一、數據庫連接池
開發的時候經常會需要對數據庫進行一些操作,比如說常見的增刪改查之類的,當數據量小的時候,可以直接進行操作,但是當數據量增多的時候,每一次連接以及釋放數據庫都會耗費一定的時間,這個時候,可以采用數據庫連接池來保持數據庫的鏈接,減少連接數據庫對程序帶來的開銷,並且可以減少數據庫的壓力,那麼數據庫鏈接池是一個什麼樣的東西呢?顧名思義,它是一個池子,池子裡放的是對數據庫的鏈接,打個比方魚塘,就是養魚的池子,想要吃魚可以直接去撈,不用自己去親自的買魚苗養魚等,數據庫連接池就是放的對於數據庫的鏈接,統一的把所有的鏈接都給建立好了,用的時候就可以直接的從裡面去取,用完了之後放回池子裡就可以,既然用這個東西,那麼我們也沒必要完全自己去寫代碼實現,有些開源的可以直接用,常見的有三種開源的連接池,c3p0,dbcp,proxool這三種,對於c3p0、proxool這兩種沒用過,只是簡單的用過dbcp的池子,在此講下如何使用dbcp數據庫連接池,以及使用的時候遇到的一些坑
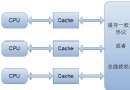
圖1、使用連接池之前
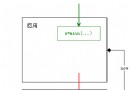
圖2 使用連接池之後
如上圖1所示,在使用連接池之前,需要每次都對數據庫建立鏈接,並且需要隨時進行釋放,在數據量大的情況下,需要很大的連接數據庫的開銷,並且頻繁的對數據庫進行訪問以及釋放,也會對數據庫造成很大的壓力,圖2為使用數據庫連接池之後,將所有的鏈接放在池子裡,不進行釋放,當用的時候直接從池子裡去取,用完之後放回池子裡,池子保持對數據庫的長鏈接,鏈接斷開會進行自動重連,如果連接不夠那麼對應後來的用戶就需要進行等待
二、使用tomcat-dbcp所使用的jar包
包含tomcat-dbcp.jar即可,剩下的都是一些基礎包
三、所使用的配置
dbname.Driver=com.mysql.jdbc.Driver dbname.Url=jdbc:mysql://<your ip>/<your dbname>?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false&maxReconnects=10&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull&connectTimeout=3000 dbname.Username=<your username> dbname.Password=<your password> dbname.InitialSize=15 dbname.MinIdle=10 dbname.MaxIdle=20 dbname.MaxWait=5000 dbname.MaxActive=20 dbname.validationQuery=select 1
其中這些配置只需要放在<yourname>.properties裡面即可,關於每一個的意義
其中driver,url,username,password為常見的數據庫連接的配置
InitialSize為初始化建立的連接數 minidle為數據庫連接池中保持的最少的空閒的鏈接數 maxidle數據庫連接池中保持的最大的連接數 maxwait等待數據庫連接池分配連接的最長時間,超出之後報錯 maxactivite最大的活動鏈接數,如果是多線程可以設置為超出多線程個數個鏈接數 validationQuery測試是否連接是有效的sql語句
三、連接池代碼
public abstract class DB {
private static HashMap<String, DataSource> dsTable = new HashMap<String, DataSource>();//此處記得用static
private BasicDataSource ds;
private PreparedStatement stmt = null;
private DataSource getDataSource(String n) {
if (dsTable.containsKey(n)) {
return dsTable.get(n);//如果不同的數據庫,多個連接池
} else {
synchronized (dsTable) {
ds = new BasicDataSource();
ds.setDriverClassName(DBConfig.getString("db", n.concat(".Driver")));//將<yourname>.properties的值讀進來
ds.setUrl(DBConfig.getString("db", n.concat(".Url")));
ds.setUsername(DBConfig.getString("db", n.concat(".Username")));
ds.setPassword(DBConfig.getString("db", n.concat(".Password")));
ds.setInitialSize(DBConfig.getInteger("db", n.concat(".InitialSize")));
ds.setMinIdle(DBConfig.getInteger("db", n.concat(".MinIdle")));
ds.setMaxIdle(DBConfig.getInteger("db", n.concat(".MaxIdle")));
ds.setMaxWait(DBConfig.getInteger("db", n.concat(".MaxWait")));
ds.setMaxActive(DBConfig.getInteger("db", n.concat(".MaxActive")));
ds.setValidationQuery(DBConfig.getString("db", n.concat(".validationQuery")));
dsTable.put(n, ds);
return ds;
}
}
}
protected Connection conn;
public boolean open() throws SQLException {
BasicDataSource bds=(BasicDataSource)this.getDataSource(this.getConnectionName());
System.out.println("connection_number:"+bds.getNumActive()+"dsTable:"+dsTable);
this.conn = this.getDataSource(this.getConnectionName()).getConnection();
return true;
}
public void close() throws SQLException {
if (this.conn != null)
this.conn.close();
}
protected abstract String getConnectionName();//此函數可以根據自己的需求,將數據庫的名字傳進來即可
public void prepareStatement(String sql) throws SQLException {
this.stmt = this.conn.prepareStatement(sql);
}
public void setObject(int index, Object value, int type) throws SQLException {
this.stmt.setObject(index, value, type);
}
public void setObject(int index, Object value) throws SQLException {
this.stmt.setObject(index, value);
}
public int execute() throws SQLException {
return this.stmt.executeUpdate();
}
}
上述是線程池使用的時候所用到的代碼,只是給出了大概的寫法,具體的DBDAO部分需要根據自己的需求去自己實現,比如批處理,查詢,更新等函數,可以根據個人的需求去進行修改,那麼如何判斷你所創建的鏈接是你想要的呢?有兩種辦法可以檢驗
1、建立一個空的數據庫,查看鏈接個數
2、在linux下面查看鏈接個數
得到processid
ps aux|grep <your java name>
查看鏈接數據庫的鏈接
netstat -apn|grep <your processid>
可以看到具體的鏈接的個數,用來檢驗是否你的鏈接池是正確的
四、遇到的一些坑
因為使用的時候是多線程形式使用的,遇到的最主要的一個坑就是static的用法,因為不是太熟,沒用static,導致了每個線程都建立了一個數據庫連接池,出現了一個“too many files open”的錯誤,這就是因為線程池那邊沒用static所導致的。