WTP Structured Model
有關另外一個WTP重要的數據模型IStructuredDocument已經在前面介紹過了,今天我們看一下另外一 個核心的數據模型IStructuredModel。在繼續下面的內容之前,請確保當前工作區中已經導入(無論是 源碼方式導入還是二進制方式導入)了如下工程:
org.eclipse.jst.jsp.core
org.eclipse.jst.jsp.ui
org.eclipse.wst.css.core
org.eclipse.wst.css.ui
org.eclipse.wst.html.core
org.eclipse.wst.html.ui
org.eclipse.wst.javascript.core
org.eclipse.wst.javascript.ui
org.eclipse.wst.sse.core
org.eclipse.wst.sse.ui
org.eclipse.wst.xml.core
org.eclipse.wst.xml.ui
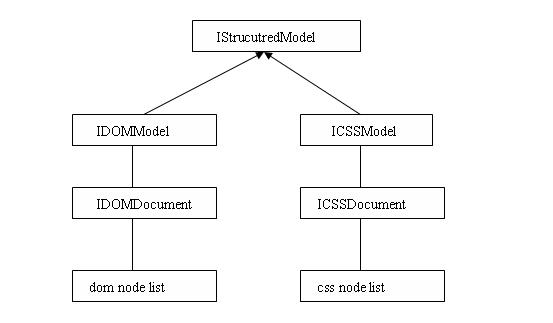
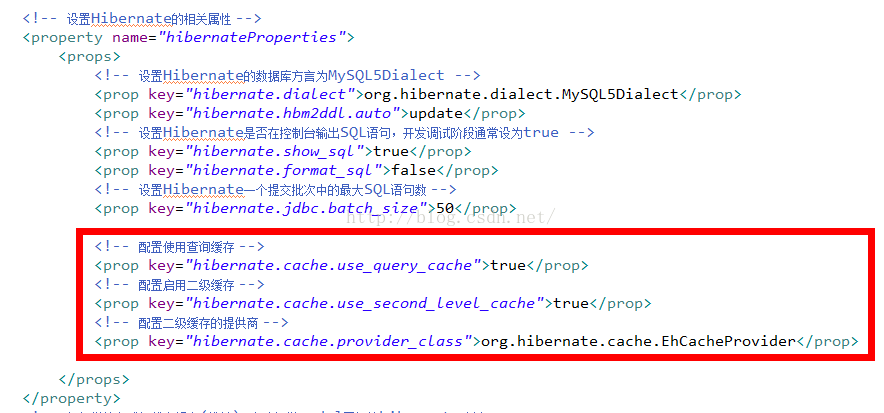
在前面介紹IStructuredDocument的時候,我們知道IStructuredDocument的具體實現其實就是JFace Text Framework中IDocument接口的具體實現,其核心作用也集中在將特定文本按照特定的語法規則進行 區域劃分,提供相應的位置信息,這為WTP頁面資源編輯器建立了核心數據模型。但是,單純擁有偏重於 語法的IStrucuturedDocument是不夠的,我們同時還需要另外一套偏重於語義的數據模型,這就是 IStructuredModel和其背後的WTP xmlDOM實現(說明:對於CSS模型,是完全由WTP自己實現的,和本系 列文章關系不大,本篇中不做詳細介紹)。
注意:IStructuredModel以IStrucuturedDocument為基礎構建,IStructuredDocument並不知道 IStructuredModel,但是IStructuredModel知道該模型對應的IStrucuturedDocument!!! 現在先大致 猜測一下原因,如果是直接將特定頁面資源的內容直接轉換為IStructuredModel肯定不容易,因為我們 頁面資源中的內容往往不是那麼規則,那轉化的過程中肯定避免不了自己去做大量的解析,導致構建 IStructuredModel構建過程異常復雜;如果利用已有的IStrucuturedDocument構建機制,先將特定的內 容解析為IStrucuturedDocument完成語法劃分,再基於高度結構化的IStrucuturedDocument去構建 IStrucuturedModel,那肯定會大大簡化構建過程,某種程度上就可以將構建過程理解為把 IStrucuturedDocument中節點列表轉換為IStrucuturedModel持有的Document對應的節點列表了。 IStructuredModel構建過程大致示意如下:
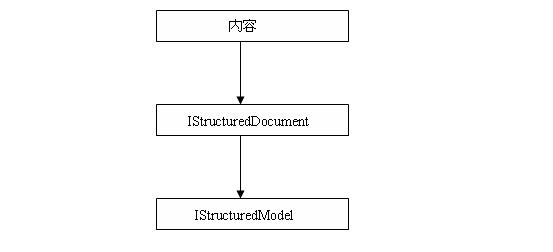
【IStructuredModel:句柄】