原型模式是為了解決一些不必要的對象創建過程。當Java JDK中提供了Cloneable接口之後,原型模式就變得異常的簡單了。雖然由於Cloneable的引入使用程序變得更簡單了,不過還是有一些需要說明和注意的東西在裡面的。文本就詳細講解一下這些注意事項吧。
如果現在有一個Student對象s1,當我們使用s2=s1的方式對s2進行賦值時,實則是將s1對象的引用復制給了s2。過程如下:
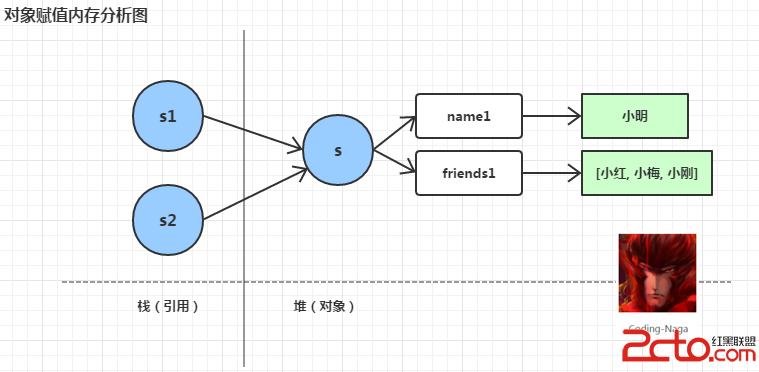
圖-1 對象賦值內存分析圖
所以,對於s1與s2它們所指內存應該為同一塊區域。下面為此兩個“對象”所占用的內存地址:
[email protected] [email protected]
什麼是淺拷貝?淺拷貝後的結果是對象的內存地址變化了(對象的引用發生了變化),可對象中包含的對象內存則沒有變化。
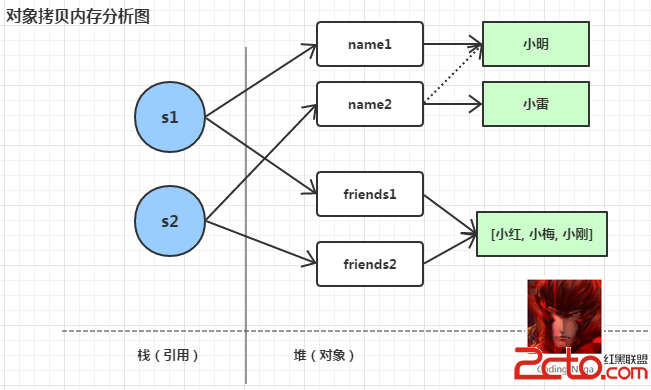
圖-2 對象拷貝內存分析圖
大家看到上面的分析圖是不是有一些疑惑?為什麼name發生了變化,而friends卻沒有變化呢?
這裡先不用說其他的數據類型(int, double, char, short, long, float, byte),我們知道String類型的對象是不可變對象,當我們對不可變對象進行賦值時,它會另外開辟一個新對象。因為這個特性可能會影響到我們對Cloneable的正確判斷,所以這裡需要使用一個可變對象來進行實驗。我選擇的是:List。
假使初始狀態是:s1有兩個朋友,小紅和小梅。當我們使用List的可變性向s2的朋友List中添加了一個新朋友時,理論上只是s2的朋友被修改了,可是實事上並非如此,以下為實驗結果:
初始的List對象: s1.friends: [小紅, 小梅] s2.friends: [小紅, 小梅] 不改變List對象: s1.friends: [小紅, 小梅, 小剛] s2.friends: [小紅, 小梅, 小剛] 重新對List對象賦值: s1.friends: [小紅, 小梅, 小剛] s2.friends: null從實驗中我們可以看到如果我們對可變對象進行對象內部的可變操作時,拷貝的對象和被拷貝的對象都會被修改。單從這一點,我們就可以斷定,Cloneable的拷貝屬於淺拷貝。你是不是要問了,那怎麼樣才能實現對象的深拷貝呢?請接著往下看。
上面說到對象的淺拷貝,在拷貝中我們對可變對象的操作有一些棘手。而深拷貝則可以解決這個問題。深拷貝的實現要依賴與對象的持久化操作。更多關於對象持久化的內容可參見本人另一篇博客:《網絡爬蟲:基於對象持久化實現爬蟲現場快速還原》。
對象持久化是說把一個對象寫到文件中(或是向網絡,或是向進程之間進行傳輸),當我們需要拷貝一個對象時,先把此對象固化到文件,再從文件中讀取對象。這樣一個過程就完成了對象的深拷貝,在博客《網絡爬蟲:基於對象持久化實現爬蟲現場快速還原》中我也有詳細地說明,這裡就不再贅述了。
終於可以說本文的主題(原型模式)了。
原型模式是基於對象的拷貝的,可以是淺拷貝也可以是深拷貝操作。也就是說當我們需要批量生成某一對象,就可以事先創建一個對象的原型,再通過對象的拷貝操作批量生成對象。原型模式的實現類圖如下:
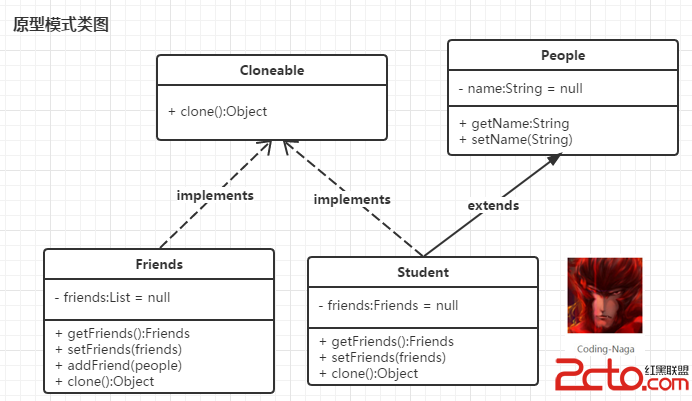
圖-3 原型模式類圖