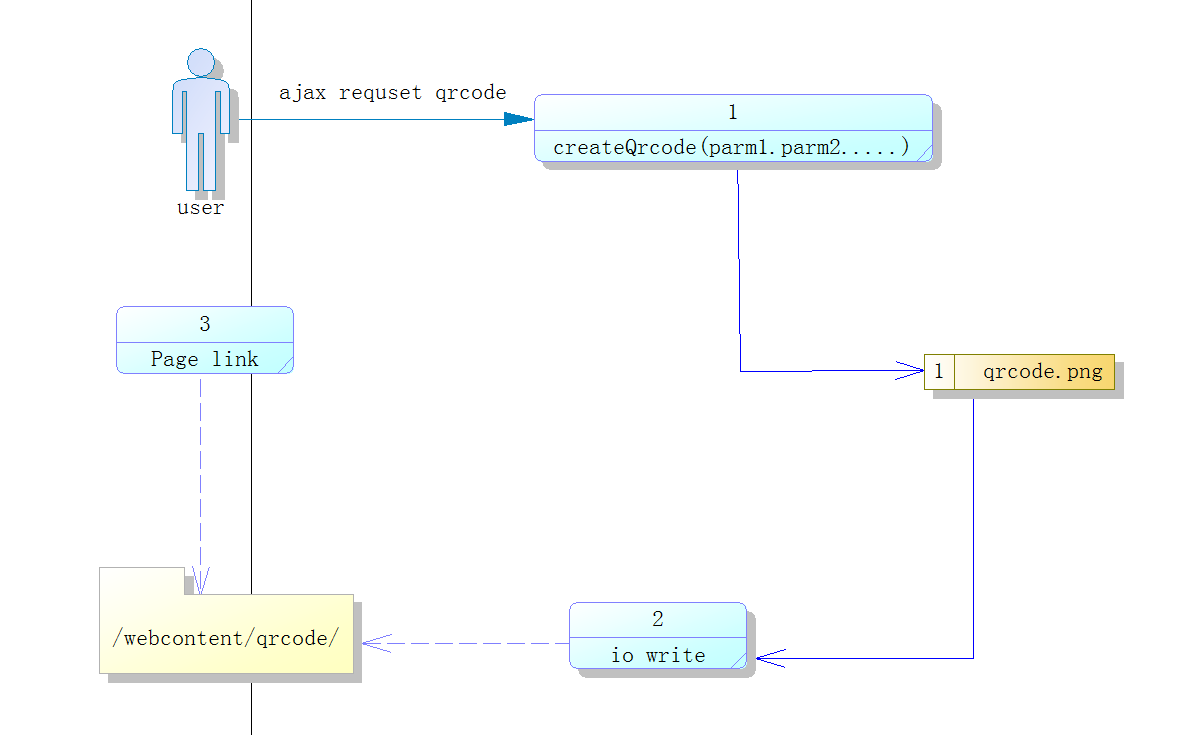
Atitit。Time base gc 垃圾 資源 收集的原理與設計
1. MRC(MannulReference Counting手動 retain/release/autorelease語句1
2. 自動垃圾回收(GC)1
3. Arc ARC介於自動垃圾回收(GC)和手動內存管理之間。1
3.1. 從各種垃圾收集算法最基本的運行方式來說,大概可以分成三個類型: 1. 引用計數(reference counting):1
3.2. 標記-清掃(mark-sweep)2
3.3. 3. 節點復制(copying)。 分代2
3.4. Attilax time base gc3
4. 二、GC是如何工作的3
5. 如何關聯----wrap file,network socket4
6. 參考4
ARC介於自動垃圾回收(GC)和手動內存管理之間。就像垃圾回收,ARC讓程序員不再需要書寫retain/release/autorelease語句。但它又不同於垃圾回收,ARC無法處理retaincycles。在ARC裡,如果兩個對象互相強引用(strong references)將導致它們永遠不會被釋放,甚至沒有任何對象引用它們。 因此,盡管ARC能免去程序員大部分內存管理問題,但仍然要程序員自己避免retaincycles或手動打斷對象之間的retain循環。
作者:: 綽號:老哇的爪子 ( 全名::Attilax Akbar Al Rapanui 阿提拉克斯 阿克巴 阿爾 拉帕努伊 ) 漢字名:艾龍, EMAIL:[email protected]
轉載請注明來源: http://www.cnblogs.com/attilax/
基本思路是為每個對象加一個計數器,記錄指向這個對象的引用數量。每次有一個新的引用指向這個對象,計數器加一;反之每次有一個指向這個對象引用被置空或者指向其他對象,計數器減一。當計數器變為 0 的時候,自動刪除這個對象。
引用計數的優點是 1)相對簡單,不需要太多運行時(run-time)的支持,可以在原生不支持 GC 的語言裡實現。2)對象會在成為垃圾的瞬間被釋放,不會給正常程序的執行帶來額外中斷。它的死穴是循環引用,對象 A 包含一個引用指向對象 B ,同時對象 B 包含一個引用指向對象 A,計數器就抓瞎了。另外,引用計數對正常程序的執行性能有影響(每次引用賦值都要改計數器),特別是在多線程環境下(改計數器要加鎖同步)。
現在仍然主要采用引用計數的例子有 Apple 的 ARC,C++ 新標准裡的 std::shared_ptr。
。
基本思路是先按需分配,等到沒有空閒內存的時候從寄存器和程序棧上的引用出發,遍歷以對象為節點、以引用為邊構成的圖,把所有可以訪問到的對象打上標記,然後清掃一遍內存空間,把所有沒標記的對象釋放。
標記-清掃沒有無法處理循環引用的問題,不觸發 GC 時也不影響正常程序的執行性能。但它的問題是當內存耗盡觸發 GC 時,需要中斷正常程序一段時間來清掃內存,在內存大對象多的時候這個中斷可能很長。
采用或者部分采用標記-清掃的例子非常多,不一一列舉了。
基本思路是把整個內存空間一分為二,不妨記為 A 和 B。所有對象的內存在 A 中分配,當 A 塞滿的時候,同樣從寄存器和程序棧上的引用出發,遍歷以對象為節點、以引用為邊構成的圖,把所有可以訪問到的對象復制到 B 去,然後對調 A 和 B 的角色。
相對於標記-清掃,節點復制的主要缺點是總有一半空間空閒著無法利用,另一個比較隱晦的缺點是它使用內存的方式與現有的內存換頁、Cache 換入換出機制有潛在的沖突。但它有個很大的優點: 所有的對象在內存中永遠都是緊密排列的,所以分配內存的任務變得極為簡單,只要移動一個指針即可。對於內存分配頻繁的環境來說,性能優勢相當大。另外,由於不需要清掃整個內存空間,所以如果內存中存活對象很少而垃圾對象很多的話(有些語言有這個傾向),觸發 GC 造成的中斷會小於標記-清掃。
根據一個統計學上的結論,如果一個內存對象在某次Mark過程中發現不是垃圾,那麼它短期內成為垃圾的可能性就很小。分代收集將那些在多次垃圾收集過程中都沒有被標記為垃圾對象的內存對象集中到另外一個區域——年老的區域,即這個區域中的內存對象年齡比較大。因為年老區域內內存對象短期內變成垃圾的概率很低,所以這些區域的垃圾收集頻率可以降低,相對的,對年輕區域內的對象進行高頻率的垃圾收集。這樣可以提高垃圾收集的整體性能。
==== 基本算法介紹完畢的分割線 ====
以上三種基本算法各有優缺點,也各有許多改進的方案。目前工程實踐上最為成功的方案應該要算分代(generational)垃圾收集。它的基本思路是這樣的:程序中存在大量的臨時對象,分配出來之後很快就會被釋放,而同時如果一個對象分配出來之後相當長的一段時間內都沒回收,那麼極有可能它的生命周期很長,嘗試收集它會是無用功。所以可以把內存有意識地按“對象年齡”分成若干塊,不妨記為老中青(XD),所有的分配都在青代進行,青代塞滿只對青代做 GC,然後把存活下來的對象移動到中代,直到中青代都塞滿,再把存活下來下來的對象移動到老代 —— 這只是個思路上的例子,實踐中分代式垃圾收集算法的方案五花八門,而且常常同時使用了不止一種基本算法(比如青代用節點復制,老代用標記清掃啥的)。
GC的工作流程主要分為如下幾個步驟:
1、標記(Mark)
2、計劃(Plan)
3、清理(Sweep)
4、引用更新(Relocate)
5、壓縮(Compact)
我希望改進這一點,也就是說,那所有 gc 相關的數據集中在一起,整個收集過程,除了最終釋放那些不再使用的內存外,不會碰用戶數據塊的內存。
gc 最重要的一點,就是要對堆棧上的數據進行關聯。在收集發生時,堆棧上所有臨時分配出來的內存塊都不應該被釋放掉。C 語言本身不提供堆棧遍歷的特性,所以要想個自然的方案讓用戶可以方便的做到這點。
在用戶的調用棧上,每個調用級上,臨時分配的內存都被自然掛接在當前級別的堆棧掛接點上,一旦調用返回,當前級別的所有臨時內存塊都應該和根斷開。當然,如果內存塊作為返回值出現的話,需要保留。在 C 裡,我們需要給每個函數的入口和出口都做一個監護,保證 gc 的正確工作。(如果是 C++ ,要稍微方便一點,在函數進入點設置一個 guard 對象即可)因為這個監護過程會非常頻繁,對其的優化是重點工作。
各種編程語言的實現都采用了哪些垃圾回收算法?這些算法都有哪些優點和缺點? - GC垃圾回收(計算機科學) - 知乎.html
垃圾回收機制GC知識再總結兼談如何用好GC - JeffWong - 博客園.html ()imp
垃圾回收(GC)的三種基本方式 - 博客 - 伯樂在線.html