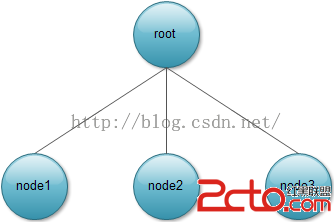
一般來說,語句按一定規則進行推導後會形成一個語法樹,這種樹狀結構有利於對語句結構層次的描述。同樣Jaspe對JSP語法解析後也會生成一棵樹,這棵樹各個節點包含了不同的信息,但對於JSP來說解析後的語法樹比較簡單,只有一個父節點和n個子節點。例如node1是表示形如的注釋節點,節點裡面包含了一個表示注釋字符串的屬性;而node2則可能是表示形如<%= a+b %>的表達式節點,節點裡面包含一個表示表達式的屬性,同樣地其他節點可能表示JSP的其他語法,有了這棵樹我們就可以很方便地生成對應的Servlet。
現在看看怎樣解析生成這棵樹的,
①首先定義樹數據結構,其中parent指向父節點,nodes是此節點的子節點,且nodes應該是有序的列表,這樣能保證與解析順序一致。另外由於每個節點的屬性不同,Node類只提供公共的部分屬性,對於不同節點其他屬性需要繼承Node額外實現。
public class Node {
private Node parent;
private List
private String text;
private Attributes attrs;
}
public class RootNode{}
public class CommentNode{}
public class PageNode{}
public class IncludeNode{}
public class TaglibNode{}
②其次需要一個讀取JSP文件的工具類,此工具類主要提供對JSP文件的字符操作,其中有個cursor變量用於表示目前解析位置,主要的方法則包括判斷是否到達文件末尾的hasMoreInput方法,獲取下個字符的nextChar方法,獲取某個范圍內的字符組成的字符串getText方法,匹配是否包含某字符串的matches方法,跳過空格符的skipSpaces方法,以及跳轉到某個字符串的skipUntil方法。有了這些輔助操作就可以開始讀取解析語法了。
public class JspReader{
private int cursor;
public int getCursor(){ return cursor ; }
boolean hasMoreInput(){...}
public int nextChar(){...}
public String getText(int start,int end){...}
boolean matches(String string){...}
int skipSpaces(){...}
int skipUntil(String limit){...}
}
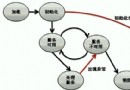
③需要一個JSP語法解析器對JSP進行解析,這裡為了簡單說明只解析注釋語法、<@page .../%>頁面指令、<[email protected]../%>包含指令、<[email protected]../%>標簽指令。假設對index.jsp進行語法解析,匹配到<%--則表示注釋語法,獲取其中的注釋文字並創建commentNode節點作為根節點的子節點,如果匹配到<%@則有三種可能,所以需要進一步解析,即對應頁面指令、包含指令和標簽指令等的解析。最後解析出來的就是如圖所示的一棵語法樹。
public class Parser{
public RootNode parse(){
JspReader reader = new JspReader("index.jsp");
RootNode root = new RootNode();
while (reader.hasMoreInput()) {
if (reader.matches("<%--")) {
int start = reader.getCursor();
reader.skipUntil("--%>");
int end = reader.getCursor();
CommentNode commentNode = new CommentNode ();
commentNode.setText(reader.getText(start, stop));
commentNode.setParent(parent);
parent.getList().add(commentNode);
} else if (reader.matches("<%@")) {
if (reader.matches("page")) {
解析<[email protected]../%>裡面的屬性生成attrs
PageNode pageNode = new PageNode ();
pageNode.setAttributes(attrs);
pageNode.setParent(parent);
parent.getList().add(pageNode);
} else if (reader.matches("include")) {
解析<[email protected]../%>裡面的屬性生成attrs
IncludeNode includeNode = new IncludeNode ();
includeNode.setAttributes(attrs);
includeNode.setParent(parent);
parent.getList().add(includeNode);
} else if (reader.matches("taglib")) {
解析<[email protected]../%>裡面的屬性生成attrs
TaglibNode taglibNode = new TaglibNode ();
taglibNode.setAttributes(attrs);
taglibNode.setParent(parent);
parent.getList().add(taglibNode);
}
}
}
return root;
}
}