俗話說,自己寫的代碼,6個月後也是別人的代碼……復習!復習!復習!涉及到的知識點總結如下:
屬於月經問題了,正好碰上有人問我這類比較基礎的知識,無奈我自覺回答不是有效果,現在深入淺出的總結下:
前一篇文章總結了:JVM 的內存主要分為3個分區
堆棧是啥?是堆還是棧?
之前初學c++的時候被人誤導過,說堆棧是堆……其實這個是翻譯的誤讀,堆棧,其實應該翻譯成棧更合適,和堆區分開來,因為英文的stack就是堆棧的意思, 位於RAM(Random Access Memory,隨機訪問存儲區),速度僅次於寄存器。存放基本變量和引用,存在棧中的數據可以共享。但是,棧中的數據大小和生存周期必須確定,這是棧的缺點。
堆棧不是堆,是棧。堆是存放了所有的java對象(逃逸分析除外)。
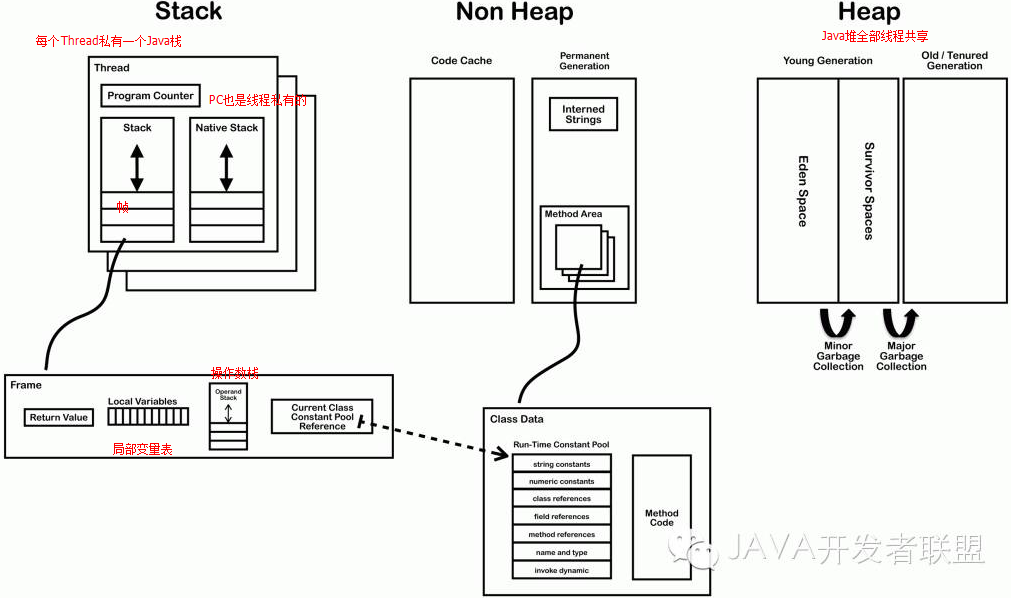
stack,中文翻譯為堆棧,其實指的是棧,這裡講的是數據結構的棧,不是內存分配裡面的堆和棧。棧是先進後出的數據的結構,好比你碟子一個一個堆起來,最後放的那個是堆在最上面的。
棧數據結構比較簡單。heap翻譯為堆,是一種有序的樹。
JVM的堆,棧和c、c++的堆、棧一樣麼? 回答這個問題之前,先得回答程序運行時的內存分配策略,編譯原理的理論認為:程序運行的內存分配有三個策略:
因此我們斷定:堆主要用來存放對象,棧主要是用來執行程序的。而這種不同又主要是由於堆和棧的特點決定的: 例如C/C++……所有的方法調用都是通過棧來進行的,所有的局部變量,形式參數都是從棧中分配內存空間,就好像工廠中的傳送(conveyor belt)帶一樣,Stack Top Pointer 會自動指引你放東西的位置,你所要做的只是把東西放下來就行。退出函數的時候,修改棧頂指針就可以把棧中的內容銷毀。這樣的模式速度最快,當然要用來運行程序了。
現在言歸正傳,之前的文章1已經總結了——JVM是基於堆棧的虛擬機。每一個JVM實例都為每個新創建的線程分配一個棧,而多個線程共享唯一一個堆區,也就是說,對於一個Java程序來說,它的運行就是通過對棧的操作來完成的。棧以幀為單位保存線程的狀態。JVM對棧只進行兩種操作:以幀為單位的壓棧和出棧操作。當某個線程正在執行某個方法時,我們就稱此線程為當前方法,而當前方法使用的幀稱為當前幀。當線程要調用一個Java方法時,JVM就會先在線程的Java棧裡新壓入一個幀。這個幀自然成為了當前幀。在此方法執行期間,這個幀將用來保存方法的形參,局部變量,中間計算過程和其他數據……這個幀在這裡和編譯原理中的活動紀錄的概念是差不多的。
好了,羅嗦了半天,從這個棧式分配機制來看,棧可以這樣理解:棧(Stack)是os在建立某個進程或者線程(在支持多線程的操作系統中是線程)時,為這個(進程)線程建立的存儲區域,該區域具有先進後出的特性。棧中的新加數據項放在其他數據的頂部,移除時你也只能移除最頂部的數據(不能越位獲取)。類似這個紙:

再說堆,每一個JVM的實例有且只有一個堆,這個唯一的堆被全局的線程共享!程序在運行中所創建的所有類實例或數組都放堆中,並由應用所有的線程共享。堆中的數據項位置沒有固定的順序,你可以以任何順序插入和刪除,因為他們沒有“頂部”數據這一概念。如圖:

跟C/C++不同,Java中分配堆內存是自動化管理的(Java虛擬機的自動垃圾回收器來管理,缺點是,由於要在運行時動態分配內存,存取速度較慢)Java中所有對象的存儲空間都是在堆中分配,但對象引用是在棧中分配,而堆中分配的內存才是實際的這個對象本身,棧中分配的內存只是一個指向這個對象的指針(引用)變量而已(變量的取值等於數組或對象在堆內存中的首地址)。而c++的堆內存管理,需要程序員手動管理的,new,delete運算符……
內存管理中的棧分配方法有什麼特點?優缺點又是什麼?
首先想到就是該快內存FILO的特性,還有經過前面這麼羅嗦的哔哔,又得出一個結論:棧中的數據可以共享。
int a = 3; int b = 3;
編譯器先處理int a = 3; 會在棧中創建一個變量為a的引用,然後查找棧中是否有3這個值,如果沒找到,就將3存放進來,然後將a指向3。接著處理int b = 3; 在創建完b的引用變量後,因為在棧中已經有3這個值,便將b直接指向3。這樣,就出現了a與b同時均指向3的情況。這時,如果再令a=4; 那麼編譯器會重新搜索棧中是否有4值,如果沒有,則將4存放進來,並令a指向4; 如果已經有了,則直接將a指向這個地址。因此a值的改變不會影響到b的值。要注意這種數據的共享與兩個對象的引用同時指向一個對象的這種共享是不同的,因為這種情況a的修改並不會影響到b, 它是由編譯器完成的,它有利於節省空間。而一個對象引用變量修改了這個對象的內部狀態,會影響到另一個對象引用變量。
優點:速度快,不用管理內存,缺點是太小,方法調用過度,容易內存溢出,還有棧就是暫時,數據有生命周期,屬於臨時存儲。
站在實際的計算機物理內存的角度上看,棧和堆在哪兒?
在通常情況下由操作系統(OS)和語言的運行時(runtime)控制嗎?
它們的作用范圍是什麼?
它們的大小由什麼決定?
哪個更快?
回答這個問題之前,必須先知道內存管理的機制根據不同的編譯器和處理器架構的不同而不同!為了幫助理解,先總結幾個原理:
什麼是局部性原理?
os的教科書這樣寫到局部性原理:CPU訪問存儲器時,無論是存取指令還是存取數據,所訪問的存儲單元都趨於聚集在一個較小的連續區域中。
我是這樣理解的:計算機的存儲系統從小到大,分為寄存器,一級緩存,二級緩存,三級緩存,內存,磁盤……而寄存器是CPU存放計算數據的地方,CPU要工作了,需要數據或者地址,先從一級緩存裡面找,找不到就從二級緩存裡面找,二級找不到就去三級找……假如找到磁盤才有了目標數據,那麼該數據就會先放入內存,再存入三級緩存、二級緩存、一級緩存,最後存入寄存器,才能被CPU使用。可以說,一級緩存是寄存器的緩存,二級緩存是一級緩存的緩存,三級緩存是二級緩存的緩存……下面一層是上面一層的緩存。而局部性原理,通俗的說就是因為CPU的運轉速度非常非常快!是高速存儲的!而磁盤和內存之間的存取速度很慢(I/O瓶頸繞不開……),如果CPU需要的數據更多的在磁盤,內存……這樣會花非常多的等待時間,故我們就設置了高速緩存!當CPU頻繁的用了某塊數據,計算機會遇見性的把它及其附近地址上的數據都存入高速緩存內,因為預判這些數據再次被用到的可能性很大,計算機就把它們存到越接近寄存器的層次,也就是cpu所訪問的數據,都趨於集中在一個較小的連續區域中,這也才是緩存的真正意義。那麼,現在的問題就變為回答:
計算機怎樣才能判斷一個數據接下來可能被用到?
哦了。前面幾個問題已經得出這樣的結論:棧和堆都是用來從底層操作系統中獲取內存的。在多線程環境下每一個線程都可以有他自己完全的獨立的棧,但是他們共享堆。並行存取被堆控制而不是棧。
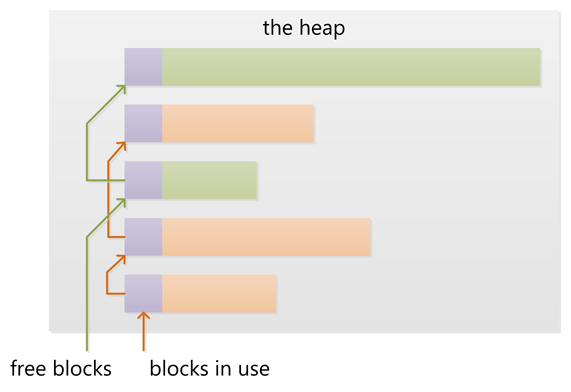
在堆上新分配(用 new 或者 malloc)內存是從空閒的內存塊中找到一些滿足要求的合適塊。這個操作會更新堆中的塊鏈表。這些元信息也存儲在堆上,經常在每個塊的頭部一個很小區域。堆增加新塊通常從低地址向高地址擴展,也就是說堆是向上增長的!因此可以認為堆隨著內存分配而不斷的增加大小。如果申請的內存大小很小的話,通常從底層操作系統中得到比申請大小要多的內存。申請和釋放許多小的塊可能會產生如下狀態:在已用塊之間存在很多小的浪費的空閒塊……進而導致申請大塊內存失敗,雖然空閒塊的總和足夠,但是空閒的小塊是零散的,不能滿足申請的大小,這叫做“內存碎片”。當旁邊有空閒塊的已用塊被釋放時,新的空閒塊可能會與相鄰的空閒塊合並為一個大的空閒塊,這樣可以有效的減少“碎片”的產生。
堆的管理依賴於運行時環境,C 使用 malloc ,free,C++ 使用 new 和delete,但是很多語言有垃圾回收機制,比如Java的GC。
棧:棧經常與 sp 寄存器一起工作,最初 sp 指向棧頂(棧的高地址)。棧是向下增長的!
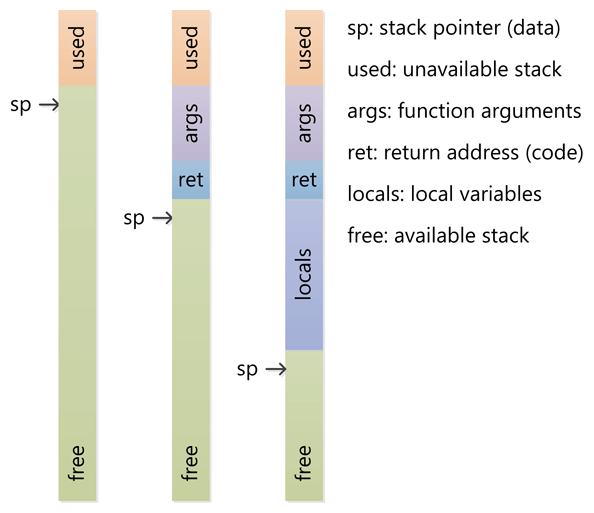
CPU 用 push 指令來將數據壓棧,用 pop 指令來彈棧。當用 push 壓棧時,sp 值減少(向低地址擴展)。當用 pop 彈棧時,sp 值增大。存儲和獲取數據都是 CPU 寄存器的值。
棧要受到內存塊的限制,不斷的函數嵌套……為局部變量分配太多的空間,可能會導致棧溢出。當棧中的內存區域都已經被使用完之後繼續向下寫(低地址),會觸發一個 CPU 異常。這個異常接下會通過語言的運行時轉成各種類型的棧溢出異常。總的來說,棧以更低層次的特性與處理器架構緊密的結合到一起,當堆不夠時可以擴展空間。但是,擴展棧通常來說是不可能的,因為在棧溢出的時候,執行線程就被操作系統關閉了,這已經太晚了。
現在可以回答這幾個問題:
在通常情況下由操作系統(OS)和語言的運行時(runtime)控制嗎?
如前所述,堆和棧是一個統稱,可以有很多的實現方式。計算機程序通常有一個棧叫做調用棧,用來存儲當前函數調用相關的信息(比如:主調函數的地址,局部變量),因為函數調用之後需要返回給主調函數。棧通過擴展和收縮來承載信息。實際上,程序不是由運行時來控制的,它由編程語言、操作系統甚至是系統架構來決定。堆是在任何內存中動態和隨機分配的(內存的)統稱;也就是無序的。內存通常由操作系統分配,通過應用程序調用 API 接口去實現分配。在管理動態分配內存上會有一些額外的開銷,不過這由操作系統來處理。
它們的作用范圍是什麼?
調用棧是一個低層次的概念,就程序而言,它和“作用范圍”沒什麼關系。就高級語言而言,語言有它自己的范圍規則。一旦函數返回,函數中的局部變量會直接釋放。在堆中,也很難去定義。作用范圍是由操作系統限定的,但是編程語言可能增加它自己的一些規則,去限定堆在應用程序中的范圍。體系架構和操作系統是使用虛擬地址的,然後由處理器翻譯到實際的物理地址中,還有頁面錯誤等等。它們記錄那個頁面屬於那個應用程序。不過你不用關心這些,因為你僅僅在編程語言中分配和釋放內存,和一些錯誤檢查(出現分配失敗和釋放失敗的原因)。
它們的大小由什麼決定?
依賴於語言,編譯器,操作系統和架構。棧通常提前分配好了,因為棧必須是連續的內存塊。語言的編譯器或者操作系統決定它的大小。不要在棧上存儲大塊數據,這樣可以保證有足夠的空間不會溢出,除非出現了無限遞歸的情況或者其它。堆是任何可以動態分配的內存的統稱。它的大小是變動的。在現代處理器中和操作系統的工作方式是高度抽象的,因此你在正常情況下不需要擔心它實際的大小,除非你必須要使用你還沒有分配的內存或者已經釋放了的內存。
哪個更快一些?
棧更快因為所有的空閒內存都是連續的,因此不需要對空閒內存塊通過列表來維護。只是一個簡單的指向當前棧頂的指針。編譯器通常用一個專門的、快速的寄存器SP來實現。更重要的一點是,隨後的棧上操作會遵循局部性原理。
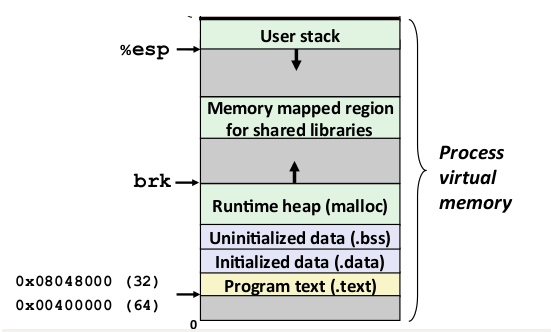
JVM的棧如何對應os?
以linux 中一個進程的虛擬內存分布為例:
文章總結參考資料:《Java編程思想》、《現代操作系統》,《深入理解計算機系統》、《現代編譯原理》,《深入理解Java虛擬機》、《JVM規范 7》、知乎、stackoverflow……