一、前言
從一個網站上,看到一個“抓網頁”的代碼,覺得有點意思,但是沒有提供源代碼,於是,自己想寫一個,其實代碼比較簡單的。
二、代碼
<%@ page contentType="text/html;charset=gb2312"%>
<%
String sCurrentLine;
String sTotalString;
sCurrentLine="";
sTotalString="";
java.io.InputStream l_urlStream;
java.net.URL l_url = new java.net.URL("http://www.163.net/");
java.net.HttpURLConnection l_connection = (java.net.HttpURLConnection) l_url.openConnection();
l_connection.connect();
l_urlStream = l_connection.getInputStream();
java.io.BufferedReader l_reader = new java.io.BufferedReader(new java.io.InputStreamReader(l_urlStream));
while ((sCurrentLine = l_reader.readLine()) != null)
{
sTotalString+=sCurrentLine;
}
out.println(sTotalString);
%>
三、後記
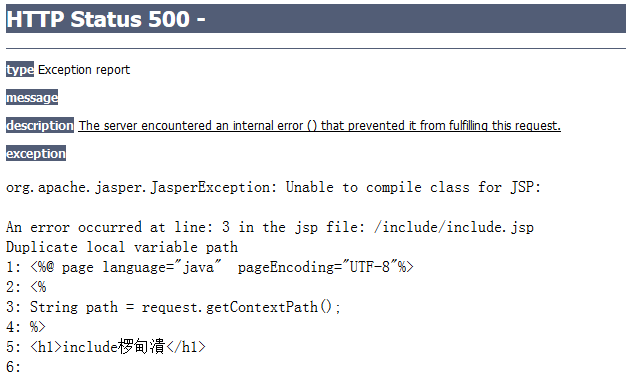
雖然代碼比較簡單,但是,我認為根據這個,可以實現“網絡爬蟲”的功能,比如從頁面找href連接,然後再得到那個連接,然後再“抓”,不停止地(當然可以限定層數),這樣,可以實現“網頁搜索”功能。