JDK提供了一組主要的數據結構的實現,如List、Set、Map等常用結構,這些結構都繼承自java.util.collection接口。
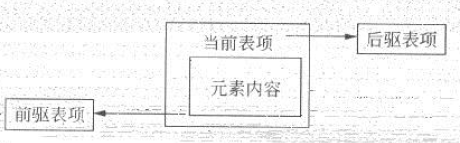
List有三種不同的實現,ArrayList和Vector使用數組實現,其封裝了對內部數組的操作。LinkedList使用了循環雙向鏈表的數據結構,LinkedList鏈表是由一系列的鏈表項連接而成,一個鏈表項包括三部分:鏈表內容、前驅表項和後驅表項。
LinkedList的表項結構如圖:
LinkedList表項間的連接關系如圖:
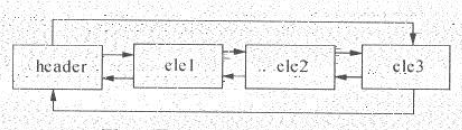
可以看出,無論LinkedList是否為空,鏈表都有一個header表項,它即表示鏈表的開頭也表示鏈表的結尾。表項header的後驅表項便是鏈表的第一個元素,其前驅表項就是鏈表的最後一個元素。
對基於鏈表和基於數組的兩種List的不同實現做一些比較:
1、增加元素到列表的末尾:
在ArrayList中源代碼如下:
1 public boolean add(E e) {
2 ensureCapacityInternal(size + 1); // Increments modCount!!
3 elementData[size++] = e;
4 return true;
5 }
add()方法性能的好壞取決於grow()方法的性能:
1 private void grow(int minCapacity) {
2 // overflow-conscious code
3 int oldCapacity = elementData.length;
4 int newCapacity = oldCapacity + (oldCapacity >> 1);
5 if (newCapacity - minCapacity < 0)
6 newCapacity = minCapacity;
7 if (newCapacity - MAX_ARRAY_SIZE > 0)
8 newCapacity = hugeCapacity(minCapacity);
9 // minCapacity is usually close to size, so this is a win:
10 elementData = Arrays.copyOf(elementData, newCapacity);
11 }
可以看出,當ArrayList對容量的需求超過當前數組的大小是,會進行數組擴容,擴容的過程中需要大量的數組復制,數組復制調用System.arraycopy()方法,操作效率是非常快的。
在LinkedList源碼中add()方法:
1 public boolean add(E e) {
2 linkLast(e);
3 return true;
4 }
linkLast()方法如下:
1 void linkLast(E e) {
2 final Node<E> l = last;
3 final Node<E> newNode = new Node<>(l, e, null);
4 last = newNode;
5 if (l == null)
6 first = newNode;
7 else
8 l.next = newNode;
9 size++;
10 modCount++;
11 }
LinkedList是基於鏈表實現,因此不需要維護容量大小,但是每次都新增元素都要新建一個Node對象,並進行一系列賦值,在頻繁系統調用中,對系統性能有一定影響。性能測試得出,在列表末尾增加元素,ArrayList比LinkedList性能要好,因為數組是連續的,在末尾增加元素,只有在空間不足時才會進行數組擴容,大部分情況下追加操作效率還是比較高的。
2、增加元素到列表的任意位置:
List接口還提供了在任意位置插入元素的方法:void add(int index,E element)方法,由於實現方式不同,ArrayList和LinkedList在這個方法上存在一定的差異。由於ArrayList是基於數組實現的,而數組是一塊連續的內存,如果在數組的任意位置插入元素,必然會導致該位置之後的所有元素重新排序,其效率相對較低。
ArrayList源碼實現:
1 public void add(int index, E element) {
2 rangeCheckForAdd(index);
3 ensureCapacityInternal(size + 1); // Increments modCount!!
4 System.arraycopy(elementData, index, elementData, index + 1,
5 size - index);
6 elementData[index] = element;
7 size++;
8 }
可以看出每次插入都會進行數組復制,大量的數組復制操作導致系統性能效率低下。並且數組插入的位置越靠前,數組復制的開銷就越大。因此,盡可能插入元素在其尾端附近,有助於提高該方法的性能。
LinkedList的源碼實現:
1 public void add(int index, E element) {
2 checkPositionIndex(index);
3
4 if (index == size)
5 linkLast(element);
6 else
7 linkBefore(element, node(index));
8 }
9 void linkBefore(E e, Node<E> succ) {
10 // assert succ != null;
11 final Node<E> pred = succ.prev;
12 final Node<E> newNode = new Node<>(pred, e, succ);
13 succ.prev = newNode;
14 if (pred == null)
15 first = newNode;
16 else
17 pred.next = newNode;
18 size++;
19 modCount++;
20 }
對於LinkedList的在尾端插入和對任意位置插入數據是一樣的,並不會因為插入位置靠前而導致效率低下。因此,在應用中,如果經常往任意位置插入元素,可以考慮使用LinkedList提到ArrayList。
3、刪除任意位置的元素:
List接口還提供了在任意位置刪除元素的方法:remove(int index)方法。在ArrayList中,對於remove()方法和add()方法一樣,在任意位置移除元素,都需要數組復制。
ArrayList的remove()方法的源碼如下:
1 public E remove(int index) {
2 rangeCheck(index);
3
4 modCount++;
5 E oldValue = elementData(index);
6
7 int numMoved = size - index - 1;
8 if (numMoved > 0)
9 System.arraycopy(elementData, index+1, elementData, index,
10 numMoved);
11 elementData[--size] = null; // clear to let GC do its work
12
13 return oldValue;
14 }
可以看出,在ArrayList的每一次刪除操作,都需要進行數組重組,並且刪除元素的位置越靠前,數組重組的開銷就越大。
LinkedList的remove()方法的源碼:
1 public E remove(int index) {
2 checkElementIndex(index);
3 return unlink(node(index));
4 }
5 E unlink(Node<E> x) {
6 // assert x != null;
7 final E element = x.item;
8 final Node<E> next = x.next;
9 final Node<E> prev = x.prev;
10
11 if (prev == null) {
12 first = next;
13 } else {
14 prev.next = next;
15 x.prev = null;
16 }
17
18 if (next == null) {
19 last = prev;
20 } else {
21 next.prev = prev;
22 x.next = null;
23 }
24
25 x.item = null;
26 size--;
27 modCount++;
28 return element;
29 }
1 Node<E> node(int index) {
2 // assert isElementIndex(index);
3
4 if (index < (size >> 1)) {
5 Node<E> x = first;
6 for (int i = 0; i < index; i++)
7 x = x.next;
8 return x;
9 } else {
10 Node<E> x = last;
11 for (int i = size - 1; i > index; i--)
12 x = x.prev;
13 return x;
14 }
15 }
在LinkedList中首先通過循環找到要刪除的元素,如果元素位於前半段則,從前往後找;若位置位於後半段,則從後往前找,但是要移除中間的元素,卻幾乎要遍歷半個List。所有,無論元素位於較前還是較後,效率都比較高,但是位於中間效率就非常低。
4、容量參數:
容量參數是ArrayList和Vector等基於數組的List特有的性能參數,它表示初始化數組的大小。當數組所存儲的元素的數量超過其原有的大小時,它就會進行擴容,即進行一次數組復制,因此,合理設置數組大小有助於減少擴容次數,從而提升系統性能。
5、遍歷列表:
在JDK1.5之後,至少有三種遍歷列表的方式:forEach操作,迭代器,for循環。通過測試發現,forEach綜合性能不如迭代器,而for循環遍歷列表時,ArrayList的性能表現最好,而LinkedList的性能差的無法忍受,因為LinkedList進行隨機訪問,總會進行一次列表的遍歷操作。
對於ArrayList是基於數組來實現的,隨機訪問效率快,因此有限選擇隨機訪問。而LinkedList是基於鏈表實現的,隨機訪問的性能差,應該避免使用。
圍繞著Map接口,最主要的實現類有:HashMap、hashTable、LinkedHashMap和TreeMap。在HashMap的子類中還有Properties類的實現。
1、HashMap和Hashtable
首先說一下,HashMap和Hashtable的區別:Hashtable的大部分方法都實現了同步,而HashMap沒有。因此,HashMap不是線程安全的。其次,Hashtable不允許key或value使用null值,而HashMap可以。第三是內部的算法不同,它們對key的hash算法和hash值到內存索引的映射算法不同。
HashMap就是將key做hash算法,然後將hash值映射到內存地址,直接取得key所對應的數據。在HashMap的底層使用的是數組,所謂的內存地址即數組的下標索引。
HashMap中不得不提的就是hash沖突,需要存放到HashMap中的元素1和元素2經過hash計算,發現對應的內存地址一樣。如下圖:
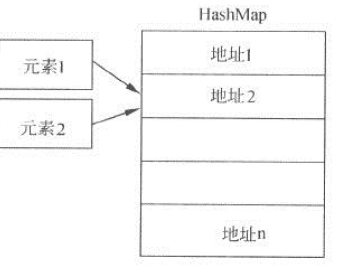
HashMap底層使用的是數組,但是數組內的元素不是簡單的值,而是一個Entry對象。如下圖所示:
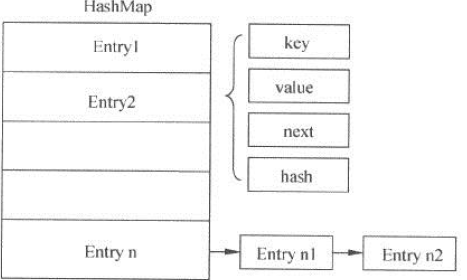
可以看出,HashMap的內部維護了一個Entry數組,每個entry表項包括:key、value、next、hash。next部分表示指向另一個Entry。在HashMap的put()方法中,可以看到當put()方法有沖突時,新的entry依然會安放在對應的索引下標內,並替換掉原來的值,同時為了保證舊值不丟失,會將新的entry的next指向舊值。這樣便實現了在一個數組索引空間內存放多個值。
HashMap的put()操作的源碼:
1 public V put(K key, V value) {
2 if (table == EMPTY_TABLE) {
3 inflateTable(threshold);
4 }
5 if (key == null)
6 return putForNullKey(value);
7 int hash = hash(key);
8 int i = indexFor(hash, table.length);
9 for (Entry<K,V> e = table[i]; e != null; e = e.next) {
10 Object k;
11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
12 V oldValue = e.value;//取得舊值
13 e.value = value;
14 e.recordAccess(this);
15 return oldValue;//返回舊值
16 }
17 }
18
19 modCount++;
20 addEntry(hash, key, value, i);//添加當前表項到i位置
21 return null;
22 }
23 void addEntry(int hash, K key, V value, int bucketIndex) {
24 if ((size >= threshold) && (null != table[bucketIndex])) {
25 resize(2 * table.length);
26 hash = (null != key) ? hash(key) : 0;
27 bucketIndex = indexFor(hash, table.length);
28 }
29
30 createEntry(hash, key, value, bucketIndex);
31 }
32 void createEntry(int hash, K key, V value, int bucketIndex) {
33 Entry<K,V> e = table[bucketIndex];
34 table[bucketIndex] = new Entry<>(hash, key, value, e);//將新增元素放到i位置,並把它的next指向舊值
35 size++;
36 }
基於HashMap的這種實現,只要對hashCode()和hash()的方法實現的夠好,就能盡可能的減少沖突,那麼對HashMap的操作就等價於對數組隨機訪問的操作,具有很好的性能。但是,如果處理不好,在產生大量沖突的情況下,HashMap就退化為幾個鏈表,性能極差。
2、容量參數:
因為HashMap和Hashtable底層是基於數組實現的,當數組空間不足時,就會進行數組擴容,數組擴容就會進行數組復制,是十分影響性能的。
HashMap的構造函數:
1 public HashMap(int initialCapacity) 2 public HashMap(int initialCapacity, float loadFactor)
initialCapacity指定HashMap的初始容量,loadFactor是指負載因子(元素個數/元素總量),HashMap中還定義了一個阈值,它是當前數組容量和負載因子的乘積,當數組的實際容量超過阈值時,就會進行數組擴容。
另外,HashMap的性能一定程度上取決於hashCode()的實現,一個好的hashCode()的實現,可以盡可能減少沖突,提升hashMap的訪問速度。
3、LinkedHashMap
HashMap的一大缺點就是無序性,放入的數據,在遍歷取出時候是無序的。如果需要保證元素輸入時的順序,可以使用LinkedHashMap。
LinkedHashMap繼承自HashMap,因此,其性能是比較好。在HashMap的基礎上,LinkedHashMap內部又增加了一個鏈表,用於存放元素的順序。LinkedHashMap提供了兩種類型的順序,一種是元素插入時的順序,一種是最近訪問的順序。
1 public LinkedHashMap(int initialCapacity, 2 float loadFactor, 3 boolean accessOrder)
其中,accessOrder為true是,是按元素最後訪問時間排序,當accessOrder為false時,按插入順序排序。
4、TreeMap
TreeMap可以對元素進行排序,TreeMap是基於元素的固有順序而排序的(有Comparable或Comparator確定)。
TreeMap是根據key進行排序的,為了確定key的排序算法,可以使用兩種方法指定:
1:在TreeMap的構造函數中注入Comparator
TreeMap(Comparator<? super K> comparator);
2:使用一個實現了Comparable接口的key。
TreeMap是內部是基於紅黑樹實現,紅黑樹是一種平衡查找樹,其統計性能優於平衡二叉樹。
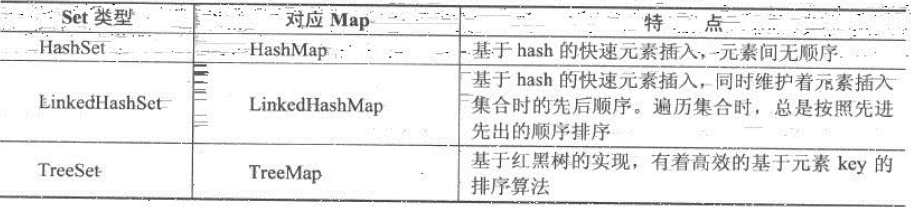
set集合中的元素是不能重復的,其中最主要的實現就是HashSet、LinkedHashSrt和TreeSet。查看Set接口實現類,可以發現所有的Set的一些實現都是相應Map的一種封裝。
set特性如圖所示:
1、分離循環中被重復調用的代碼。如:for(int i=0;i<list.size();i++),可以將list.size()分離出來。
2、省略相同的操作
3、減少方法的調用,方法調用時消耗系統堆棧的,會犧牲系統的性能。
RandomAccess接口是一個標識接口,本身沒有提供任何方法。主要的目的是為了標識出那些可以支持快速隨機訪問的List的實現。例如,根據是否實現RandomAccess接口在變量的時候選擇不同的遍歷實現,以提升性能。