先判斷是否需要替換,不需要就調用了addEntry方法。來看addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}//判斷數組容量是否足夠,不足夠擴容
createEntry(hash, key, value, bucketIndex);
}
裡面又調用了createEntry
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
//獲取當前節點,然後新建一個含有當前hash,key,value信息的一個節點,並且該節點的Entry指向了前一個Entry並賦值給table[index],成為了最新的節點Entry,同時將size加1。
}
到這裡相信大家很清楚了。來看看圖:
5、到這裡之後的代碼都在上面的分析情況當中。我就不一一畫圖了,直接給出程序執行到最後的圖
line5到line8
結果圖如下:
到此put 操作就結束了,再來看看取
我們通過hashMap.get(K key) 來獲取存入的值,key的取值很簡單了。我們通過數組的index直接找到Entry,然後再遍歷Entry,當hashcode和key都一樣就是我們當初存入的值啦。看源碼:
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
調用getEntry(key)拿到entry ,然後返回entry的value,來看getEntry(key)方法
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
按什麼規則存的就按什麼規則取,獲取到hash,再獲取index,然後拿到Entry遍歷,hash相等的情況下,如果key相等就知道了我們想要的值。
再get方法中有null的判斷,null取hash值總是0,再getNullKey(K key)方法中,也是按照遍歷方法來查找的。
到這你肯定明白了為什麼HashMap可以用null做key。
了解的存儲取值過程和內部實現,其它的方法自己看看源碼很好理解,在此就不一一解釋了。
問題1、HashMap是基於key的hashcode的存儲的,如果兩個不同的key產生的hashcode一樣取值怎麼辦?
看了上面的分析,你肯定知道,再數組裡面有鏈表結構的Entry來實現,通過遍歷所有的Entry,比較key來確定到底是哪一個value;
問題2、HashMap是基於key的hashcode的存儲的,如果兩個key一樣產生的hashcode一樣怎麼辦?
在put操作的時候會遍歷所有Entry,如果有key相等的則替換。所以get的時候只會有一個
問題3、我們總是習慣用一個String作為HashMap的key,這是為什麼呢?其它的類可以做為HashMap的key嗎?
這裡因為String是不可以變的,並且java為它實現了hashcode的緩存技術。我們在put和get中都需要獲取key的hashcode,這些方法的效率很大程度上取決於獲取hashcode的,所以用String的原因:1、它是不可變的。2、它實現了hashcode的緩存,效率更高。如果你對String不了解可以看:Java你可能不知道的事-String
問題4、可變的對象能作為HashMap的key嗎?
可變的對象是可以當做HashMap的key的,只是你要確保你可變變量的改變不會改變hashcode。比如以下代碼
public class TestMemory {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
TestKey testKey = new TestKey();
testKey.setAddress("sdfdsf");//line3
hashMap.put(testKey,"hello");
testKey.setAddress("sdfsdffds");//line5
System.out.println(hashMap.get(testKey));
}
}
public class TestKey {
String name;
String address;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public int hashCode() {
if (name==null){
return 0;
}
return name.hashCode();
}
}
上面的代碼line3到line5對象裡的address做了改變,但是由於hashCode是基於name來生成的,name沒變,所以依然能夠正常找到value。但是如果把setAdress換成name,get就會返回null。這就是為什麼我們選擇String的原因。
到這裡相信你對HashMap內部已經非常清楚了,如果本篇文章對你有幫助記得點贊和評論,或者關注我,我會繼續更新文章,感謝支持!