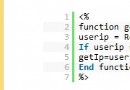
在做采集的朋友就會知道經常會碰到采集過來的內容是亂碼,下面我們就來看一篇關於asp教程采集數據並自動判斷網頁編碼並轉換吧。
<%@LANGUAGE="JAVASCRIPT" CODEPAGE="65001"%>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>asp自動判斷網頁編碼並轉換</title>
</head>
<%Server.ScriptTimeout=9999999;
function send_request(url){
var codedtext;
http_request = Server.CreateObject("Microsoft.XMLHTTP");
http_request.Open("GET",url,false);
http_request.Send(null);
if (http_request.ReadyState == 4){
//自動判斷編碼開始
var charresult = http_request.ResponseText.match(/CharSet=(S+)">/i);
if (charresult != null){
var Cset = charresult[1];
}else{Cset = "gb2312"}//對獲取不到的網站采用gb2312編碼,可自行更改
//自動判斷編碼結束
codedtext = bytesToBSTR(http_request.Responsebody,Cset);
}else{
codedtext = "Erro";
}
return(codedtext);
}
function bytesToBSTR(body,Cset){
var objstream;
objstream = Server.CreateObject("Adodb.Stream");
objstream.Type = 1;
objstream.Mode = 3;
objstream.Open();
objstream.Write(body);
objstream.Position = 0;
objstream.Type = 2;
objstream.Charset = Cset;
bytesToBSTR = objstream.Readtext;
objstream.Close;
return(bytesToBSTR);
}%>
<body>
<%Response.Write(send_request("http:///404.htm"))%>
</body>
</html> 采集原理很簡單就是用了asp xmlhttp來采集,並且adodb.stream來對采集過來的數據進行處理。