IE缺省對URL後面的參數是不編碼發送的,但是Tomat缺省是按ISO8859-1來進行URL編碼的,因此才會出錯。
方法一:
對URL鏈接進行二次編碼:
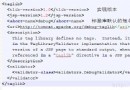
<a onclick="javascript:window.open(encodeURI(encodeURI('./DispatchAction.do?efFormEname=FKRY0001&code_type=中文參數')))">測試</a>
或者單獨對參數進行二次編碼:
var code_type = "中文參數";
code_type = encodeURI(code_type);
code_type = encodeURI(code_type);
window.open("./DispatchAction.do?efFormEname=FKRY0001&code_type="+code_type);
Service:
String code_type = request.getParameter("code_type");
//這句話一定要寫,因為如果不寫的話編碼就是%E5%A6%88%
code_type = java.net.URLDecoder.decode(code_type,"UTF-8");
有人提出為什麼要在客戶端對字符串重復編碼兩次呢?
如果因為項目需要,不能指定容器使用何種編碼規則來解碼提交的參數,比如:需要接收來自不同頁面,不地編碼的參數內容時。 (又或者是開發人員被這有點復雜的東西搞得暈頭轉向,不懂得如何正確的去做好這接收參數的工作)
這個時候,在客戶端對參數進行二次編碼,可以有效的避開“提交多字節字符”的這個棘手問題。
因為第一次編碼,你的參數內容便不帶有多字節字符了,成了純粹的 Ascii 字符串。(這裡把編第一次的結果叫成 [STR_ENC1] 好了。[STR_ENC1] 是不帶有多字節字符的)
再編一次後,提交,接收時容器自動解一次(容器自動解的這一次,不管是按 GBK 還是 UTF-8 還是 ISO-8859-1 都好,都能夠正確的得到 [STR_ENC1])
然後,再在程序中實現一次 decodeURIComponent (Java中通常使用 java.net.URLDecoder.decode(***, "UTF-8"))就可以得到想提交的參數的原值。
簡單來說,就是Tomcat服務器會自動幫你做一次URLDecode,再加上你自己在Service代碼裡面寫的URLDecode,一共就是兩個Decode了。既然要兩次Decode,當然就需要兩次Encode了。或許你會問,干脆只Encode一次,然後在java代碼裡不Decode,呵呵,這個也是不行的,這其實也就是為什麼要進行兩次Encode的原因吧。
方法二:(經測試不支持IE8)
http://xxx.do?ptname=中文參數
String strPtname = request.getParameter("ptname");
strPtname = new String(strPtname.getBytes("ISO-8859-1"), "UTF-8");
方法三:
<%@ page contentType="text/html;charset=gb2312" %>
<a href="ds.jsp?url=<%=java.net.URLEncoder.encode("編碼的是這裡","GB2312")%>">點擊這裡</a>
<%
//request.setCharacterEncoding("GBK");
if(request.getParameter("url")!=null)
{
str=request.getParameter("url");
str=java.net.URLDecoder.decode(str,"GB2312");
str=new String(str.getBytes("ISO-8859-1"));
out.print(str);
}
%>
方法四:
Tomcat中設置server.xml中的Connector熟悉URIEncoding="UTF-8",確保解碼格式與編碼格式統一。