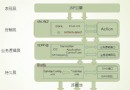
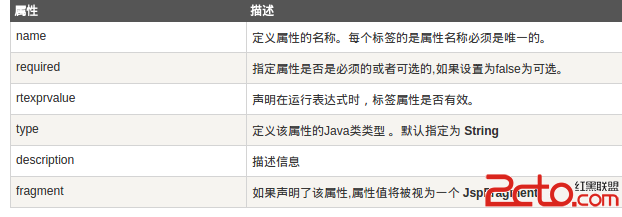
簡單地說,這三者不過把一些常用的功能方法進行封裝,使得這些方法規范化,避免像在jsp開發中重復而零散地編寫類似代碼。 再詳細一點就是說,struts2負責處理客戶的請求並轉發到特定action方法去執行,這個過程用到的是struts2的轉轉器、過濾器、攔截器等功能。struts2標簽功能等同於jsp標簽,struts2標簽的優勢在於利用struts2框架的運作機制,讓數據在頁面的展示更加便捷。hibernate干啥呢?它負責action方法裡面的邏輯實現(CRUD操作),這些實現包括與數據庫打交道——如何連接數據庫,如何把數據表裡面的數據映射為普通的java類等等。那麼spring干嘛用的?先看下文,到最後你就明白了。 下面說明它們各自的功能角色:struts2側重於控制器功能,當客戶端發送一個地址請求,Struts(通過配置文件)根據請求代碼做出反映,並進行頁面調用或轉發。比如:/login 請求很可能是一個登錄請求,那麼Struts2應該回復一個login.jsp頁面給客戶端進行登錄,然而地址欄不會看到/login.jsp樣式,具體地址被隱藏了,只看到請求地址樣式。struts2的標簽類似於jstl標簽,它們在本質上是一致的,都是為視圖層方便編碼以及為更好地與控制器融合。不是一定要使用Struts2標簽才能使用它的控制器功能。可以選擇其他標簽,如jsp或jstl標簽等。標簽只是皮毛。其實spring它也有一套自己的標簽,哪能用那麼多啊。熟悉使用一種標簽即可。 hibernate框架主要是負責連接數據庫,把每個數據表轉化為一個類,表中的每行數據相當於類的一個對象,hibernate通過對象的方式進行讀取操作。 說到spring,不得不說控制反轉,有關控制反轉,請搜索“java設計模式”。然而,控制反轉不能說是spring的功能,而只是他的設計思想,也就是說spring是由“控制反轉”和”切面編程”這些設計模式開發出來的。spring包有許多類和方法,有像hibernate那樣操作底層數據庫功能的方法,有可以操作復雜的業務操作,這要看調用它什麼樣的接口和方法。由於它特殊的設計模式,使得它可以靈活地與其它框架整合,主要是通過配置文件的方式來完成。spring和hibernate整合在實際上替代了hibernate,因為它對hibernate的方法進行了包裝。 三者整合的話,由spring來統領全局。spring和strut2整合不過是為struts2的action類提供容器管理,也就是說,當要實例化一個action類的時候,根據spring配置,spring容器會負責生成該action的對象。什麼時候要實例化action類呢?也就是說何時生成action類的對象(實例)?答案是當客戶端請求的時候。客戶請求的目的是調用action中的方法,以便獲取數據或操作數據。action類裡面定義的方法,一般都是實例方法,因此需要得到action實例去調用這些方法。對於每個action類,實例化方式有2類:單例方式,原型方式。單例方式是說spring對該action類只實例化一次,即new一次而已,得到該類的一個對象,以後每一個客戶端請求都是調用該對象的方法去響應客戶。另外的話,像tomcat這樣的web容器,它為每一次請求新建一個線程,如何以單例模式實例化的action類中沒有類變量,則沒有臨界資源問題,相反,action類中定義的類變量則可能變成臨界資源。如果在spring配置中,對某action類以原型方式實例化,則每一次新請求,都會新實例化一次,並為該請求新建一個線程。也就是說在這個新的線程裡面,用這個新的實例去響應客戶的這次請求。同樣,如果action實例方法存在操作action類變量的行為,則可能引發線程問題,即對臨界資源的訪問問題。 實際上,我們一般把那些響應用戶請求的action方法定義為無參數的形式,但是這並不能妨礙方法內部與外界與的交流,這是有其它途徑,那就是通過在action方法中訪問action的實例變量來獲取用戶給它發生的信息,也可以通過調用其他action實例方法得到信息,當然也可以是調用類變量和類方法獲得信息,但這需要處理線程問題,因為類變量和類方法被所有的線程執行。